Scrapy的下载安装与简单使用
一.什么是Scrapy?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。
所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)
的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
二.安装
Linux:
pip3 install scrapy
Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl(更具情况选择具体版本)
- 注意:必须保证安装成功。安装失败,可以换另一个版本的twisted文件再次进行安装
d. pip3 install pywin32
e. pip3 install scrapy
- 检测环境是否安装成功:
- 终端中:scrapy
![安装成功显示如下图:]

三.基本使用 - 创建一个项目
- scrapy startproject proName
-项目目录下的两个文件表示的含义:- spiders包:爬虫文件夹
- 必须在爬虫文件夹中创建一个爬虫源文件
- settings.py:配置文件
- spiders包:爬虫文件夹
- scrapy startproject proName
- cd proName
- 创建一个爬虫文件(爬虫文件要创建在spiders包中)
- scrapy genspider spiderName www.xxx.com
- 爬虫文件可以使用上述指令创建多个
一个爬虫项目的目录如下所示:
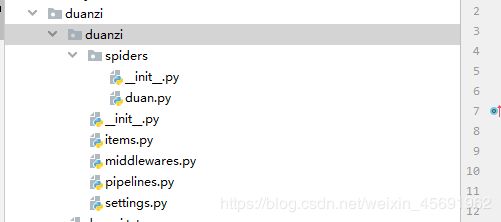
- 编写爬虫文件
- 执行项目
- scrapy crawl spiderName
- 终端中:scrapy
四.爬虫文件的编写
- 定义好了一个类,该类的父类是Spider,Spider是scrapy所有类的父类
- 类中定义好了三个属性和一个方法
- duan.py
# -*- coding: utf-8 -*-
import scrapy
from duanzi.items import DuanziItem
class DuanziSpider(scrapy.Spider):
name = 'duanzi'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://ishuo.cn/xiaozhishi']
- name:爬虫文件的名称
- start_urls:起始url列表
- 作用:可以对列表中的url进行get请求的发送
- allow_demains:允许的域名,注释掉即可。
- parse(self,response):
- 将起始url列表中的url请求成功后,response就是获取的响应对象,
在该方法中负责实现数据解析
- scrapy工程默认是遵从rotbos协议的,需要在配置文件中进行操作:
- 不遵从robots协议
- 指定日志等级
- LOG_LEVEL = 'ERROR'
五.数据解析
duan.py
# 数据解析操作
def parse(self, response):
# 数据解析,段子标题:内容
li_list = response.xpath('//*[@id="list"]/ul/li')
for li in li_list:
# 不是字符串,而是selector对象,提取的字符串数据被存储在该对象中
# content = li.xpath('./div[1]/text()')[0]
# 返回的是selector中存储的字符串数据
content = li.xpath('./div[1]/text()')[0].extract()
# extract_first()将列表中第0个元素进行数据提取
# content = li.xpath('./div[1]/text()').extract_first()
title = li.xpath('./div[2]/a/text()')[0].extract()
# extract()将列表中每一个列表元素表示的selector对象中的字符串取出
tag = li.xpath('./div[2]/span//text()').extract() # 返回的是列表,列表中有多个元素
tag = ''.join(tag) # 将列表转为字符串
print('内容:',content)
print('标题:',title)
print('标签:',tag)
break
- response.xpath()
- 注意:提取标签内容时,返回的不是字符串,而是Selector对象,字符串是存储在该对象中的。
需要调用extract()或者extract_first()将Selector对象中的字符串取出。
六.持久化存储
- 基于终端指令:
- 只可以将parse方法的返回值存储写入到指定后缀的文本文件中。
- 通过指定方式执行工程:
- scrapy crawl duanzi -o data_duanzi.csv
- duan.py
基于终端指令持久化存储
def parse(self, response):
all_data = []
# 数据解析,段子标题:内容
li_list = response.xpath('//*[@id="list"]/ul/li')
for li in li_list:
# 不是字符串,而是selector对象,提取的字符串数据被存储在该对象中
# content = li.xpath('./div[1]/text()')[0]
# 返回的是selector中存储的字符串数据
content = li.xpath('./div[1]/text()')[0].extract()
# extract_first()将列表中第0个元素进行数据提取
content = li.xpath('./div[1]/text()').extract_first()
title = li.xpath('./div[2]/a/text()')[0].extract()
# extract()将列表中每一个列表元素表示的selector对象中的字符串取出
tag = li.xpath('./div[2]/span//text()').extract() # 返回的是列表,列表中有多个元素
tag = ''.join(tag) # 将列表转为字符串
dic = {
'title':title,
'tag':tag,
'content': content,
}
all_data.append(dic)
return all_data # 返回值就是解析到的所有数据
每条数据的title、tag、content封装到dic中,所有的dic组成all_data,即为爬取的所有的数据。
- 基于管道:
- 实现流程:
- 1.在爬虫文件中解析数据
- 2.在Item类中定义相关的属性(解析的数据有几个字段就定义几个属性)
- 3.将在爬虫文件中解析的数据存储封装到Item对象中
- 4.将存储了解析数据的Item对象提交给管道
- 5.在管道文件中接受Item对象,且对其进行任意形式的持久化存储操作
- 6.在配置文件中开启管道
duan.py
# 基于管道的持久化存储
def parse(self, response):
li_list = response.xpath('//*[@id="list"]/ul/li')
for li in li_list:
content = li.xpath('./div[1]/text()').extract_first()
title = li.xpath('./div[2]/a/text()')[0].extract()
tag = li.xpath('./div[2]/span//text()').extract() # 返回的是列表,列表中有多个元素
tag = ''.join(tag) # 将列表转为字符串
# 将解析到的数据存储到item对象
item = DuanziItem()
# item['title']访问item对象中的title属性,
item['title'] = title
item['tag'] = tag
item['content'] = content
# 将item对象提交给管道(pipliine.py中定义好了管道类)
yield item
items.py
import scrapy
class DuanziItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 定义好两个属性,用来存储解析到的两个字段的值
title = scrapy.Field()
tag = scrapy.Field()
content = scrapy.Field()
pipelines.py
class DuanziPipeline(object):
fp = None
# 重写父类的方法,只会在爬虫开始后被执行一次
def open_spider(self,spider):
print('一次')
self.fp = open('./duanzi.txt','w',encoding='utf-8')
# 这方法用来接收爬虫文件提交过来的item对象,(一次只能接受一个item对象)
# 参数item:接收到的item对象
def process_item(self, item, spider):
print('多次')
# 将接收到的item对象写入文件
title = item['title'] # 将item对象中存储的值取出
content = item['content']
self.fp.write(title+'\n:'+content+'\n\n')
return item
# 重写父类的一个方法,只会在爬虫结束前调用一次
def close_spider(self,spider):
print('结束')
self.fp.close()
settings.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'sunPro.pipelines.SunproPipeline': 300,
}
- 如何实现数据的备份
- 指的是将爬取到的一组数据存储到多个不同的载体(文件,mysql,redis)中。
- 持久化存储的操作必须要写在管道文件中
- 一个管道类对应一种形式的持久化存储
- 如果想将数据存储到多个载体中则必须要有多个管道类
- 问题:让两个管道类都接受到item且对其进行持久化存储,爬虫文件提交的item可以同时提交给
两个管道类?
- 爬虫文件提交的item只可以提交个优先级最高的那一个管道类。
- 如何可以让优先级低的管道类也可以获取接受到item呢?
- 可以让优先级高的管道类在process_item中通过return item的形式将item
传递给下一个即将被执行的管道类。
piplines.py
import pymysql
class DuanziPipeline(object):
fp = None
# 重写父类的方法,只会在爬虫开始后被执行一次
def open_spider(self,spider):
print('一次')
self.fp = open('./duanzi.txt','w',encoding='utf-8')
# 这方法用来接收爬虫文件提交过来的item对象,(一次只能接受一个item对象)
# 参数item:接收到的item对象
def process_item(self, item, spider):
print('多次')
# 将接收到的item对象写入文件
title = item['title'] # 将item对象中存储的值取出
content = item['content']
self.fp.write(title+'\n:'+content+'\n\n')
return item
# 重写父类的一个方法,只会在爬虫结束前调用一次
def close_spider(self,spider):
print('结束')
self.fp.close()
# 将数据存储到mysql中一份
class MysqlPileline(object):
conn = None
cusor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='localhost',port=3306,user='root',password='123456',db='spider',charset='utf8')
print(self.conn)
def process_item(self,item,spider):
title = item['title']
content = item['content']
sql = 'insert into duanzi values("%s","%s")'%(title,content)
print(sql)
# 使用游标对象执行sql语句
self.cusor = self.conn.cursor()
try:
self.cusor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cusor.close()
self.conn.close()
settings.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'sunPro.pipelines.SunproPipeline': 300,
'sunPro.pipelines.MysqlPileline': 301,
}
七.手动请求发送实现的全站数据爬取
- 如何通过代码手动对指定的url进行请求发送
- yield scrapy.Request(url,callback):get请求
- 如何手动发起post请求
- yield scrapy.FormRequest(url,formdata,callback)
- 注意:在scrapy中一般不发送post请求
新建一个scrapy项目
# 捕获前五页的数据
class SunSpider(scrapy.Spider):
name = 'sun'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page=']
# 定义一个通用的url模板
url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page=%d'
page = 30 #page=0第一页,page=30第二页
def parse(self, response):
tr_list = response.xpath('//*[@id="morelist"]/div/table[2]//tr/td/table//tr')
for tr in tr_list:
title = tr.xpath('./td[2]/a[2]/text()').extract_first()
status = tr.xpath('./td[3]/span/text()').extract_first()
# 封装到item对象中
item = SunproItem()
item['title'] = title
item['status'] = status
# 提交给管道
yield item
if self.page <= 120: # 结束递归的条件
# 手动请求发送的操作
new_url = format(self.url%self.page)
self.page += 30
# callback参数:请求成功后会调用指定的回调函数进行数据解析
yield scrapy.Request(url=new_url,callback=self.parse) #手动对指定的url进行get请求发送