caffe安装,caffe使用 alexnet 对自己的数据集进行分类
caffe安装
此教程未小编亲测一步步手写,安装成功,大家哪一步出问题需要找出原因,不可盲目操作
1、硬件 笔记本cpu+华硕8G内存+1T硬盘
2、软件 Ubuntu 14.04 + python2.7
3、安装方法
安装依赖和相关科学计算库
sudo apt-get install libprotobuf-dev
sudo apt-get install libleveldb-dev
sudo apt-get install libsnappy-dev
sudo apt-get install libopencv-dev
sudo apt-get install libhdf5-serial-dev
sudo apt-get install protobuf-compiler
sudo apt-get install libgflags-dev
sudo apt-get install libgoogle-glog-dev
sudo apt-get install liblmdb-dev
sudo apt-get install libatlas-base-dev
sudo apt-get install python-pip
sudo apt-get install gfortran
sudo apt-get install python-protobuf
sudo apt-get install python-skimage
sudo apt-get install --no-install-recommends libboost-all-dev
安装git cmake
sudo apt-get install git cmake
安装结束后下载caffe,执行以下命令:
git clone git://github.com/BVLC/caffe.git
cd caffe/
生成Makefile.config文件,这里是将caffe目录下自带的Makefile.config.example文件复制一份并更名为Makefile.config,命令如下:
cp Makefile.config.example Makefile.config
1 打开Makefile.config
去掉CPU_ONLY前面的#号
2 配置引用文件路径(主要是HDF5的路径问题) ,加上如下文件如下
#whateber else you need goes here
INCLUDE_DIRS :=$(PYTHON_INCLUDE)/usr/local/include /usr/include/hdf5/serial
LIBABRY_DIRS :=$(PYTHON_LIB) /usr/local/lib usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial
新增的内容为:
/usr/include/hdf5/serial
/usr/lib/x86_64-linux-gnu/hdf5/serial
3 opencv如果使用3.0版本需要将opencv=3.0的注释修改为1,默认使用2.4.9
4 编译
make -j8
make pycaffe
make test
make runtest
5 添加环境变量
cd ~/caffe/python
for req in $(cat requirements.txt); do pip install $req; done
sudo pip install -r requirements.txt
先打开配置文件bashrc
sudo gedit ~/.bashrc
在文件的最后面添加
export PYTHONPATH=/home/moqi/caffe/python:$PYTHONPATH
保存退出
sudo ldconfig
6 验证python接口
python
import caffe
未报错即安装成功
其中makefile.config如下
## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome!
# cuDNN acceleration switch (uncomment to build with cuDNN).
# USE_CUDNN := 1
# CPU-only switch (uncomment to build without GPU support).
CPU_ONLY := 1
# uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0
# uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1
# Uncomment if you're using OpenCV 3
OPENCV_VERSION := 3
# To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++
# CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the *_50 through *_61 lines for compatibility.
# For CUDA < 8.0, comment the *_60 and *_61 lines for compatibility.
# For CUDA >= 9.0, comment the *_20 and *_21 lines for compatibility.
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_61,code=sm_61 \
-gencode arch=compute_61,code=compute_61
# BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
BLAS := atlas
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
# BLAS_INCLUDE := /path/to/your/blas
# BLAS_LIB := /path/to/your/blas
# Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
# This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
# ANACONDA_HOME := $(HOME)/anaconda
# PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
# $(ANACONDA_HOME)/include/python2.7 \
# $(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include
# Uncomment to use Python 3 (default is Python 2)
# PYTHON_LIBRARIES := boost_python3 python3.5m
# PYTHON_INCLUDE := /usr/include/python3.5m \
# /usr/lib/python3.5/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
PYTHON_LIB := /usr/lib
# PYTHON_LIB := $(ANACONDA_HOME)/lib
# Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib
# Uncomment to support layers written in Python (will link against Python libs)
WITH_PYTHON_LAYER := 1
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/lib/x86_64-linux-gnu/hdf5/serial/include /usr/local/lib/python2.7/dist-packages/numpy/core/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial
# If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib
# NCCL acceleration switch (uncomment to build with NCCL)
# https://github.com/NVIDIA/nccl (last tested version: v1.2.3-1+cuda8.0)
# USE_NCCL := 1
# Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1
# N.B. both build and distribute dirs are cleared on `make clean`
BUILD_DIR := build
DISTRIBUTE_DIR := distribute
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1
# The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0
# enable pretty build (comment to see full commands)
Q ?= @
1.准备图片
2. 将 图片路径写入txt
import os
class_names_to_ids = {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
data_dir = 'flower_photos/'
output_path = 'list.txt'
fd = open(output_path, 'w')
for class_name in class_names_to_ids.keys():
images_list = os.listdir(data_dir + class_name)
for image_name in images_list:
fd.write('{}/{} {}\n'.format(class_name, image_name, class_names_to_ids[class_name]))
fd.close()
3.转换格式
还是参考这篇文章
4.训练模型
参考这篇
参考这篇
参考这篇
5.测试模型
看过这篇转换均值文件
看过这篇
—————————————————————————————正文————————————————————————————————" />
Ubuntu下caffe:用自己的图片训练并测试AlexNet模型 - CSDN博客
目录
1.准备图片
2. 将 图片路径写入txt
参考 这篇文章
3.转换格式
还是参考这篇文章
4.训练模型
参考这篇
参考这篇
参考这篇
5.测试模型
看过这篇转换均值文件
看过这篇
—————————————————————————————正文——————————————————————————————————————
1.准备图片
在data下新建文件夹myself ,在myself文件夹下新建两个文件夹 train和val。
train用来存放 训练的图片,在train文件夹下新建两个文件夹0和1 。图片有2类,包包(文件夹0)和裤子(文件夹1),每类55种。
Tips:大家从网上找的图片可能命名不规范,身为强迫症当然无法忍受了,一个一个修改太麻烦。
我分两步重命名图片:
第一,在每个图片名字前面加上类别名,这样就会规整很多 ;
rename 's/^/bag/' *第二,把jpg的后缀改为jpeg,别问我为啥,小白看别人这么做,我也这么做了。
rename 's/.jpg $/.jpeg/' *
val 用来放训练过程中用来验证的图片(来计算准确率),val中的图片和train中的不一样。我这里放了15张包包和15张裤子。只将图片后缀重命名了一下。

2. 将 图片路径写入txt
在data/myself/中新建train.txt 和val.txt
需要将图片的路径以及标签都写进去,包包标签为0,裤子标签为1
① 写入路径
find -name *jpeg | grep train | cut -d / -f 3-4 > train.txt
find -name *jpeg | grep val | cut -d / -f 3 > val.txt
sed -i "1,55s/.*/& 1/" train.txt # 1~55是裤子,标签为1
sed -i "55,110s/.*/& 0/" train.txt # 55~110是包包,标签为0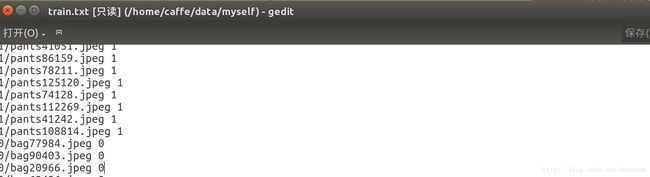
3. 转换数据
在caffe/example目录下新建目录myself。并将caffe/examples/imagenet 目录下create_imagenet.sh文件拷贝到myself中。
注释里是需要改的地方
EXAMPLE=examples/myself #这里修改为自己的路径
DATA=data/myself # 修改为自己的路径
TOOLS=build/tools
TRAIN_DATA_ROOT=/home/caffe/data/myself/train/ # 修改为自己的路径
VAL_DATA_ROOT=/home/caffe/data/myself/val/ #修改为自己的路径
Set RESIZE=true to resize the images to 256x256. Leave as false if images have
already been resized using another tool.
RESIZE=true #这里一定要改成true!!!!!!
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/myself_train_lmdb #把这里改成自己命名的数据库
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/myself_val_lmdb #这里也改一下
返回caffe根目录 运行 sh ./examples/myself/create_imagenet.sh
接下来就会在examples/myself 下生成 两个文件夹 myself_train_lmdb和 myself_train_lmdb
4. 训练数据
把caffe/models/bvlc_reference_caffenet中所有文件复制到caffe/examples/myself文件夹中
① 修改train_val.prototxt
#data/myself文件夹下myimagenet_mean.binaryproto没有这个文件,把data/ilsvrc12下的imagenet_mean.binaryproto复制到该文件夹下,并重命名为myimagenet_mean.binaryprotoname: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "data/myself/myimagenet_mean.binaryproto"
}
#
mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: true
# }
data_param {
source: "examples/myself/myself_train_lmdb"
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "data/myself/myimagenet_mean.binaryproto"
}
# mean pixel / channel-wise mean instead of mean image
# transform_param {
# crop_size: 227
# mean_value: 104
# mean_value: 117
# mean_value: 123
# mirror: false
# }
data_param {
source: "examples/myself/myself_val_lmdb"
batch_size: 50
backend: LMDB
}
}
------------------------------往后拉,在最后----------------------------------------------------
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2 #改这里,图片有几个分类,就写几
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
test_iter: 1000是指测试的批次,我们就10张照片,设置10就可以了。 test_interval: 1000是指每1000次迭代测试一次,我改成了10。 base_lr: 0.01是基础学习率,因为数据量小,0.01就会下降太快了,因此改成0.001 lr_policy: “step”学习率变化 gamma: 0.1学习率变化的比率 stepsize: 100000每100000次迭代减少学习率 display: 20每20层显示一次 max_iter: 4000最大迭代次数, momentum: 0.9学习的参数,不用变 weight_decay: 0.0005学习的参数,不用变 snapshot: 10000每迭代10000次显示状态,这里改为1000次 solver_mode: GPU末尾加一行,代表用GPU进行

③ 图像均值
减去图像均值会获得更好的效果,所以我们使用tools/compute_image_mean.cpp实现,这个cpp是一个很好的例子去熟悉如何操作多个组建,例如协议的缓冲区,leveldbs,登录等。我们同样复制caffe-maester/examples/imagenet的./make_imagenet_mean到examples/myself中,将其改名为make_myimagenet_mean.sh,加以修改路径。
#!/usr/bin/env sh
# Compute the mean image from the imagenet training lmdb
# N.B. this is available in data/ilsvrc12
EXAMPLE=/home/caffe/examples/myself
DATA=/home/caffe/data/myself
TOOLS=/home/caffe/build/tools
$TOOLS/compute_image_mean $EXAMPLE/myself_train_lmdb
$DATA/myimagenet_mean.binaryproto
echo “Done.”
④ 运行
拷贝examples/imagenet目录下的train_caffenet.sh文件到example/myself目录下。
#!/usr/bin/env sh
./build/tools/caffe train
–solver=examples/myself/solver.prototxt
在caffe的主目录下输入命令:./ examples/myself/train_caffenet.sh开始训练网络。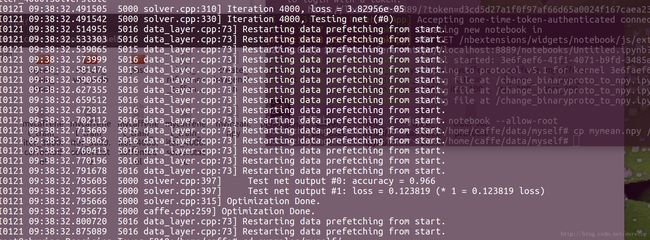
我电脑快,训练了十分钟左右就好啦(默默炫耀一下。。。)出现 【Restarting data prefetching from start.】的提示不要慌,因为图片太少,又从第一幅图片开始训练了。哈哈,我的精确率0.996 还是挺高的。
5 . 测试数据
① 找一个你要测试的图片,我找了一个想买但买不起的包包的图片。。
。。
②修改deploy.prototxt 并编写一个labels.txt
deploy.prototxt 修改一个地方
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
num_output: 2 #改成2
}
}bag
pants② 打开data/myself 将myimagenet_mean.binaryproto 转换成 mymean.npy
打开jupyter写个python
import caffe
import numpy as np
proto_path=‘myimagenet_mean.binaryproto’
npy_path=‘mymean.npy’
blob=caffe.proto.caffe_pb2.BlobProto()
data=open(proto_path,‘rb’).read()
blob.ParseFromString(data)
array=np.array(caffe.io.blobproto_to_array(blob))
mean_npy=array[0]
np.save(npy_path,mean_npy)
把生成的mymean.npy复制到examples/myself下
③用Python写代码对 包包图片 分类
import caffe
import sys
import numpy as np
caffe_root=’/home/caffe/’
sys.path.insert(0,caffe_root+‘python’)
caffe.set_mode_cpu()
deploy=caffe_root+‘examples/myself/deploy.prototxt’
caffe_model=caffe_root+‘examples/myself/mycaffenet_train_iter_1000.caffemodel’
img=caffe_root+‘examples/myself/pinko.jpeg’
labels_name=caffe_root+‘examples/myself/labels.txt’
mean_file=caffe_root+‘examples/myself/mymean.npy’
net=caffe.Net(deploy,caffe_model,caffe.TEST)
transformer=caffe.io.Transformer({‘data’:net.blobs[‘data’].data.shape})
transformer.set_transpose(‘data’,(2,0,1))
transformer.set_mean(‘data’,np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale(‘data’,255)
transformer.set_channel_swap(‘data’,(2,1,0))
image=caffe.io.load_image(img)
net.blobs[‘data’].data[…]=transformer.preprocess(‘data’,image)
out=net.forward()
labels=np.loadtxt(labels_name,str,delimiter=’\t’)
prob=net.blobs[‘prob’].data[0].flatten()
top_k=net.blobs[‘prob’].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i],labels[top_k[i]],prob[top_k[i]]
下面是结果: 完美 O(∩_∩)O
