莫烦pytorch学习之问题记录与总结
目录
一、三分类问题
二、创建网络结构部分,还有另一种形式,如下:
三、pytorch中save_model和load_model:
四、batch批量数据读取
五、pytorch测试SGD、Momentum、RMSprop和Adam的性能
六、MNIST数据的批显示
一、三分类问题
原文:https://morvanzhou.github.io/tutorials/machine-learning/torch/3-03-fast-nn/
__author__ = "lingjun"
# E-mail: [email protected]
# welcome to attention:小白CV
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pylab as plt
import torch.nn as nn
###########################
# input_data
########################
n_data=torch.ones(100,2) # 100行2列全是1
x0=torch.normal(5*n_data,1) # 100行2列全是2;torch.normal返回一个张量,张量里面的随机数是从相互独立的,围绕2的正态分布中随机生成的
y0=torch.zeros(100) # label=0
x1=torch.normal(-5*n_data,1)
y1=torch.ones(100) # label=1
x2=torch.normal(0*n_data,1)
y2=y1*2
x=torch.cat((x0,x1,x2),0).type(torch.FloatTensor) # FloatTensor=32-bit floating input data,按维数0(行)拼接
y=torch.cat((y0,y1,y2),).type(torch.LongTensor) # LongTensot=64-bit integer input label
###################
#forward函数的输入与输出都是Variable,只有Variable才具有自动求导功能
#Tensor是没有的,所以在输入时,需要把Tensor使用Variable函数转化为Variable形式
###################
x,y=Variable(x),Variable(y)
'''
x.data.numpy()[:,0],取x tensor中第0个的所有数据,组在一起
x.data.numpy()[:,1],取x tensor中第1个的所有数据,组在一起
'''
print(x)
# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
# plt.show()
class Net(nn.Module):
def __init__(self,n_features,n_hidden,n_output):
super(Net,self).__init__()
# 定义网络有哪些层
self.layer1=torch.nn.Linear(n_features,n_hidden)
self.layer2=torch.nn.Linear(n_hidden,n_output)
#定义层的具体形式
def forward(self,input):
out=self.layer1(input)
out=F.relu(out)
out=self.layer2(out)
return out
net=Net(2,10,3) # input_data=x0 or x1 output_label=0 or 1
print(net)
# 可视化,实时打印
plt.ion()
plt.show()
optimizer=torch.optim.SGD(net.parameters(), lr=0.02)
loss_func=torch.nn.CrossEntropyLoss() # MSELoss用于回归问题 CrossEntropyLoss用于(多)分类
for t in range(500):
out = net(x)
loss=loss_func(out, y) # out=[-2,-0.12,20] F.softmax(out) [0.1,0.2,0.7]
# 优化步骤
optimizer.zero_grad() # 每次循环,梯度都先设为0
loss.backward() # 反向回归
optimizer.step() # 逐step优化
if t % 2 == 0:
plt.cla()
# 过了一道 softmax 的激励函数后的最大概率才是预测值
prediction = torch.max(F.softmax(out), 1)[1] # 索引为1的为最大值的位置,索引为0的为最大值,prediction输出为最大值位置
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / 300. # 预测中有多少和真实值一样
plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.2)
'''
#如果在脚本中使用ion()命令开启了交互模式,没有使用ioff()关闭的话,则图像会一闪而过,
#并不会常留,要想防止这种情况,需要在plt.show()之前加上ioff()命令。
'''
plt.ioff()
plt.show()注意:
标签y=0 or 1,并不是one-hot形式
forward函数的输入与输出都是Variable,只有Variable才具有自动求导功能,Tensor是没有的。所以在输入时,需要把Tensor使用Variable函数转化为Variable形式
Variable的属性有三个:https://blog.csdn.net/qq_36556893/article/details/86490458
- data:Variable里Tensor变量的数值
- grad:Variable反向传播的梯度
- grad_fn:得到Variable的操作
import torch
#创建Variable
a = torch.autograd.Variable()
print(a)
b = torch.autograd.Variable(torch.Tensor([[1, 2], [3, 4],[5, 6], [7, 8]]))
print(b)
print(b.data)
print(b.grad)
print(b.grad_fn)
二、创建网络结构部分,还有另一种形式,如下:
###########################
#net method 1
###########################
class Net(torch.nn.Module):
def __init__(self,n_features,n_hidden,n_output):
super(Net,self).__init__()
#定义网络有哪些层
self.hidden=torch.nn.Linear(n_features,n_hidden)
self.predict=torch.nn.Linear(n_hidden,n_output)
#定义层的具体形式
def forward(self,x):
x=F.relu(self.hidden(x))
y=self.predict(x)
return y
net1=Net(2,10,2) #input_data=x0 or x1 output_label=0 or 1
print(net1)
###########################
#net method 2
###########################
net2=torch.nn.Sequential(
torch.nn.Linear(2,10), # one layer
torch.nn.ReLU(),
torch.nn.Linear(10,2), # two layer
)
print(net2)
三、pytorch中save_model和load_model:
import torch
import matplotlib.pylab as plt
#torch.manual_seed(1) #设定生成随机数的种子
x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
y=x.pow(2)+0.2*torch.rand(x.size())
#x,y=Variable(x,requires_grad=False),Variable(y,requires_grad=False)
def save():
net1= torch.nn.Sequential(
torch.nn.Linear(1, 10), # one layer
torch.nn.ReLU(),
torch.nn.Linear(10, 1), # two layer
)
optimizer=torch.optim.SGD(net1.parameters(),lr=0.5)
loss_func=torch.nn.MSELoss()
for t in range(100):
prediction = net1(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save(net1,'net.pkl') # entir net
torch.save(net1.state_dict(),'net_params.pkl') # parameters
# plt result
plt.figure(1, figsize=(10, 3))
plt.subplot(131)
plt.title('Net1')
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(),'r-',lw=5)
def restore_net():
net2=torch.load('net.pkl')
prediction=net2(x)
# plt result
plt.subplot(132)
plt.title('Net2')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
def restire_params():
net3=torch.nn.Sequential(
torch.nn.Linear(1, 10), # one layer
torch.nn.ReLU(),
torch.nn.Linear(10, 1), # two layer
)
net3.load_state_dict(torch.load('net_params.pkl'))
prediction=net3(x)
# plt result
plt.subplot(133)
plt.title('Net3')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.show()
save()
restore_net()
restire_params()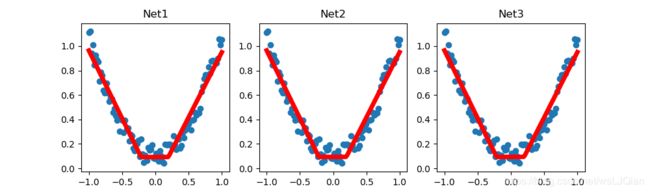
四、batch批量数据读取
import torch
import torch.utils.data as Data
#torch.manual_seed(1) # reproducible
BATCH_SIZE = 8 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # x data (torch tensor)
y = torch.linspace(10, 1, 10) # y data (torch tensor)
# 先转换成 torch 能识别的 Dataset
torch_dataset = Data.TensorDataset(x, y)
# 把 dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
# num_workers=2, # 多线程来读数据
)
for epoch in range(3): # 训练所有!整套!数据 3 次
for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习
# 假设这里就是你训练的地方...
# 打出来一些数据
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
发现:
1.torch.manual_seed(1) 生成随机数,反倒随机生成的batch比较的固定
2.window 下,num_workers无法使用多线程,需要注释掉这里
3.新版形式:torch_dataset = Data.TensorDataset(x, y)
五、pytorch测试SGD、Momentum、RMSprop和Adam的性能
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pylab as plt
LR=0.01
BATCH_SIZE=32
EPOCH=12
x=torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y=x.pow(2)+0.2*torch.rand(x.size())
# plt.scatter(x.numpy(),y.numpy())
# plt.show()
torch_dataset=Data.TensorDataset(x,y)
loader=Data.DataLoader(dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
)
###########################
#net method 1
###########################
class Net(torch.nn.Module):
def __init__(self,n_features,n_hidden,n_output):
super(Net,self).__init__()
#定义网络有哪些层
self.hidden=torch.nn.Linear(n_features,n_hidden)
self.predict=torch.nn.Linear(n_hidden,n_output)
#定义层的具体形式
def forward(self,x):
x=F.relu(self.hidden(x))
y=self.predict(x)
return y
net_SGD=Net(1,20,1)
net_Momentum=Net(1,20,1)
net_RMSprop=Net(1,20,1)
net_Adam=Net(1,20,1)
nets=[net_SGD,net_Momentum,net_RMSprop,net_Adam]
opt_SGD=torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Monentum=torch.optim.SGD(net_Momentum.parameters(), lr=LR,momentum=0.8)
opt_RMSprop=torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR,alpha=0.9)
opt_Adam=torch.optim.Adam(net_Adam.parameters(), lr=LR,betas=(0.9,0.99))
optimizers=[opt_SGD,opt_Monentum,opt_RMSprop,opt_Adam]
loss_func=torch.nn.MSELoss()
losses_his=[[],[],[],[]]
for epoch in range(EPOCH):
print(epoch)
for step,(batch_x,batch_y) in enumerate(loader):
b_x,b_y=Variable(batch_x),Variable(batch_y)
for net,opt,l_his in zip(nets,optimizers,losses_his):
output=net(b_x)
loss=loss_func(output,b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.item())
labels=['SGD','Momentum','RMSprop','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0,0.2))
plt.show()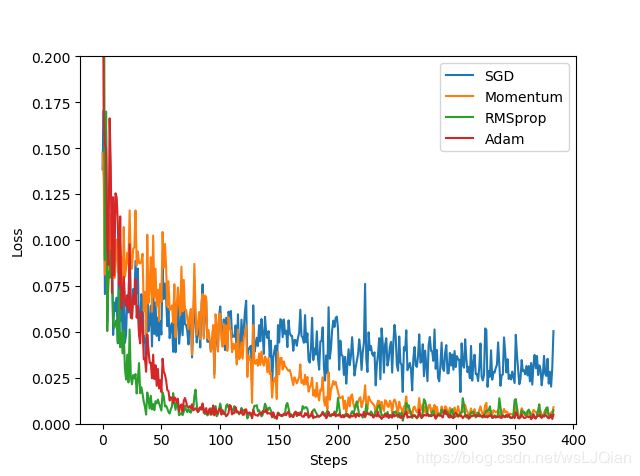
莫凡的原地址:https://morvanzhou.github.io/tutorials/machine-learning/torch/3-06-optimizer/
报错:IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
修改:将loss.data[0] 改为loss.item()
六、MNIST数据的批显示
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
import matplotlib.pylab as plt
import numpy as np
EPOCH=1
BATCH_SIZE=50
LR=0.001
DOWNLOAD_MNIST=True
batch_size = 20
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor(),
download=DOWNLOAD_MNIST,
)
# Loading the Data
train_loader = Data.DataLoader(train_data, batch_size=batch_size)
import matplotlib.pyplot as plt
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
# Peeking into dataset
fig = plt.figure(figsize=(25, 4))
for image in np.arange(20):
ax = fig.add_subplot(2, 20/2, image+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(images[image]), cmap='gray')
ax.set_title(str(labels[image].item()))
plt.show()
