※数据结构※→☆非线性结构(tree)☆============二叉树 顺序存储结构(tree binary sequence)(十九)
======================================================================================================
二叉树
在计算机科学中,二叉树是每个结点最多有两个子树的有序树。通常子树的根被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用作二叉查找树和二叉堆或是二叉排序树。二叉树的每个结点至多只有二棵子树(不存在出度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第i层至多有2的 i -1次方个结点;深度为k的二叉树至多有2^(k) -1个结点;对任何一棵二叉树T,如果其终端结点数(即叶子结点数)为,出度为2的结点数为,则=+ 1。
基本形态
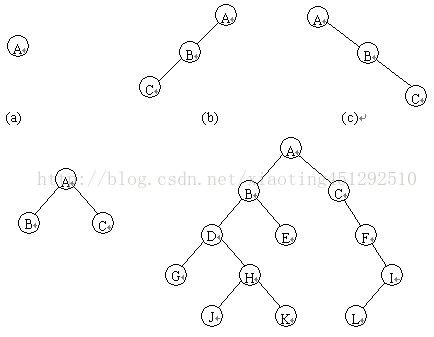
二叉树也是递归定义的,其结点有左右子树之分,逻辑上二叉树有五种基本形态:
(1)空二叉树——(a);
(2)只有一个根结点的二叉树——(b);
(3)只有左子树——(c);
(4)只有右子树——(d);
(5)完全二叉树——(e)
注意:尽管二叉树与树有许多相似之处,但二叉树不是树的特殊情形。
重要概念
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)深度——二叉树的层数,就是高度。
性质
(1) 在二叉树中,第i层的结点总数不超过2^(i-1);
(2) 深度为h的二叉树最多有2^h-1个结点(h>=1),最少有h个结点;
(3) 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1;
(4) 具有n个结点的完全二叉树的深度为int(log2n)+1
(5)有N个结点的完全二叉树各结点如果用顺序方式存储,则结点之间有如下关系:
若I为结点编号则 如果I>1,则其父结点的编号为I/2;
如果2*I<=N,则其左儿子(即左子树的根结点)的编号为2*I;若2*I>N,则无左儿子;
如果2*I+1<=N,则其右儿子的结点编号为2*I+1;若2*I+1>N,则无右儿子。
(6)给定N个节点,能构成h(N)种不同的二叉树。
h(N)为卡特兰数的第N项。h(n)=C(n,2*n)/(n+1)。
(7)设有i个枝点,I为所有枝点的道路长度总和,J为叶的道路长度总和J=I+2i
1.完全二叉树 (Complete Binary Tree)
若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层从右向左连续缺若干结点,这就是完全二叉树。
2.满二叉树 (Full Binary Tree)
一个高度为h的二叉树包含正是2^h-1元素称为满二叉树。
二叉树四种遍历
1.先序遍历 (仅二叉树)
指先访问根,然后访问孩子的遍历方式
非递归实现
利用栈实现,先取根节点,处理节点,然后依次遍历左节点,遇到有右节点压入栈,向左走到尽头。然后从栈中取出右节点,处理右子树。
/*** PreOrderTraversal
*
* @param AL_ListSeq& listOrder
* @return BOOL
* @note Pre-order traversal
* @attention
*/
template BOOL
AL_TreeBinSeq::PreOrderTraversal(AL_ListSeq& listOrder) const
{
if (NULL == m_pRootNode) {
return FALSE;
}
listOrder.Clear();
//Recursion Traversal
PreOrderTraversal(m_pRootNode, listOrder);
return TRUE;
//Not Recursion Traversal
AL_StackSeq*> cStack;
AL_TreeNodeBinSeq* pTreeNode = m_pRootNode;
while (TRUE != cStack.IsEmpty() || NULL != pTreeNode) {
while (NULL != pTreeNode) {
listOrder.InsertEnd(pTreeNode->GetData());
if (NULL != pTreeNode->GetChildRight()) {
//push the child right to stack
cStack.Push(pTreeNode->GetChildRight());
}
pTreeNode = pTreeNode->GetChildLeft();
}
if (TRUE == cStack.Pop(pTreeNode)) {
if (NULL == pTreeNode) {
return FALSE;
}
}
else {
return FALSE;
}
}
return TRUE;
}
递归实现
/**
* PreOrderTraversal
*
* @param const AL_TreeNodeBinSeq* pCurTreeNode
* @param AL_ListSeq& listOrder
* @return VOID
* @note Pre-order traversal
* @attention Recursion Traversal
*/
template VOID
AL_TreeBinSeq::PreOrderTraversal(const AL_TreeNodeBinSeq* pCurTreeNode, AL_ListSeq& listOrder) const
{
if (NULL == pCurTreeNode) {
return;
}
//Do Something with root
listOrder.InsertEnd(pCurTreeNode->GetData());
if(NULL != pCurTreeNode->GetChildLeft()) {
PreOrderTraversal(pCurTreeNode->GetChildLeft(), listOrder);
}
if(NULL != pCurTreeNode->GetChildRight()) {
PreOrderTraversal(pCurTreeNode->GetChildRight(), listOrder);
}
} 2.中序遍历(仅二叉树)
指先访问左(右)孩子,然后访问根,最后访问右(左)孩子的遍历方式
非递归实现
利用栈实现,先取根节点,然后依次遍历左节点,将左节点压入栈,向左走到尽头。然后从栈中取出左节点,处理节点。然后处理其右子树。
/**
* InOrderTraversal
*
* @param AL_ListSeq& listOrder
* @return BOOL
* @note In-order traversal
* @attention
*/
template BOOL
AL_TreeBinSeq::InOrderTraversal(AL_ListSeq& listOrder) const
{
if (NULL == m_pRootNode) {
return FALSE;
}
listOrder.Clear();
//Recursion Traversal
InOrderTraversal(m_pRootNode, listOrder);
return TRUE;
//Not Recursion Traversal
AL_StackSeq*> cStack;
AL_TreeNodeBinSeq* pTreeNode = m_pRootNode;
while (TRUE != cStack.IsEmpty() || NULL != pTreeNode) {
while (NULL != pTreeNode) {
cStack.Push(pTreeNode);
pTreeNode = pTreeNode->GetChildLeft();
}
if (TRUE == cStack.Pop(pTreeNode)) {
if (NULL != pTreeNode) {
listOrder.InsertEnd(pTreeNode->GetData());
if (NULL != pTreeNode->GetChildRight()){
//child right exist, push the node, and loop it's left child to push
pTreeNode = pTreeNode->GetChildRight();
}
else {
//to pop the node in the stack
pTreeNode = NULL;
}
}
else {
return FALSE;
}
}
else {
return FALSE;
}
}
return TRUE;
} 递归实现
/**
* InOrderTraversal
*
* @param const AL_TreeNodeBinSeq* pCurTreeNode
* @param AL_ListSeq& listOrder
* @return VOID
* @note In-order traversal
* @attention Recursion Traversal
*/
template VOID
AL_TreeBinSeq::InOrderTraversal(const AL_TreeNodeBinSeq* pCurTreeNode, AL_ListSeq& listOrder) const
{
if (NULL == pCurTreeNode) {
return;
}
if(NULL != pCurTreeNode->GetChildLeft()) {
InOrderTraversal(pCurTreeNode->GetChildLeft(), listOrder);
}
//Do Something with root
listOrder.InsertEnd(pCurTreeNode->GetData());
if(NULL != pCurTreeNode->GetChildRight()) {
InOrderTraversal(pCurTreeNode->GetChildRight(), listOrder);
}
}
3.后序遍历(仅二叉树)
指先访问孩子,然后访问根的遍历方式
非递归实现
利用栈实现,先取根节点,然后依次遍历左节点,将左节点压入栈,向左走到尽头。然后从栈中取出左节点,处理节点。处理其右节点,还需要记录已经使用过的节点,比较麻烦和复杂。大致思路如下:
- 1.找到最左边的子节点
- 2.如果最左边的子节点有右节点,处理右节点(类似1)
- 3.从栈里弹出节点处理
- 3.当碰到左右节点都存在的节点时,需要进行记录了回归节点了。然后以当前节点的右子树进行处理
- 4.碰到回归节点时,把当前的最后一个元素消除(因为后面还会回归到这个点的)。
/**
* PostOrderTraversal
*
* @param AL_ListSeq& listOrder
* @return BOOL
* @note Post-order traversal
* @attention
*/
template BOOL
AL_TreeBinSeq::PostOrderTraversal(AL_ListSeq& listOrder) const
{
if (NULL == m_pRootNode) {
return FALSE;
}
listOrder.Clear();
//Recursion Traversal
PostOrderTraversal(m_pRootNode, listOrder);
return TRUE;
//Not Recursion Traversal
AL_StackSeq*> cStack;
AL_TreeNodeBinSeq* pTreeNode = m_pRootNode;
AL_StackSeq*> cStackReturn;
AL_TreeNodeBinSeq* pTreeNodeReturn = NULL;
while (TRUE != cStack.IsEmpty() || NULL != pTreeNode) {
while (NULL != pTreeNode) {
cStack.Push(pTreeNode);
if (NULL != pTreeNode->GetChildLeft()) {
pTreeNode = pTreeNode->GetChildLeft();
}
else {
//has not left child, get the right child
pTreeNode = pTreeNode->GetChildRight();
}
}
if (TRUE == cStack.Pop(pTreeNode)) {
if (NULL != pTreeNode) {
listOrder.InsertEnd(pTreeNode->GetData());
if (NULL != pTreeNode->GetChildLeft() && NULL != pTreeNode->GetChildRight()){
//child right exist
cStackReturn.Top(pTreeNodeReturn);
if (pTreeNodeReturn != pTreeNode) {
listOrder.RemoveAt(listOrder.Length()-1);
cStack.Push(pTreeNode);
cStackReturn.Push(pTreeNode);
pTreeNode = pTreeNode->GetChildRight();
}
else {
//to pop the node in the stack
cStackReturn.Pop(pTreeNodeReturn);
pTreeNode = NULL;
}
}
else {
//to pop the node in the stack
pTreeNode = NULL;
}
}
else {
return FALSE;
}
}
else {
return FALSE;
}
}
return TRUE;
} 递归实现
/**
* PostOrderTraversal
*
* @param const AL_TreeNodeBinSeq* pCurTreeNode
* @param AL_ListSeq& listOrder
* @return VOID
* @note Post-order traversal
* @attention Recursion Traversal
*/
template VOID
AL_TreeBinSeq::PostOrderTraversal(const AL_TreeNodeBinSeq* pCurTreeNode, AL_ListSeq& listOrder) const
{
if (NULL == pCurTreeNode) {
return;
}
if(NULL != pCurTreeNode->GetChildLeft()) {
PostOrderTraversal(pCurTreeNode->GetChildLeft(), listOrder);
}
if(NULL != pCurTreeNode->GetChildRight()) {
PostOrderTraversal(pCurTreeNode->GetChildRight(), listOrder);
}
//Do Something with root
listOrder.InsertEnd(pCurTreeNode->GetData());
} 4.层次遍历
一层一层的访问,所以一般用广度优先遍历。
非递归实现
利用链表或者队列均可实现,先取根节点压入链表或者队列,依次从左往右体访问子节点,压入链表或者队列。直至处理完所有节点。
/**
* LevelOrderTraversal
*
* @param AL_ListSeq& listOrder
* @return BOOL
* @note Level-order traversal
* @attention
*/
template BOOL
AL_TreeBinSeq::LevelOrderTraversal(AL_ListSeq& listOrder) const
{
if (TRUE == IsEmpty()) {
return FALSE;
}
if (NULL == m_pRootNode) {
return FALSE;
}
listOrder.Clear();
/*
AL_ListSeq*> listNodeOrder;
listNodeOrder.InsertEnd(m_pRootNode);
//loop the all node
DWORD dwNodeOrderLoop = 0x00;
AL_TreeNodeBinSeq* pNodeOrderLoop = NULL;
AL_TreeNodeBinSeq* pNodeOrderChild = NULL;
while (TRUE == listNodeOrder.Get(pNodeOrderLoop, dwNodeOrderLoop)) {
dwNodeOrderLoop++;
if (NULL != pNodeOrderLoop) {
listOrder.InsertEnd(pNodeOrderLoop->GetData());
pNodeOrderChild = pNodeOrderLoop->GetChildLeft();
if (NULL != pNodeOrderChild) {
queueOrder.Push(pNodeOrderChild);
}
pNodeOrderChild = pNodeOrderLoop->GetChildRight();
if (NULL != pNodeOrderChild) {
queueOrder.Push(pNodeOrderChild);
}
}
else {
//error
return FALSE;
}
}
return TRUE;
*/
AL_QueueSeq*> queueOrder;
queueOrder.Push(m_pRootNode);
AL_TreeNodeBinSeq* pNodeOrderLoop = NULL;
AL_TreeNodeBinSeq* pNodeOrderChild = NULL;
while (FALSE == queueOrder.IsEmpty()) {
if (TRUE == queueOrder.Pop(pNodeOrderLoop)) {
if (NULL != pNodeOrderLoop) {
listOrder.InsertEnd(pNodeOrderLoop->GetData());
pNodeOrderChild = pNodeOrderLoop->GetChildLeft();
if (NULL != pNodeOrderChild) {
queueOrder.Push(pNodeOrderChild);
}
pNodeOrderChild = pNodeOrderLoop->GetChildRight();
if (NULL != pNodeOrderChild) {
queueOrder.Push(pNodeOrderChild);
}
}
else {
return FALSE;
}
}
else {
return FALSE;
}
}
return TRUE;
} 递归实现 (无)
======================================================================================================
树(tree)
树(tree)是包含n(n>0)个结点的有穷集合,其中:
- 每个元素称为结点(node);
- 有一个特定的结点被称为根结点或树根(root)。
- 除根结点之外的其余数据元素被分为m(m≥0)个互不相交的集合T1,T2,……Tm-1,其中每一个集合Ti(1<=i<=m)本身也是一棵树,被称作原树的子树(subtree)。
树也可以这样定义:树是由根结点和若干颗子树构成的。树是由一个集合以及在该集合上定义的一种关系构成的。集合中的元素称为树的结点,所定义的关系称为父子关系。父子关系在树的结点之间建立了一个层次结构。在这种层次结构中有一个结点具有特殊的地位,这个结点称为该树的根结点,或称为树根。
我们可以形式地给出树的递归定义如下:
- 单个结点是一棵树,树根就是该结点本身。
- 设T1,T2,..,Tk是树,它们的根结点分别为n1,n2,..,nk。用一个新结点n作为n1,n2,..,nk的父亲,则得到一棵新树,结点n就是新树的根。我们称n1,n2,..,nk为一组兄弟结点,它们都是结点n的子结点。我们还称n1,n2,..,nk为结点n的子树。
- 空集合也是树,称为空树。空树中没有结点。
树的四种遍历
1.先序遍历 (仅二叉树)
指先访问根,然后访问孩子的遍历方式
2.中序遍历(仅二叉树)
指先访问左(右)孩子,然后访问根,最后访问右(左)孩子的遍历方式
3.后序遍历(仅二叉树)
指先访问孩子,然后访问根的遍历方式
4.层次遍历
一层一层的访问,所以一般用广度优先遍历。
======================================================================================================
树结点 顺序存储结构(tree node sequence)
结点:
包括一个数据元素及若干个指向其它子树的分支;例如,A,B,C,D等。在数据结构的图形表示中,对于数据集合中的每一个数据元素用中间标有元素值的方框表示,一般称之为数据结点,简称结点。
在C语言中,链表中每一个元素称为“结点”,每个结点都应包括两个部分:一为用户需要用的实际数据;二为下一个结点的地址,即指针域和数据域。
数据结构中的每一个数据结点对应于一个储存单元,这种储存单元称为储存结点,也可简称结点
树结点(树节点):
树节点相关术语:
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 叶节点或终端节点:度为0的节点称为叶节点;
- 非终端节点或分支节点:度不为0的节点;
- 双亲节点或父节点:若一个结点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
根据树结点的相关定义,采用“双亲孩子表示法”。其属性如下:
DWORD m_dwLevel; //Node levels: starting from the root to start defining the root of the first layer, the root node is a sub-layer 2, and so on;
T m_data; //the friend class can use it directly
AL_TreeNodeSeq* m_pParent; //Parent position
AL_ListSeq*> m_listChild; //All Child tree node 树的几种表示法
在实际中,可使用多种形式的存储结构来表示树,既可以采用顺序存储结构,也可以采用链式存储结构,但无论采用何种存储方式,都要求存储结构不但能存储各结点本身的数据信息,还要能唯一地反映树中各结点之间的逻辑关系。
1.双亲表示法
由于树中的每个结点都有唯一的一个双亲结点,所以可用一组连续的存储空间(一维数组)存储树中的各个结点,数组中的一个元素表示树中的一个结点,每个结点含两个域,数据域存放结点本身信息,双亲域指示本结点的双亲结点在数组中位置。
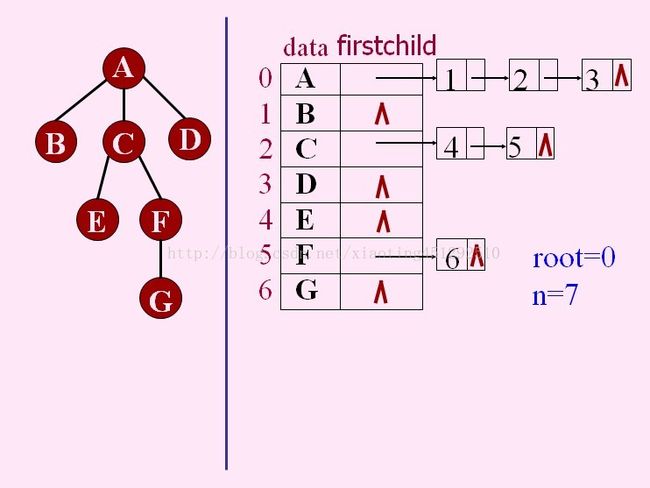
2.孩子表示法
1.多重链表:每个结点有多个指针域,分别指向其子树的根
1)结点同构:结点的指针个数相等,为树的度k,这样n个结点度为k的树必有n(k-1)+1个空链域.

2)结点不同构:结点指针个数不等,为该结点的度d

2.孩子链表:每个结点的孩子结点用单链表存储,再用含n个元素的结构数组指向每个孩子链表

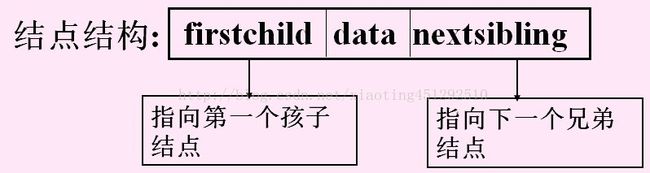
3.双亲孩子表示法
1.双亲表示法,PARENT(T,x)可以在常量时间内完成,但是求结点的孩子时需要遍历整个结构。
2.孩子链表表示法,适于那些涉及孩子的操作,却不适于PARENT(T,x)操作。
3.将双亲表示法和孩子链表表示法合在一起,可以发挥以上两种存储结构的优势,称为带双亲的孩子链表表示法

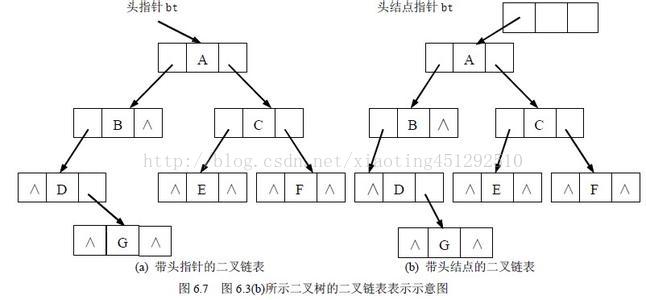
4.双亲孩子兄弟表示法 (二叉树专用)
又称为二叉树表示法,以二叉链表作为树的存储结构。
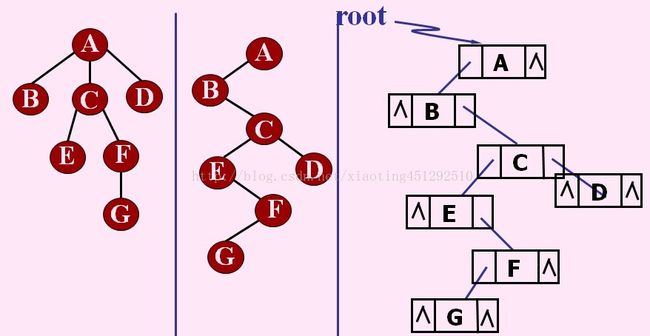
顺序存储结构
在计算机中用一组地址连续的存储单元依次存储线性表的各个数据元素,称作线性表的顺序存储结构.
顺序存储结构是存储结构类型中的一种,该结构是把逻辑上相邻的节点存储在物理位置上相邻的存储单元中,结点之间的逻辑关系由存储单元的邻接关系来体现。由此得到的存储结构为顺序存储结构,通常顺序存储结构是借助于计算机程序设计语言(例如c/c++)的数组来描述的。
顺序存储结构的主要优点是节省存储空间,因为分配给数据的存储单元全用存放结点的数据(不考虑c/c++语言中数组需指定大小的情况),结点之间的逻辑关系没有占用额外的存储空间。采用这种方法时,可实现对结点的随机存取,即每一个结点对应一个序号,由该序号可以直接计算出来结点的存储地址。但顺序存储方法的主要缺点是不便于修改,对结点的插入、删除运算时,可能要移动一系列的结点。
优点:
随机存取表中元素。缺点:插入和删除操作需要移动元素。
本代码默认list可以容纳的item数目为100个,用户可以自行设置item数目。当list饱和时,由于Tree是非线性结构,动态扩展内存相当麻烦。因此示例中的Demo及代码将不会动态扩展内存。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
以后的笔记潇汀会尽量详细讲解一些相关知识的,希望大家继续关注我的博客。
本节笔记到这里就结束了。
潇汀一有时间就会把自己的学习心得,觉得比较好的知识点写出来和大家一起分享。
编程开发的路很长很长,非常希望能和大家一起交流,共同学习,共同进步。
如果文章中有什么疏漏的地方,也请大家指正。也希望大家可以多留言来和我探讨编程相关的问题。
最后,谢谢你们一直的支持~~~
C++完整个代码示例(代码在VS2005下测试可运行)