Elasticsearch集群规模和性能调优
翻译自:Elasticsearch Cluster Sizing and Performance Tuning
地址:https://www.elastic.co/cn/blog/found-sizing-elasticsearch
集群应该有多少个节点?应该创建多少个副本?为了获得最佳的搜索性能,分片(Shard)的最佳平均大小是多少?诸如此类的问题只有你自己知道答案。
没有人知道你的数据和查询结构,你使用的硬件,你的吞吐量。没有数学公式,也没有理论计算方法。如果你带着这样的期望而来,我很抱歉让你失望。但是别担心,你可以自己回答。
数据的大小
如您所知,由于分布式体系结构中的硬件限制,数据被划分为更小的块,并分布在不同的节点上。这些小片段称为分片。实际上,当其中一个节点发生故障时,与原始节点完全相同的分片仍保留在备用中。这些分片称为副本。
分片的最佳数量是多少?
每个请求在每个分片的单个线程中处理。如果您有多个分片,则可以并行处理查询。将分片数量增加到一定程度可能会对性能产生积极影响,但这并不完全正确。如果您有很多小分片,则过一会儿,将有大量并行任务需要在队列中等待。当同时接收到多个请求时,这将降低性能。
分片是Lucene索引,它通过一个或多个段来将数据存储在磁盘上。较大的段能更有效地存储数据。因此,增加分片的数量可能并不总是一个好主意。
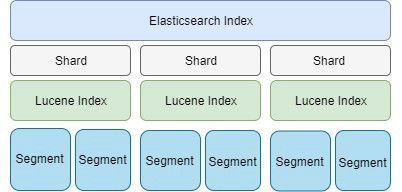
您可以通过在单节点群集中创建分片来进行测试。考虑一下索引的大小和我在下一节中提到的平均分片大小,一次增加一个分片。您可以自己找到理想分片的数量。
分片的最佳平均大小是多少?
在这个问题上没有绝对的准则。您应该为自己选择一个起点,然后尝试找到最佳尺寸。Elasticsearch官网的建议如下:
- 分片的平均大小应在几GB到几十GB之间。
- 确定用例的最佳大小的最佳方法是使用您自己的数据和查询进行测试。
副本的最佳数量是多少?
考虑到硬件故障,建议至少有一个副本。副本提高了搜索性能,但并不总是如此。这取决于您的硬件和索引的行为(大量写入或大量搜索)。如果您的索引写入很多,那么增加副本的数量不是一个好主意。由于数据复制过程会导致资源使用增加,并且搜索性能会下降。
让负载更加均衡
Elasticsearch自己管理负载均衡。但是,我们必须考虑要有多少个节点,有多少个分片和副本,并且必须在它们之间建立一定比例以实现均匀的负载分配。
此时,我们应该确保节点的数量和分片(主分片+副本)的数量是成比例的。
例如,如果集群中有5个节点,那么分片的数量应该是5的倍数。这对于Elasticsearch确保适当的负载均衡非常重要。如果节点之间存在不均衡的负载分布,那么具有更多分片的节点的资源使用率将更高,并且瞬时平均负载将高于其他节点。换句话说,其他节点上的资源将使用得更少,而具有更多分片的节点将使用得更多。
具有更多分片的节点会收到更多请求。一段时间后,这些节点将无法及时处理请求,传入的请求将在队列中等待。在这种情况下,这些节点成为系统的瓶颈,增加了所有请求的响应时间。因为传入的请求必须通过所有分片才能完成。例如下图,每个主碎片共有6个节点(DG_Data1…DG_Data6)、9个主分片(0…8)和2个副本,主分片共有18个副本。我们有6个节点和27个分片。27/6 = 4.5它不是整数。这意味着有些节点有5个分片,有些节点有4个分片。因此,与其他节点相比,节点DG_Data2、DG_Data4和DG_Data6的平均负载更高。因此,如果我们将主分片的数量增加到10个,我们将在集群中得到均匀的负载分布。
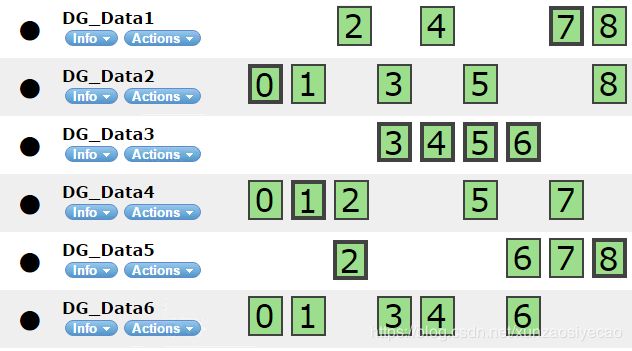
假设我们向该集群发送了一个请求。将从0到8的所有分片中搜索与该请求匹配的文档。那么将访问多少个节点?在此群集中,必须至少访问3个节点才能完成搜索请求。 Elasticsearch将确定将访问哪些节点。例如,节点将是DG_DATA1(4,7),DG_DATA2(0,1,3,5),DG_DATA5(2,6,7,8)。
我们的态度和目标应该是通过访问尽可能少的节点来完成我们的请求。
这并不意味着增加副本的数量直到访问一个节点就能完成请求,这是非常危险的。因为将数据复制到副本会浪费资源。
确定索引的行为
索引的结构及其映射(mapping)非常重要。首先,您需要确定索引是哪种索引。是大量写入还是大量读取?其次,我们应该将文档设计得尽可能平坦。数据去范式化可能是一个选择,如果我们不关心它的负面影响。如果我们无法设计平面文档,则根据索引的行为,我们可能更喜欢嵌套(nested)或子(join)文档类型。
译者注:这里的平坦/面指的是设计mapping的时候,尽量将数据打平,比如之前在关系型数据库中是关联表,在elasticsearch中应该冗余到一个文档中。
读密集型索引
如果来自索引的大多数请求都是搜索请求,我们就可以说索引是读密集型的。换句话说,搜索操作的数量大于索引操作。比如:电商中的产品的索引。一个普通的电商应用更新的产品非常少,但是大量的用户在搜索产品。
与子文档相比,嵌套文档可以提高搜索性能。但是不要忘记将数据写入嵌套文档是非常昂贵的。
增加副本的数量可以在一定程度上提高性能。在某些情况下,由于硬件的限制,性能会下降。您可以通过逐个增加副本的数量来找到这个断点。您可以使用诸如JMeter、Apache Bench ab之类的工具来度量搜索性能,同时增加副本的数量。
写密集型索引
在这些索引中,索引操作的数量大于搜索操作的数量。在包含此类索引的群集中,资源通常用于写入数据。如果增加副本的数量,则写入分片的文档将被复制到副本,因此写入过程将增加。这将导致资源使用量增加。
子文档读得快,写得慢。因此,这种类型的索引更受欢迎。
只要获取你需要的数据
只需提取所需的数据即可。检索不必要的数据会增加网络和计算的成本。不要索引不需要的数据。
在查询中尽可能有效地使用"from","size"和"source"属性。请记住,服务器在尝试写入数据时也会使用资源。
使用best_compression压缩_source数据。
监控索引大小
索引的大小可能会随时间增长,这可能要求您对集群或硬件进行一些更改。
定期Reindex索引
特别是在写密集型索引中,索引大小会随着时间增加。这是由于更新的文档。实际上,在Elasticsearch中,文档不会更新,因为它们是不可变的。因此,使用新数据创建了另一个文档,并且该文档的版本增加了一个。重新索引索引时,新索引将包含最新版本的文档。因此索引大小将减小。
强制合并
在Elasticsearch中,所有分片都是Lucene索引。Lucene索引由一个或多个文件组成。强制合并使我们可以合并这些文件并导致形成更大的段。较大的段能更有效地存储数据。
刷新间隔
刷新时间是建立索引后可搜索数据所需的时间。 这就是为什么Elasticsearch近实时,而不是实时的原因。
如果您的数据不经常更改,并且您不需要实时数据,则应增加或不使用刷新间隔。 如果您根本不希望刷新,则可以将其分配为-1。刷新是一项昂贵的任务。 较小的刷新时间可能会对搜索性能产生不利影响。
初始索引时,应将刷新间隔设置为-1。
作为一种选择,您可以在建立文档索引时发送刷新参数。 与刷新整个索引不同,只刷新该文档更有效。
PUT /test/_doc/1?refresh
{
"test": "test"
}
译者注:refresh_interval设置为-1,并不意味着不进行进行refresh操作。
优先过滤上下文而不是查询
如果您在搜索中不需要评分功能,请避免使用查询。 您应该首选过滤器上下文。 由于过滤器已缓存且不会影响得分,因此比查询要快。
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/query-filter-context.html
初始索引时禁用副本
索引文档时,首先将其写入主分片,然后将其复制到副本。复制到副本是一个代价高昂的操作,它限制了初始索引。因此,您应该禁用副本,直到初始索引完成。
使用批量请求
在索引操作中发送批量请求,尤其是在初始索引中。 批量请求比单个请求具有更好的性能。 请注意,请求限制为100 MB。
监控您的集群和查询
您应该使用性能监视工具(例如New Relic)监视集群,该工具具有Elasticsearch插件。 您可以检查节点的异常行为,平均负载,响应时间以及更改的影响。 通过_profiling API运行已识别的搜索,以查看各个组件的耗时。
将ElasticClient对象用作Singleton
建议在应用程序的生命周期内使用单个客户端和连接设置实例。 客户端是线程安全的,因此可以跨线程共享实例。 从单例中受益的实际移动部分是ConnectionSettings,因为缓存是按ConnectionSettings进行的。
https://www.elastic.co/guide/en/elasticsearch/client/net-api/current/lifetimes.html
首选去范式化而不是嵌套类型(Nested Type)
如果您对查询进行概要分析,则可以确定将嵌套文档与父文档连接在一起是否需要花费大量时间。 在这种情况下,像在Vivek Mittal的情况下一样,非范式化可以提高性能。 我在下面分享了作为参考。
https://blog.gojekengineering.com/elasticsearch-the-trouble-with-nested-documents-e97b33b46194
结论
在我看来,在elasticsearch,数据索引和搜索上创建索引非常简单。 困难的部分是性能和设计。 在本文中,我想与您分享我的经验。 尽管我不希望您回答所有问题,但这将提供一个起点。 我的建议是根据此处的信息测试所有内容,以找到适合您的最佳配置。 相信我,即使花费时间,您也会找到理想的解决方案。
译者:
对于集群规模的确定,以写入密集型来看,应该可以通过业务量的预估确定想要的吞吐量,吞吐量/单台机器写入速度=》需要的节点数。
与kafka集群节点数量预估类似,不过kafka集群还需要考虑consumer的消费能力。
个人微信公众号:

个人博客
https://jiankunking.com
作者:jiankunking 出处:http://blog.csdn.net/jiankunking