【深度学习】DAY 3 - Python入门(三)Python结构数据类型
深度学习DAY 3 - Python入门(三)
- Chapter 1 Python入门
- 1.3 Python语法基础
- 1.3.4 Python结构数据类型
- (1)列表(List)
- 1)List 添加
- 2)List 移除
- 3)List 索引
- 4)List 排序
- 5)多维列表 Multi-dimension List
- (2)元组(Tuple)
- (3)字典(dictionary)
- 1)基本用法
- 2)操作函数
- (4)集合(set)
- 1)基本用法
- 2)操作函数
- (5)序列操作
Chapter 1 Python入门
1.3 Python语法基础
1.3.4 Python结构数据类型
(1)列表(List)
列表由一系列按特定顺序排列的元素组成。列表根据索引,按照0, 1, 2, . . .的顺序存储值。在Python中, 用方括号[ ] 来表示列表, 并用逗号来分隔其中的元素。
>>> list() #创建空列表
>>> [ ] #创建空列表
>>> a = [1, 2, 3, 4, 5] # 生成列表
>>> print(a) # 输出列表的内容
>>> len(a) # 获取列表的长度
>>> a[0] # 访问第一个元素的值,索引由0开始
>>> a[4] = 99 # 赋值
1)List 添加
- list.append(x) #列表尾部追加值为x的项
>>> a = [1,2,3,4,1,1,-1]
>>> a.append(0) # 在a的最后面追加一个0
>>> print(a)
> [1, 2, 3, 4, 1, 1, -1, 0]
- list.insert(index,x) #列表指定索引后插入值为x的项
>>> a = [1,2,3,4,1,1,-1]
>>> a.insert(1,0) # 在位置1处添加0
>>> print(a)
> [1, 0, 2, 3, 4, 1, 1, -1]
2)List 移除
- list.remove(x) #列表删除第一个出现值为x的项
>>> a = [1,2,3,4,1,1,-1]
>>>a.remove(2) # 删除列表中第一个出现的值为2的项
>>>print(a)
> [1, 3, 4, 1, 1, -1]
3)List 索引
- 显示特定位
>>>a = [1,2,3,4,1,1,-1]
print(a[0]) # 显示列表a的第0位的值
> 1
>>>print(a[-1]) # 显示列表a的最末位的值
> -1
Python提供slicing切片标记,可访问子列表
>>> a[0:2] # 获取索引为0到2(不包括2!)的元素
>[1, 2]
>>> a[1:] # 获取从索引为1的元素到最后一个元素
>[2, 3, 4, 99]
>>> a[:3] # 获取从第一个元素到索引为3**(不包括3!)**的元素
>[1, 2, 3]
>>> a[:-1] # 获取从第一个元素到最后一个元素的前一个元素之间的元素
>[1, 2, 3, 4]
>>> a[:-2] # 获取从第一个元素到最后一个元素的前二个元素之间的元素
>[1, 2, 3]
- list.index()打印某个值的索引
>>>a = [1,2,3,4,1,1,-1]
>>>print(a.index(2)) # 显示列表a中第一次出现的值为2的项的索引
> 1
- list.count()统计列表中某个值出现的次数
>>>a = [4,1,2,3,4,1,1,-1]
>>>print(a.count(-1))
> 1
4)List 排序
- list.sort() 从小到大排序
>>>a = [4,1,2,3,4,1,1,-1]
>>>a.sort() # 默认从小到大排序
>>>print(a)
> [-1, 1, 1, 1, 2, 3, 4, 4]
- list.sort(reverse=True) 从大到小排序
>>>a.sort(reverse=True) # 从大到小排序
>>>print(a)
> [4, 4, 3, 2, 1, 1, 1, -1]
> 1
- 常见的列表操作函数
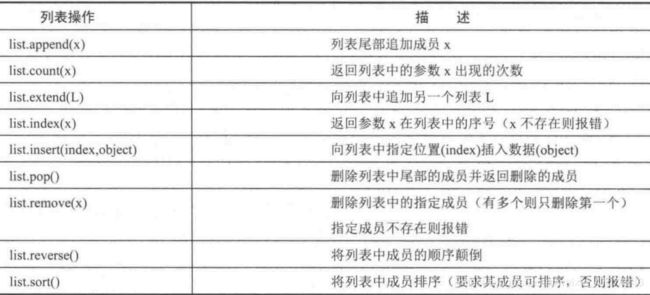
5)多维列表 Multi-dimension List
一维的List是线性的List,多维List是一个平面的List,相当于矩阵
>>>a = [1,2,3,4,5] # 一行五列
>>> multi_dim_a = [[1,2,3],
[2,3,4],
[3,4,5]] # 三行三列
- 根据索引检索
>>>print(a[1])
>2
>>>print(multi_dim_a[0][1])
>2
(2)元组(Tuple)
用小括号、或者无括号来表述,是一连串有顺序的数字。特殊的列表,建立后不能改变数据项。
>>> () #创建空元组
>>> tuple() #创建空元组
>>> (1,) #创建只有一个元素的元组
>>> print(a) # 输出列表的内容
>>> len(a) # 获取列表的长度
>>> a[0] # 访问第一个元素的值,索引由0开始
>>> a[4] = 99 # 赋值
list和tuple的元素均可以逐个迭代、输出、运用和定位
- 逐个输出
>>> for content in a_list:
print(content)
>>> for content_tuple in a_tuple:
print(content_tuple)
- 带索引依次输出
>>> for index in range(len(a_list)):
print("index = ", index, ", number in list = ", a_list[index])
>>> for index in range(len(a_tuple)):
print("index = ", index, ", number in tuple = ", a_tuple[index])
(3)字典(dictionary)
字典以键值对的形式存储数据。List是有顺序地输出输入,字典的存档形式则无需顺序。
列表采取的是遍历搜索,但是字典直接计算存放位置,就像查字典一样,速度更快。
但是字典需要占用大量内存,产生浪费。
- 结构
dictionary ={key:value}
1)基本用法
- dictionary ={key:value} 生成字典
>>> me = {'height':180}
- dictionary[key] 访问元素
>>> me['height']
180
- dictionary[key]=value添加元素
>>> me['weight'] = 70
>>> print(me)
{'height': 180, 'weight': 70}
- key或者value可以是数字或字符串
>>> d = {1:'a','c':'b'}
- del dict[key] 删除键值对
>>> del me['height']
- 可嵌套列表、字典和函数
>>> d4 = {'apple':[1,2,3], 'pear':{1:3, 3:'a'}, 'orange':func}
>>> print(d4['pear'][3])
> a
- 一个key只对应一个value,多次赋值会更新。
>>> me['weight'] = 90
>>> me['weight']
90
>>> me['weight'] = 80
>>> me['weight']
80
- 若key不存在,会报错。为避免错误,可以通过
in判断键是否存在
>>> d['age']
Traceback (most recent call last):
File "" , line 1, in <module>
KeyError: 'age'
>>> 'age' in me
False
2)操作函数
- 常见的字典操作函数
 * dict.get() 返回键值
* dict.get() 返回键值
与直接访问类似
语法:
dict.get(key, default=None)
key – 字典中要查找的键。
default – 如果指定键的值不存在时,返回该默认值。
除了用in方法,dict.get()也可以判断键是否存在,不存在返回None,交互环境不显示结果。
>>>me,get('height')
180
- dict.pop() 删除key
>>>me.pop('weight')
80
>>>print(me)
{'height': 180}
dict的key必须是不可变对象。因为需要根据key计算value(Hash算法)。字符串、整数等可作为键,列表就不能作为键。
(4)集合(set)
set() 的特点是会去除重复项,输出结果无序。可以理解成集合的元素具有唯一性。
1)基本用法
- set 序列
>>> s = set(['python', 'python2', 'python3','python'])
>>> for item in s:
> print(item)
输出 python, python3, python2 。
- set 字符串
sentence = 'Welcome Back to This Tutorial'
print(set(sentence))
输出 {‘l’, ‘m’, ‘a’, ‘c’, ‘t’, ‘r’, ‘s’, ’ ', ‘o’, ‘W’, ‘T’, ‘B’, ‘i’, ‘e’, ‘u’, ‘h’, ‘k’}
- set 集合相加
两者要为同个数据类型
print(set(char_list+ list(sentence)))
输出 {‘l’, ‘m’, ‘a’, ‘c’, ‘t’, ‘r’, ‘s’, ’ ', ‘d’, ‘o’, ‘W’, ‘T’, ‘B’, ‘i’, ‘e’, ‘k’, ‘h’, ‘u’, ‘b’}
- set 交集
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
- set 并集
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 | s2
{1, 2, 3, 4}
2)操作函数
- set.add() 添加元素
只能一个个元素加,不能加列表等。重复元素不累加。
unique_char.add('x')
print(unique_char)
输出 {‘x’, ‘b’, ‘d’, ‘c’, ‘a’}
- set.remove()清除元素
unique_char.remove('x')
print(unique_char)
输出{‘b’, ‘d’, ‘c’, ‘a’}
但是如果集合没有该元素,使用set.remove(),系统会报错
- set.discard()清除元素
如果集合没有该元素,使用set.discard(),系统就不会报错
同理:
unique_char.discard('d')
print(unique_char)
输出{‘b’, ‘c’, ‘a’}
- set.clear() 清除集合所有元素
unique_char.clear()
print(unique_char)
输出 set()
- set.difference()寻找差集
set1 = set(['x', 'b', 'd', 'c', 'a'])
set2 = set(['a','e','i'])
print(set1.difference(set2))
输出{‘d’,‘b’,‘x’,‘c’}
- set.intersection()寻找交集
print(set1.intersection(set2))
输出{‘a’}
(5)序列操作
序列表示索引为非负整数的有序对象的集合,包括字符串、列表和元组。序列切片操作已在列表中介绍。
序列常用操作函数:
 Python学习的内容参考
Python学习的内容参考
《Python编程:从入门到实践》-[美] Eric Matthes
《21天学通PYTHON》
莫烦Python
廖雪峰的Python教程
等