linux NUMA技术
1. 概述
NUMA(Non-Uniform Memory Access Architecture)即非一致性内存访问技术。
NUMA系统有多个Node通过高速互连的网络联系起来的系统。而Node则是由一组cpu
和本地内存组成。不同的Node有不同的物理内存,由于Node访问本地内存和访问其它节点
的内存的速度是不一致的,为了解决非一致性访问内存对性能的影响,有一些工具可以使用。
包括 numactl,autonuma, HPE-AIX等。
2. Node/zone/page之间的关系
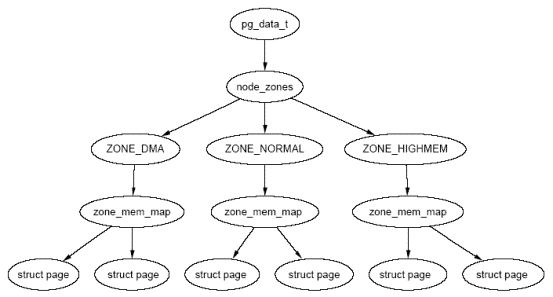
注1: linux用 pg_data_t结构来描述一个Node。 一个Node的内存由多个 zone组成。zone的类型主要有ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。ZONE_DMA位于低端的内存空间,用于某些旧的ISA设备。ZONE_NORMAL的内存直接映射到Linux内核线性地址空间的高端部分,许多内核操作只能在ZONE_NORMAL中进行。例如,在X86中,zone的物理地址如下:
| 类型 | 地址范围 |
|---|---|
| ZONE_DMA | 前16MB内存 |
| ZONE_NORMAL | 16MB - 896MB |
| ZONE_HIGHMEM | 896 MB以上 |
Zone是用struct zone_t描述的,它跟踪页框使用、空闲区域和锁等信息
| 域 | 说明 |
|---|---|
| Lock | 旋转锁,用于保护该zone |
| free_pages | 该zone空闲页总数 |
| pages_min, pages_low, pages_high |
Zone的阈值 |
| need_balance | 该标志告诉kswapd需要对该zone的页进行交换 |
| Free_area | 空闲区域的位图,用于buddy分配器 |
| wait_table | 等待释放该页进程的队列散列表,这对wait_on_page()和unlock_page()是非常重要的。当进程都在一条队列上等待时,将引起进程的抖动 |
| zone_mem_map | 全局mem_map中该zone所引用的第一页 |
| zone_start_paddr | 含义与node_start_paddr类似 |
| zone_start_mapnr | 含义与node_start_mapnr类似 |
| Name | 该zone的名字。如,“DMA”,“Normal”或“HighMem” |
| Size | Zone的大小,以页为单位 |
3. NUMA 相关信息查看工具
1) 查看是否支持NUMA
# dmesg | grep -i NUMA
[ 0.000000] NUMA: Initialized distance table, cnt=2
[ 0.000000] NUMA: Node 0 [mem 0x00000000-0x7fffffff] + [mem 0x100000000-0x107fffffff] -> [mem 0x00000000-0x107fffffff]
[ 0.000000] Enabling automatic NUMA balancing. Configure with numa_balancing= or the kernel.numa_balancing sysctl
[ 1.082448] pci_bus 0000:00: on NUMA node 0
[ 1.084608] pci_bus 0000:7f: on NUMA node 0
[ 1.085942] pci_bus 0000:80: on NUMA node 1
[ 1.088235] pci_bus 0000:ff: on NUMA node 1
[ 0.000000] NUMA: Initialized distance table, cnt=2
[ 0.000000] NUMA: Node 0 [mem 0x00000000-0x7fffffff] + [mem 0x100000000-0x107fffffff] -> [mem 0x00000000-0x107fffffff]
[ 0.000000] Enabling automatic NUMA balancing. Configure with numa_balancing= or the kernel.numa_balancing sysctl
[ 1.082448] pci_bus 0000:00: on NUMA node 0
[ 1.084608] pci_bus 0000:7f: on NUMA node 0
[ 1.085942] pci_bus 0000:80: on NUMA node 1
[ 1.088235] pci_bus 0000:ff: on NUMA node 1
2) 查看numa的状态 numastat
# numastat
node0 node1
numa_hit 15911737 17595326 # numa_hit是打算在该节点上分配内存,最后从这个节点分配的次数;
numa_miss 0 0 # num_miss是打算在该节点分配内存,最后却从其他节点分配的次数;;
numa_foreign 0 0 # num_foregin是打算在其他节点分配内存,最后却从这个节点分配的次数;
interleave_hit 36706 36904 # interleave_hit是采用interleave策略最后从该节点分配的次数;
local_node 15903586 17527159 # local_node该节点上的进程在该节点上分配的次数
other_node 8151 68167 # other_node是其他节点进程在该节点上分配的次数
node0 node1
numa_hit 15911737 17595326 # numa_hit是打算在该节点上分配内存,最后从这个节点分配的次数;
numa_miss 0 0 # num_miss是打算在该节点分配内存,最后却从其他节点分配的次数;;
numa_foreign 0 0 # num_foregin是打算在其他节点分配内存,最后却从这个节点分配的次数;
interleave_hit 36706 36904 # interleave_hit是采用interleave策略最后从该节点分配的次数;
local_node 15903586 17527159 # local_node该节点上的进程在该节点上分配的次数
other_node 8151 68167 # other_node是其他节点进程在该节点上分配的次数
3) 查看各个Node的cpu信息 lscpu
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Model name: Intel(R) Xeon(R) CPU E5-2660 v2 @ 2.20GHz
Stepping: 4
CPU MHz: 2118.617
BogoMIPS: 4405.31
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 25600K
NUMA node0 CPU(s): 0-9,20-29 *
NUMA node1 CPU(s): 10-19,30-39
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Model name: Intel(R) Xeon(R) CPU E5-2660 v2 @ 2.20GHz
Stepping: 4
CPU MHz: 2118.617
BogoMIPS: 4405.31
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 25600K
NUMA node0 CPU(s): 0-9,20-29 *
NUMA node1 CPU(s): 10-19,30-39
4 测试(访问不同节点的内存的IO)
1) write 测试
# numactl --cpubind=0 --membind=0 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.823497 s, 1.3 GB/s
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.823497 s, 1.3 GB/s
# numactl --cpubind=0 --membind=1 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.936182 s, 1.1 GB/s
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.936182 s, 1.1 GB/s
明显访问同一节点的内存速度比访问不同节点内存的速度快。
2) read 测试
# numactl --cpubind=0 --membind=0 dd if=/dev/shm/A of=/dev/null bs=1K count=1024K
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.09543 s, 980 MB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.09543 s, 980 MB/s
# numactl --cpubind=0 --membind=1 dd if=/dev/shm/A of=/dev/null bs=1K count=1024K
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.11862 s, 960 MB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.11862 s, 960 MB/s
结论和write 相同。但是差距比较小。
5. 参考资料
1) http://www.ibm.com/developerworks/cn/linux/l-numa/
2) http://blog.csdn.net/jollyjumper/article/details/17168175