开发一个智能问答机器人(优化篇)
上一篇介绍了整个问答机器人的技术架构和特定,本篇着重说下

如何让机器人(看起来)更智能
输入联想
使用jquery.autosuggest.js实现的输入联想,在输入2个字后,在5000个问答中基于全文检索,检索10条记录,供用户选择。
猜你想问
Chatterbot中也有阈值的概念,例如匹配度低于0.2,可定义为无法回答,但可以额外增加一个阈值,如0.5
当匹配度0~0.2回复无法回答
当匹配度0.2~0.5 回复我猜您想问“XXX”
当匹配度0.5~1回复匹配问题“XXX”
上下文变化
意图规则JSON数据格式,prompts为缺失该参数是的返回值,我们可以多设置几个,再用随机数获取,这样每次与用户交互的问题都是同样含义的不同问法,也有助于消除歧义。
{
"rule": [{
"intent": "weather",
"entities": [
{"name":"city","type":"city","required":"true","prompts":["请问查询哪里的天气","想查询哪个城市的天气"]},
{"name":"date","type":"date","required":"false","prompts":[]}
]
},
{
"intent": "bookhotel",
"entities": [
{"name":"city","type":"city","required":"true","prompts":["请问预订哪里","想预订哪个城市"]},
{"name":"checkindata","type":"date","required":"true","prompts":["请问何时入住","预订酒店的时间"]},
{"name":"checkoutdata","type":"date","required":"false","prompts":[]}
]
},
{
"intent": "bookticket",
"entities": [
{"name":"fromcity","type":"city","required":"true","prompts":["请提供出发城市","从哪起飞"]},
{"name":"tocity","type":"city","required":"true","prompts":["请提供到达城市","到哪落地"]},
{"name":"date","type":"date","required":"true","prompts":["请问预订机票的时间","想预订哪天的机票"]}
]
}
]
}
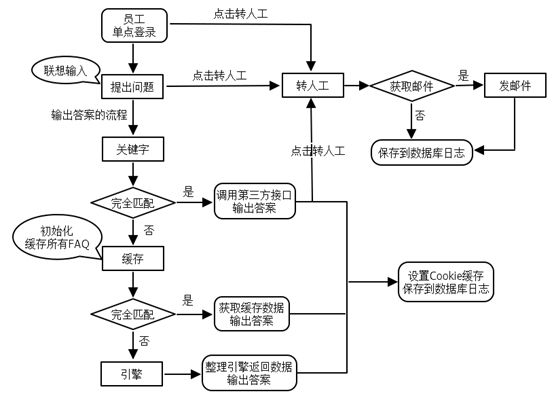
如何优化机器人
1.关键字
预先定义QA与关键词的匹配关系,如果用户问题中包含关键词,则检索与此关键词匹配的QA,缩小查询范围,如果同时包含多个关键字,则unionQA列表,如果不包含关键字则从全部QA检索。
在问题、答案的基础上加入关键词列。
![]()
初始化时,使用行列转化,将关键字和问题加工成1对1的关系

这样在算法比对时,仅判断包含关键字的问题,比对数据量从5000变为了几十条速度提升非常明显,而且还能略微提高正确率
2.缓存
主要设置了2级缓存:缓存5000条问答数据,缓存用户提出的问题和引擎的答案(如果有人问过的问题,将直接从缓存回复)
3.中文处理
自定义词典,中文处理也是很重要部分,分词工具使用jieba,我们将之前标注的关键字作为自定义词典,用来提供特定业务分词的准确性。
去标点符号,标点符号在问答系统中是非常讨厌的,我在训练和用户输入处理时会移除全部的标点符号
去停用词,“是什么,什么时候,是什么意思,多少钱,有没有,更有趣,更有甚者,又为什么,有问题吗,有问题么”等等,这类词在用户提问中经常出现,却没有实际意义,分词后将这类词屏蔽。