大数据实时检索场景化解决方案---HBase
HBase简介
• HBase是一个分布式的NoSQL数据库,其特点高可靠、高性能、面向列、可伸缩。
• 适合存储大表数据 ,并且可实时读写大表数据。
• 表结构稀疏。
• 数据底层存储于Hadoop HDFS分布式文件系统。
• 利用ZooKeeper作为协同服务。
• 大表:表的规模可以达到数十亿行以及数百万列,
• 稀疏:对于为空的列,并不占用存储空间
• 列存储,面向列族,无模式。
• KV模型
• 大表:例如网页URL的存储,数十亿的互联网网页url。
• zookeeper:主备选举与监控;管理元数据,root表或mete表。
HBase应用场景
• HBase适合具有如下需求的应用:
• 海量数据 (TB、PB) 。
• 不需要完全拥有传统关系型数据库所具备的ACID特性。
• 高吞吐量。
• 需要在海量数据中实现高效的随机读取。
• 需要很好的性能伸缩能力。
• 能够同时处理结构化和非结构化的数据。
• ACID原则是数据库事务正常执行的四个特性,分别指原子性、一致性、独立性及持久性。
• 事务的原子性(Atomicity):指一个事务要么全部执行,要么不执行。也就是说一个事务不可能只执行了一半就停止了。比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱,不可能划了卡,而钱却没出来.这两步必须同时完成,要么就不完成。
• 事务的一致性(Consistency):指事务的运行并不改变数据库中数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变。
• 独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致。
• 持久性(Durability):事务的持久性是指事务执行成功以后,该事务所对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚。
HBase系统架构
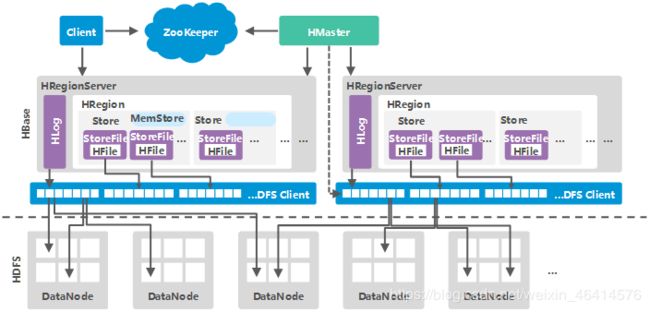
• ZooKeeper为HBase集群中各进程提供分布式协作服务。各RegionServer将自己的信息注册到Zookeeper中,主用Master据此感知各个RegionServer的健康状态。
• Client使用HBase的RPC机制与Master、RegionServer进行通信。Client与Master进行管理类通信,与RegionServer进行数据操作类通信。
• RegionServer负责提供表数据读写等服务,是HBase的数据处理和计算单元。RegionServer一般与HDFS集群的DataNode部署在一起,实现数据的存储功能。
• HMaster,在HA模式下,包含主用Master和备用Master。
• 主用Master:负责HBase中RegionServer的管理,包括表的增删改查;RegionServer的负载均衡,Region分布调整;Region分裂以及分裂后的Region分配;RegionServer失效后的Region迁移等。
• 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
• HDFS为HBase提供高可靠的文件存储服务,HBase的数据全部存储在HDFS中。
• Store:一个Region由一个或多个Store组成,每个Store对应图中的一个Column Family。
• MemStore:一个Store包含一个MemStore,MemStore缓存客户端向Region插入的数据。
• StoreFile:MemStore的数据flush到HDFS后成为StoreFile。
• Hfile:HFile定义了StoreFile在文件系统中的存储格式,它是当前HBase系统中StoreFile的具体实现。
• Hlog:HLog日志保证了当RegionServer故障的情况下用户写入的数据不丢失,RegionServer的多个Region共享一个相同的Hlog。
HBase存储模型
• HBase的底层数据以KeyValue的形式存在,KeyValue具有特定的格式。
• KeyValue中拥有时间戳、类型等关键信息。
• 同一个Key值可以关联多个Value,每一个KeyValue都拥有一个Qualifier标识。
• 即使是Key值相同,Qualifier也相同的多个KeyValue,也可能有多个版本,此时使用时间戳来区分,这就是同一条数据记录的多版本。

• KeyValue具有特定的结构。Key部分被用来快速的检索一条数据记录,Value部分用来存储实际的用户数据信息。
• KeyValue作为承载用户数据的基本单元,需要保存一些对自身的描述信息,例如,时间戳,类型等等。那么势必会有一定的结构化空间开销。
• 支持动态增加列,容易适应数据类型和结构的变化。以块为单元操作数据,列间、表间并无关联关系。
• KeyValue型数据库数据分区方式—按Key值连续范围分区。
• 数据按照RowKey的范围 (按RowKey的字典顺序),划分为一个个的子区间。每一个子区间都是一个分布式存储的基本单元。
HBase缓存机制
• HBase提供2种类型的缓存结构:MemStore和BlockCache。
• MemStore:HBase数据先写入HLog 之中,并同时写入MemStore,待满足一定条件后将MemStore中数据刷到磁盘,能提升HBase的写性能和读性能。
• BlockCache:HBase会将一次文件查找的Block块缓存到Cache中,以便后续同一请求或者相邻数据查找请求,可以直接从内存中获取,避免IO操作。
• 其中MemStore是写缓存,BlockCache是读缓存。
• 一个HRegionServer只有一个BlockCache,在HRegionServer启动的时候完成BlockCache的初始化,常用的BlockCache包括LruBlockCache,以及 CombinedBlockCache(LruBlockCache + BucketCache)。
• LRUBlockCache 是HBase默认的BlockCache实现方案。实际上就是一个ConcurrentHashMap管理BlockKey到Block的映射关系,缓存Block只需要将BlockKey和对应的Block放入该HashMap中,查询缓存就根据BlockKey从HashMap中获取即可。
• LRUBlockCache 分层策略:Block的数据存储在JVM 堆中,由JVM进行管理。它在逻辑上分为三个区:Single-Access、Multi-Access、In-Memory,分别占整个BlockCache的25%、50%、25%。一次随机读中,一个Block块从HDFS中加载出来之后首先放入Single-Access区,后续如果有多次请求访问到这块数据的话,就会将这块数据移到Multi-Access s区。而In-Memory区表示数据可以常驻内存,一般用来存放访问频繁、数据量小的数据,比如元数据,用户也可以在建表的时候通过设置列族属性IN-MEMORY= true将此列族放入In-Memory区。因此设置数据属性InMemory= true需要非常谨慎,确保此列族数据量很小且访问频繁,否则有可能会将hbase.meta元数据挤出内存,严重影响所有业务性能。无论哪个区,系统都会采用严格的Least-Recently-Used算法,当BlockCache总量达到一定阈值之后就会启动淘汰机制,最少使用的Block会被置换出来,为新加载的Block预留空间。
• LRU淘汰算法实现:系统在每次cache block时将BlockKey和Block放入HashMap后都会检查BlockCache总量是否达到阈值,如果达到阈值,就会唤醒淘汰线程对Map中的Block进行淘汰。系统设置三个MinMaxPriorityQueue队列,分别对应上述三个分层,每个队列中的元素按照最近最少被使用排列,系统会优先poll出最近最少使用的元素,将其对应的内存释放。
• CombinedBlockCache:是一个LRUBlockCache和BucketCache的混合体。LRUBlockCache中主要存储Index Block和Bloom Block,而将Data Block存储在BucketCache中。故一次随机读需要先在LRUBlockCache中查到对应的Index Block,然后再到BucketCache查找对应数据块。BucketCache有三种工作模式:heap、offheap、file。heap模式表示这些Bucket是从JVM Heap中申请,offheap模式使用DirectByteBuffer技术实现堆外内存存储管理,而file模式使用类似SSD的高速缓存文件存储数据块。无论在哪一种工作模式,BucketCache都会申请许多带有固定大小标签的Bucket,一种Bucket只是一种指定的BlockSize的数据块,初始化的时候申请14个不同大小的Bucket,而且即使在某一种Bucket空间不足的情况下,系统也会从其他Bucket空间借用内存使用,不会出现内存使用率低下的情况。
• BucketCache内存组织形式:HBase启动时,会在内存申请大量bucket,每一个bucket默认大小是2MB,每一个Bucket都有一个offsetBase属性和size标签,其中offsetBase表示这个bucket在实际物理空间的offset, 故可以根据offsetBase的属性,和block在该bucket的offset确定block实际物理存储地址;size标签表示这个bucket可以存放的block块的大小,比如size 标签是9k, 那么他只能存储8k的block,如果size标签是129k,那么bucket只能存储128k的block;HBase使用BucketAllocator对bucket进行管理, HBase会根据size进行分组,相同size的标签由同一个BucketSizeInfo来管理,如64k的block的由size 标签是65k的BucketSizeInfo来管理, 如128k的block的由size 标签是129k的BucketSizeInfo来管理;默认标签有(4+1)K、(8+1)K、(16+1)K … (48+1)K、(56+1)K、(64+1)K、(96+1)K … (512+1)K,且系统会先从小到大遍历一次所有size标签,为每种size标签分配一个bucket,最后剩余的bucket都分配最大的size标签,默认分配 (512+1)K;bucket size标签,可以动态调整。比如64K的block数目比较多,65K的bucket被用完了以后,其他size标签的完全空闲的bucket可以转换成为65K的bucket,但是至少保留一个该size的bucket。
HBase BloomFilter
• BloomFilter用来优化一些随机读取的场景,即Get场景。它可以被用来快速的判断一条数据在一个大的数据集合中是否存在。
• BloomFilter在判断一个数据是否存在时,拥有一定的误判率。但对于“该条数据不存在”的判断结果是可信的。
• HBase的BloomFilter的相关数据,被保存在HFile中。

• Bloom Filter的数据存在StoreFile的meta中,一旦写入无法更新,因为StoreFile是不可变的。Bloomfilter是一个列族(cf)级别的配置属性,如果你在表中设置了Bloomfilter,那么HBase会在生成StoreFile时包含一份bloomfilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。
• Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。
• Bloom Filter用k个hash function将它hash得到bloom filter中k个bit位,将这k个bit位置1。若这k bits全为1,则此元素在集合中。
• 误判率:在万分之一以下由哈希函数个数k、位数组大小m、数据量n共同确定。
HBase客户端
• HBase提供客户端命令的方式供使用人员对数据库进行各种操作。
• 提供表的增删改查,表快照备份等。

SQL On Hbase
• Apache Phoenix将SQL查询编译为一系列HBase扫描。可以为小型查询提供毫秒级的性能,或者为数千万行提供数秒的性能。
• 其他SQL使用方式还有:Hive、Spark SQL等
• Phoenix SQL支持的部分语法:

• Phoenix:Apache基金的顶级项目,完全使用Java编写,作为HBase内嵌的JDBC驱动,与其他Hadoop产品完美集成,如Spark,Hive,Pig,Flume和Map Reduce。Phoenix查询引擎将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。直接使用HBase API、协同处理器与自定义过滤器实现SQL编译。
• Phoenix在Hadoop中为低延迟应用程序启用OLTP和运营分析。
• Phoenix通过以下方式使我们可以少写代码,并且性能比我们自己写代码更好:
• 将SQL编译成原生的HBase scans。
• 确定scan关键字的最佳开始和结束
• 让scan并行执行
• Phoenix SQL的两种使用方式:命令行和JDBC连接
• 其他的SQL使用方式还有:Impala
• HiveSQL(建表时指定HBase数据):
CREATE TABLE lwb_test1(key string,xm string,nl int)
STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’
WITH SERDEPROPERTIES (“hbase.columns.mapping” = “:key,data:xm,data:nl”)
TBLPROPERTIES (“hbase.table.name” = “tbtest1”);
• 进入spark-sql,使用如下语句建表:
CREATE EXTERNAL TABLE tbtest1 (rowkey string,
f1 map,
f2 map,
f3 map)
STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’
WITH SERDEPROPERTIES (“hbase.columns.mapping” = “:key,f1:,f2:,f3:”)
TBLPROPERTIES (“hbase.table.name” = “tbtest1”);
API使用 - 创建删除表
• 通过org.apache.hadoop.hbase.client.Admin实例的createTable方法来创建表,并指定表名、列族名。

• 通过org.apache.hadoop.hbase.client.Admin实例的deleteTable方法来删除表。

• 创建表有两种方式(强烈建议采用预分Region建表方式):
• 快速建表,即创建表后整张表只有一个Region,随着数据量的增加会自动分裂成多个Region。
• 预分Region建表,即创建表时预先分配多个Region,此种方法建表可以提高写入大量数据初期的数据写入速度。
• Connection的获取方法:
//创建配置对象
Configuration conf = HBaseConfiguration.create();
//zkServer指zk的地址
conf.set(“hbase.zookeeper.quorum”, zkServer);
//通过连接池获取连接
Connection conn = ConnectionFactory.createConnection(conf);
API使用 - 插入删除数据
• HBase通过Table实例的put方法来插入数据,可以是一行数据也可以是数据集。

• HBase通过Table实例的delete方法来Delete数据,可以是一行数据也可以是数据集。

• 插入数据代码含义:
• tableName是字符串形式的表名称,用Connection实例的getTable方法获取Table实例
• Put实例传入的参数是RowKey的字节形式
• Put实例addColumn方法传入的列族,列,value都是字节形式
API使用 - Get 读取数据
• 要从表中读取一条数据,首先需要实例化该表对应的Table实例,然后创建一个Get对象。也可以为Get对象设定参数值,如列族的名称和列的名称。查询到的行数据存储在Result对象中,Result中可以存储多个Cell。

• HBase数据查询操作,get命令
• 代码涵义如下:
• 将列族,列,rowkey全部转成字节形式
• Connection实例的getTable获取Table实例,传入参数为表名称
• 用rowkey 获取get示例
• Get实例添加列族和列
• Table实例的get方法传入get实例获取查询结果result实例,用循环依据表结构解析result实例
API使用 - Scan 读取数据
• 要从表中读取数据,首先需要实例化该表对应的Table实例,然后创建一个Scan对象,并针对查询条件设置Scan对象的参数值,为了提高查询效率,最好指定StartRow和StopRow。查询结果的多行数据保存在ResultScanner对象中,每行数据以Result对象形式存储,Result中存储了多个Cell。

API使用 - 过滤器 Filter
• HBase Filter主要在Scan和Get过程中进行数据过滤,通过设置一些过滤条件来实现,如设置RowKey,列名或者列值的过滤条件。

• HBase数据查询过滤器Filter介绍,如何过滤数据。
• 比较器:
• RegexStringComparator,支持正则表达式的值比较
• SubStringComparator,用于监测一个子串是否存在于值中,并且不区分大小写
• BinaryPrefixComparator前缀二进制比较器。与二进制比较器不同的是,只比较前缀是否相同
• BinaryComparator二进制比较器,用于按字典顺序比较 Byte 数据值。
• 列值过滤器:
• SingleColumnValueFilter SingleColumnValueFilter 用于测试值的情况(相等,不等,范围 、、、)
• SingleColumnValueExcludeFilter跟 SingleColumnValueFilter 功能一样,只是不查询出该列的值。
• FamilyFilter用于过滤列族(通常在 Scan 过程中通过设定某些列族来实现该功能,而不是直接使用该过滤器)。
• QualifierFilter用于列名(Qualifier)过滤。
• ColumnPrefixFilter 用于列名(Qualifier)前缀过滤,即包含某个前缀的所有列名。
• 行键过滤器:
• RowFilter :行键过滤器,一般来讲,执行 Scan 使用 startRow/stopRow 方式比较好,而 RowFilter 过滤器也可以完成对某一行的过滤。
• ColumnPrefixFilter :用于列名(Qualifier)前缀过滤,即包含某个前缀的所有列名。
• 功能过滤器:PageFilter用于按行分页。
HBase性能优化 - 表设计
• Region:区域。预先创建多个Region,当数据写入HBase时,会按照RowKey对应Region分区情况,在集群内做数据的负载均衡。
• RowKey:行键。满足实际业务需求情况下,长度越小越好,考虑散列性(连续的Row Key易导致负载不均衡)。散列存储可采用取反或Hash来实现。
• Column Family:列簇 。一张表里不要定义太多的列簇,因为某个列簇在flush的时候,它邻近的列簇也会因关联效应被触发flush,最终导致系统产生更多的I/O。
• Max Version:最大版本数量。如果只需要保存最新版本的数据,那么可以设置最大版本数为1。
• Time To Live:数据存活时间(秒)。例如只需要存储最近两天的数据,那么可以设置存活时间为2 * 24 * 60 * 60。
• 预分Region:创建HBase表的时候会自动创建一个region分区,直到这个region足够大了才进行切分,当导入数据的时候,所有的HBase客户端都向这一个region写数据。
• RowKey:可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组,一般设计成定长的。RowKey是按照字典序存储,因此,设计RowKey时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
• 取反:将指连续的id等,倒排作为HBase RowKey设计。如 10000,10001,10002 --> 00001,10001,20001
• Hash:连续的id可根据集群节点数由Hash计算出结果,再将hash值放到id前面拼接成RowKey。如 id --> 0-id1 , 3-id2
• Max Version:HColumnDescriptor.setMaxVersions(int maxVersions)
• Time To Live:setTimeToLive(2 * 24 * 60 * 60)
HBase性能优化 - 写表操作
• Table参数
• Write Buffer:实际写入数据量的多少来设置Table客户端的写buffer大小。
• WAL Flag:对于相对不太重要的数据,(谨慎使用)放弃写WAL日志,从而提高数据写入的性能。
• 批量写:通过调用Table实例的put(List)批量写入多行记录,只需一次网络I/O开销,可以明显的提升写性能。
• 多Table并发写:创建多个Table实例。new Table(conf, table_log_name);
• Auto Flush :BufferedMutator替换了HTable的setAutoFlush(false)的作用。
• Write Buffer:调用Table.setWriteBufferSize(writeBufferSize)来设置,新设置的buffer小于当前写buffer中的数据时,buffer将会被flush到服务端。writeBufferSize的单位是byte字节数。
BufferedMutatorParams b = new BufferedMutatorParams(conn.getTable("")).writeBufferSize(“1000”);
conn.getBufferedMutator(b);
• WAL Flag(即HLog):Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)函数,这RegionServer宕机后的数据无法恢复。
• 批量写:通过调用Table.put(List) 而非Table.put(Put)方法可以将记录写入HBase,批量写入在数据实时性要求高,网络传输RTT高的情景下可能带来明显的性能提升。
HBase性能优化 - 读表操作
• Scanner Caching配置:
• Scan时指定需要的列簇或者列,可以减少网络传输数据量。
• 在HBase的conf配置扫描器缓存;
• 通过调用Scan实例的setCaching(int caching)进行配置;
• 批量读:通过调用Table实例的get(List)批量读取多行记录,只需一次网络I/O开销,可以明显的提升读性能。