深度剖析ConcurrentHashMap源码
概述
你可能会在一些技术类的书籍上看到下面这样一段关于HahsMap和Hashtable的表述:
HashMap是非线程安全的,Hashtable是线程安全的。
不知道大家有什么反应,我当时只是记住了,知道面试的时候能回答上来就行了…至于为什么是线程安全的,内部怎么实现的,却不怎么了解。
今天我们将深入剖析一个比Hashtable性能更优的线程安全的Map类,它就是ConcurrentHashMap,本文基于Java 7的源码做剖析。
ConcurrentHashMap的目的
多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%。可以通过下面的例子可以得到验证:
public static void main(String[] args) {
final HashMap map = new HashMap(2);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
t.start();
try {
t.join();
System.out.println("map.size="+map.size());
} catch (InterruptedException e) {
e.printStackTrace();
}
} 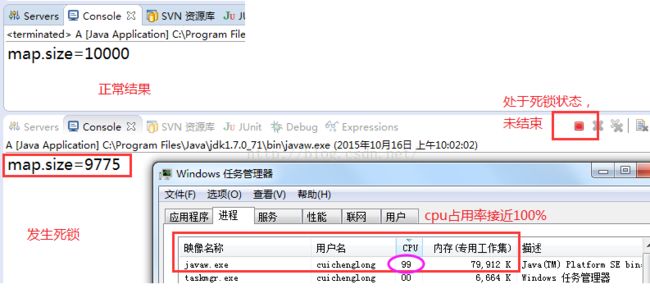
所以在并发情况下不能使用HashMap。虽然已经有一个线程安全的Hashtable,但是Hashtable容器使用synchronized(他的get和put方法的实现代码如下)来保证线程安全,在线程竞争激烈的情况下Hashtable的效率非常低下。因为当一个线程访问Hashtable的同步方法时,访问其他同步方法的线程就可能会进入阻塞或者轮训状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
} 在这么恶劣的环境下,ConcurrentHashMap应运而生。
实现原理
与Hashtable的锁机制不同,ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
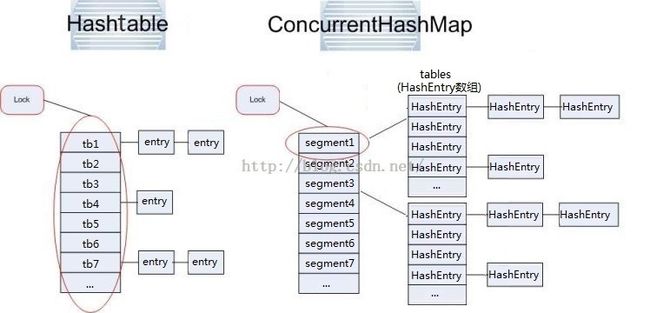
- 对于一个key,先进行一次hash操作,得到hash值h1,也即h1 = hash1(key);
- 将得到的h1的高几位进行第二次hash,得到hash值h2,也即h2 = hash2(h1高几位),通过h2能够确定该元素的放在哪个Segment;
- 将得到的h1进行第三次hash,得到hash值h3,也即h3 = hash3(h1),通过h3能够确定该元素放置在HashEntry数组中的哪个位置,然后通过for循环来查找。
初始化
先看看ConcurrentHashMap的初始化做了哪些事情,构造函数的源码如下:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment s0 =
new Segment(loadFactor, (int)(cap * loadFactor),
(HashEntry[])new HashEntry[cap]);
Segment[] ss = (Segment[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
} 传入的参数有initialCapacity,loadFactor,concurrencyLevel这三个。
- initialCapacity表示新创建的这个ConcurrentHashMap的初始容量,也就是上面的结构图中的Entry数量。默认值为
static final int DEFAULT_INITIAL_CAPACITY = 16; - loadFactor表示负载因子,就是当ConcurrentHashMap中的元素个数大于loadFactor * 最大容量时就需要rehash,扩容。默认值为
static final float DEFAULT_LOAD_FACTOR = 0.75f; - concurrencyLevel表示并发级别,这个值用来确定Segment的个数,Segment的个数是大于等于concurrencyLevel的第一个2的n次方的数。比如,如果concurrencyLevel为12,13,14,15,16这些数,则Segment的数目为16(2的4次方)。默认值为
static final int DEFAULT_CONCURRENCY_LEVEL = 16;。理想情况下ConcurrentHashMap的真正的并发访问量能够达到concurrencyLevel,因为有concurrencyLevel个Segment,假如有concurrencyLevel个线程需要访问Map,并且需要访问的数据都恰好分别落在不同的Segment中,则这些线程能够无竞争地自由访问(因为他们不需要竞争同一把锁),达到同时访问的效果。这也是为什么这个参数起名为“并发级别”的原因。
初始化的一些动作:
- 验证参数的合法性,如果不合法,直接抛出异常。
- concurrencyLevel也就是Segment的个数不能超过规定的最大Segment的个数,默认值为
static final int MAX_SEGMENTS = 1 << 16;,如果超过这个值,设置为这个值。 - 然后使用循环找到大于等于concurrencyLevel的第一个2的n次方的数ssize,这个数就是Segment数组的大小,并记录一共向左按位移动的次数sshift,并令
segmentShift = 32 - sshift,并且segmentMask的值等于ssize - 1,segmentMask的各个二进制位都为1,目的是之后可以通过key的hash值与这个值做&运算确定Segment的索引。 - 检查给定的容量值是否大于允许的最大容量值,如果大于该值,设置为该值。最大容量值为
static final int MAXIMUM_CAPACITY = 1 << 30;。 - 然后计算每个Segment平均应该放置多少个元素,这个值c是向上取整的值。比如初始容量为15,Segment个数为4,则每个Segment平均需要放置4个元素。
- 创建一个Segment实例,第一个参数传入负载因子。第二个参数扩容临界值(容量*负载因子),第三个参数是指定容量的HashEntry空数组 。
- 最后创建将Segment数组,并将第六步创建的Segment实例当做Segment数组的第一个元素。
put操作
put操作的源码如下:
public V put(K key, V value) {
Segment s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
} 操作步骤如下:
- 判断value是否为null,如果为null,直接抛出异常。
- key通过一次hash运算得到一个hash值。(这个hash运算下文详说)
- 将得到hash值向右按位移动segmentShift位,然后再与segmentMask做&运算得到segment的索引j。
在初始化的时候我们说过segmentShift的值等于32-sshift,例如concurrencyLevel等于16,则sshift等于4,则segmentShift为28。hash值是一个32位的整数,将其向右移动28位就变成这个样子:
0000 0000 0000 0000 0000 0000 0000 xxxx,然后再用这个值与segmentMask做&运算,也就是取最后四位的值。这个值确定Segment的索引。 - 使用Unsafe的方式从Segment数组中获取该索引对应的Segment对象。
- 向这个Segment对象中put值,这个put操作也基本是一样的步骤(通过&运算获取HashEntry的索引,然后set)。
get操作
get操作的源码如下:
public V get(Object key) {
Segment s; // manually integrate access methods to reduce overhead
HashEntry[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
} 操作步骤为:
- 和put操作一样,先通过key进行两次hash确定应该去哪个Segment中取数据。
- 使用Unsafe获取对应的Segment,然后再进行一次&运算得到HashEntry链表的位置,然后从链表头开始遍历整个链表(因为Hash可能会有碰撞,所以用一个链表保存),如果找到对应的key,则返回对应的value值,如果链表遍历完都没有找到对应的key,则说明Map中不包含该key,返回null。
size操作
size操作与put和get操作最大的区别在于,size操作需要遍历所有的Segment才能算出整个Map的大小,而put和get都只关心一个Segment。假设我们当前遍历的Segment为S1,那么在遍历S1过程中其他的Segment比如S2可能会被修改,于是这一次运算出来的size值可能并不是Map当前的真正大小。所以一个比较简单的办法就是计算Map大小的时候所有的Segment都Lock住,不能更新(包含put,remove等等)数据,计算完之后再Unlock。这是普通人能够想到的方案,但是牛逼的作者还有一个更好的Idea:先给3次机会,不lock所有的Segment,遍历所有Segment,累加各个Segment的大小得到整个Map的大小,如果某相邻的两次计算获取的所有Segment的更新次数(每个Segment都有一个modCount变量,这个变量在Segment中的Entry被修改时会加一,通过这个值可以得到每个Segment的更新操作的次数)是一样的,说明计算过程中没有更新操作,则直接返回这个值。如果这三次不加锁的计算过程中Map的更新次数有变化,则之后的计算先对所有的Segment加锁,再遍历所有Segment计算Map大小,最后再解锁所有Segment。源代码如下:
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
} 举个例子:
一个Map有4个Segment,标记为S1,S2,S3,S4,现在我们要获取Map的size。计算过程是这样的:第一次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设每个Segment的大小分别为1,2,3,4,更新操作次数分别为:2,2,3,1,则这次计算可以得到Map的总大小为1+2+3+4=10,总共更新操作次数为2+2+3+1=8;第二次计算,不对S1,S2,S3,S4加锁,遍历所有Segment,假设这次每个Segment的大小变成了2,2,3,4,更新次数分别为3,2,3,1,因为两次计算得到的Map更新次数不一致(第一次是8,第二次是9)则可以断定这段时间Map数据被更新,则此时应该再试一次;第三次计算,不对S1,S2,S3,S4加锁,遍历所有Segment,假设每个Segment的更新操作次数还是为3,2,3,1,则因为第二次计算和第三次计算得到的Map的更新操作的次数是一致的,就能说明第二次计算和第三次计算这段时间内Map数据没有被更新,此时可以直接返回第三次计算得到的Map的大小。最坏的情况:第三次计算得到的数据更新次数和第二次也不一样,则只能先对所有Segment加锁再计算。如果第四次得到的结果跟第三次计算的不一样,还需要计算第五次,这次不会进行二次加锁,由于加过锁,所以得到的结果肯定与第四次一致,最终将所有Segment解锁,并返回size。
containsValue操作
containsValue操作采用了和size操作一样的思路,只不过在查找到后,会直接break最外层的循环,然后返回true,这点需要注意。
public boolean containsValue(Object value) {
// Same idea as size()
if (value == null)
throw new NullPointerException();
final Segment[] segments = this.segments;
boolean found = false;
long last = 0;
int retries = -1;
try {
outer: for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
long hashSum = 0L;
int sum = 0;
for (int j = 0; j < segments.length; ++j) {
HashEntry[] tab;
Segment seg = segmentAt(segments, j);
if (seg != null && (tab = seg.table) != null) {
for (int i = 0 ; i < tab.length; i++) {
HashEntry e;
for (e = entryAt(tab, i); e != null; e = e.next) {
V v = e.value;
if (v != null && value.equals(v)) {
found = true;
break outer;
}
}
}
sum += seg.modCount;
}
}
if (retries > 0 && sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return found;
} 关于hash
大家一定还记得使用一个key定位Segment之前进行过一次hash操作吧?这次hash的作用是什么呢?看看hash的源代码:
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}源码中的注释是这样的:
Applies a supplemental hash function to a given hashCode, which defends against poor quality hash functions. This is critical because ConcurrentHashMap uses power-of-two length hash tables, that otherwise encounter collisions for hashCodes that do not differ in lower or upper bits.
这里用到了Wang/Jenkins hash算法的变种,主要的目的是为了减少哈希冲突,使元素能够均匀的分布在不同的Segment上,从而提高容器的存取效率。假如哈希的质量差到极点,那么所有的元素都在一个Segment中,不仅存取元素缓慢,分段锁也会失去意义。
举个简单的例子:
System.out.println(Integer.parseInt("0001111", 2) & 15);
System.out.println(Integer.parseInt("0011111", 2) & 15);
System.out.println(Integer.parseInt("0111111", 2) & 15);
System.out.println(Integer.parseInt("1111111", 2) & 15);这些数字得到的hash值都是一样的,全是15,所以如果不进行第一次预hash,发生冲突的几率还是很大的,但是如果我们先把上例中的二进制数字使用hash()函数先进行一次预hash,得到的结果是这样的:
1110 | 1101 | 0011 | 1101 | 0100 | 1011 | 1101 | 1111
1101 | 1111 | 1101 | 1000 | 1001 | 1011 | 0110 | 1110
1111 | 1101 | 1001 | 1110 | 0100 | 1000 | 0011 | 0010
0101 | 0110 | 1100 | 1000 | 0110 | 1010 | 1000 | 0110
可以看到每一位的数据都散开了,并且ConcurrentHashMap中是使用预hash值的高位参与运算的。比如之前说的先将hash值向右按位移动28位,再与15做&运算,得到的结果都别为:14,13,15,5,没有冲突!
注意事项
- ConcurrentHashMap中的key和value值都不能为null。
- ConcurrentHashMap的整个操作过程中大量使用了Unsafe类来获取Segment/HashEntry,这里Unsafe的主要作用是提供原子操作。Unsafe这个类比较恐怖,破坏力极强,一般场景不建议使用,如果有兴趣可以到这里做详细的了解Java中鲜为人知的特性
- ConcurrentHashMap是线程安全的类并不能保证使用了ConcurrentHashMap的操作都是线程安全的!
相关文章:http://www.infoq.com/cn/articles/ConcurrentHashMap/
http://qifuguang.me/2015/09/10/[Java并发包学习八]深度剖析ConcurrentHashMap/