新闻网日志实时分析可视化系统项目
本次项目是基于企业大数据经典案例项目(大数据日志分析),全方位、全流程讲解 大数据项目的业务分析、技术选型、架构设计、集群规划、安装部署、整合继承与开发和web可视化交互设计。
项目代码托管于github,大家可以自行下载。
一、业务需求分析
- 捕获用户浏览日志信息
- 实时分析前20名流量最高的新闻话题
- 实时统计当前线上已曝光的新闻话题
- 统计哪个时段用户浏览量最高
- 生成报表(给销售人员以及Boss参考)
二、系统架构图设计

三、系统数据流程设计

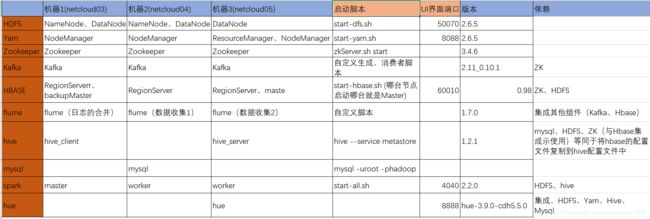
四、集群资源规划设计

五、步骤详解
考虑到实际情况,本人集群配置共三个节点(netcloud03、netcloud04、netcloud05)。
1. Zookeeper分布式集群部署
参考博客
2. Hadoop2.X HA架构与部署
Hadoop 版本选择:
(1)基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进。
(2)基于Cloudera厂商的cdh版本,Cloudera有免费版和企业版, 企业版只有试用期。不过cdh大部分功能都是免费的。
需要配置的文件(6个文件):
1)修改 hadoo-env.sh(配置java环境变量)、2)修改 hdfs-site.xml (nameservice配置,HA的NameNode,jounalNode、副本数目)、3)修改 core-site.xml (指定NameService) 4)修改mapred-site.xml (指定mr框架为yarn方式)、5)修改yarn-site.xml (指定resourcemanager地址,指定zk集群地址 )6)修改slaves
参考 hadoop原始版本安装博客、cdh版本安装
3. HBase分布式集群部署与设计
参考博客
4. Kafka分布式集群部署
参考博客
5. Flume部署及数据采集准备
netcloud03节点用作netcloud04与netcloud05节点的数据合并。
netcloud04节点flume的配置如下:
1)重命名 conf/flume-env.sh.template 为 flume-env.sh
重命名 conf/flume-conf.properties.template 为 flume-conf
2) 在flume-env.sh 中配置JDK安装目录
3) 在flume-conf 中配置
a2.sources = r1
a2.sinks = k1
a2.channels = c1
#source的配置
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /opt/data/weblog-flume.log
a2.sources.r1.channels = c1
#channel的配置
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 1000
a2.channels.c1.keep-alive = 5
#type为avro 表示数据不存储到磁盘而是到 netcloud03节点
a2.sinks.k1.type = avro
a2.sinks.k1.channel = c1
a2.sinks.k1.hostname = netcloud03
a2.sinks.k1.port = 5555
netcloud05节点flume的配置如下:
1)重命名 conf/flume-env.sh.template 为 flume-env.sh
重命名 conf/flume-conf.properties.template 为 flume-conf
2) 在flume-env.sh 中配置JDK安装目录
3) 在flume-conf 中配置 a3为agent的别名 也可以使用官方的默认的值
a3.sources = r1
a3.sinks = k1
a3.channels = c1
#source的配置
a3.sources.r1.type = exec
a3.sources.r1.command = tail -F /opt/data/weblog-flume.log
a3.sources.r1.channels = c1
#channel的配置
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 1000
a3.channels.c1.keep-alive = 5
#type为avro 表示数据不存储到磁盘而是到 netcloud03节点
a3.sinks.k1.type = avro
a3.sinks.k1.channel = c1
a3.sinks.k1.hostname = netcloud03
a3.sinks.k1.port = 5555
netcloud04和netcloud05节点可以实时的从磁盘weblog-flume.log 文件中收集数据(模拟程序向文件中生成数据)
netcloud03节点的配置如下
6. Flume+HBase+Kafka集成与开发
版本兼容问题
Flume 1.7.0+Kafka2.11_0.9.0
1. 下载Flume源码并导入Idea开发工具
1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压
2)通过idea导入flume源码
打开idea开发工具,选择File——》Open
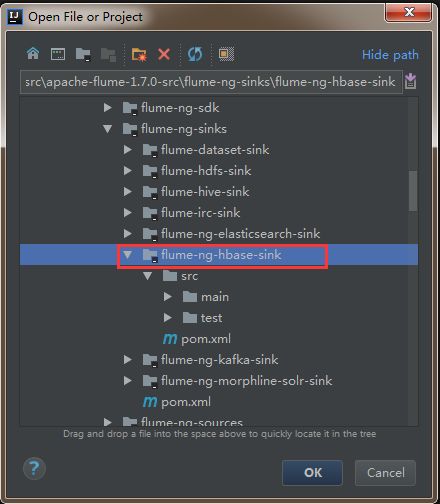
然后找到flume源码解压文件,选中flume-ng-hbase-sink,点击ok加载相应模块的源码。
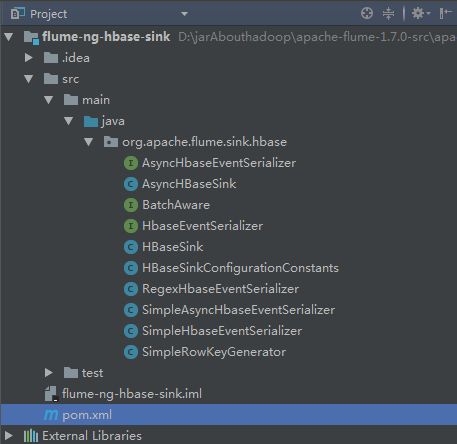
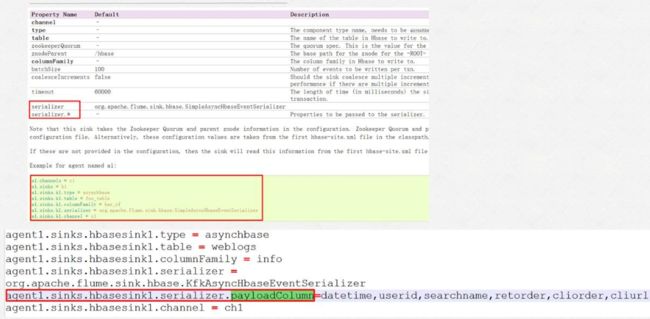
2. 官方flume与hbase集成的参数介绍
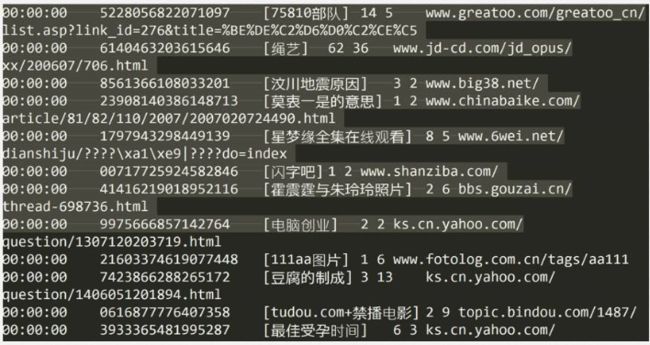
3. 下载日志数据并分析
到搜狗实验室下载用户查询日志
1)介绍
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。为进行中文搜索引擎用户行为分析的研究者提供基准研究语料。
2)格式说明
数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID
4. netcloud03聚合节点与HBase和Kafka的集成配置
netcloud03通过flume接收netcloud04与netcloud05中flume传来的数据,并将其分别发送至hbase与kafka中,配置内容如下
a1.sources = r1
a1.channels = kafkaC hbaseC
a1.sinks = kafkaSink hbaseSink
a1.sources.r1.type = avro
a1.sources.r1.channels = hbaseC kafkaC
a1.sources.r1.bind = netcloud03
a1.sources.r1.port = 5555
a1.sources.r1.threads = 5
#****************************flume + hbase******************************
a1.channels.hbaseC.type = memory
a1.channels.hbaseC.capacity = 10000
a1.channels.hbaseC.transactionCapacity = 10000
a1.channels.hbaseC.keep-alive = 20
a1.sinks.hbaseSink.type = asynchbase
a1.sinks.hbaseSink.table = weblogs
a1.sinks.hbaseSink.columnFamily = info
a1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
a1.sinks.hbaseSink.channel = hbaseC
a1.sinks.hbaseSink.serializer.payloadColumn = datetime,userid,searchname,retorder,cliorder,cliurl
#****************************flume + kafka******************************
a1.channels.kafkaC.type = memory
a1.channels.kafkaC.capacity = 10000
a1.channels.kafkaC.transactionCapacity = 10000
a1.channels.kafkaC.keep-alive = 20
a1.sinks.kafkaSink.channel = kafkaC
a1.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafkaSink.brokerList = netcloud03:9092,netcloud04:9092,netcloud05:9092
a1.sinks.kafkaSink.topic = weblogs
a1.sinks.kafkaSink.zookeeperConnect = node5:2181,node6:2181,node7:2181
a1.sinks.kafkaSink.requiredAcks = 1
a1.sinks.kafkaSink.batchSize = 1
a1.sinks.kafkaSink.serializer.class = kafka.serializer.StringEncoder
5. 对日志数据进行格式处理
1)将文件中的tab更换
cat weblog.log|tr "\t" "," > weblog2.log
2)将文件中的空格更换成逗号
cat weblog2.log|tr " " "," > weblog.log
6. 自定义SinkHBase程序设计与开发
1)模仿SimpleAsyncHbaseEventSerializer自定义KfkAsyncHbaseEventSerializer实现类,修改一下代码即可
/**
* 自定义
*/
public class KfkAsyncHbaseEventSerializer implements AsyncHbaseEventSerializer {
// 表名
private byte[] table;
// 列族
private byte[] cf;
// 列值
private byte[] payload;
// 列名
private byte[] payloadColumn;
private byte[] incrementColumn;
// 行键前缀
private String rowPrefix;
private byte[] incrementRow;
// 生成行键的方式
private KeyType keyType;
/*初始化的时候就得到表名和列簇名*/
@Override
public void initialize(byte[] table, byte[] cf) {
this.table = table;
this.cf = cf;
}
/*执行的方法*/
@Override
public List getActions() {
List actions = new ArrayList();
if (payloadColumn != null) {
byte[] rowKey;
try {
/*---------------------------代码修改开始---------------------------------*/
// 解析列字段 a1.sinks.hbaseSink.serializer.payloadColumn = datetime,userid,searchname,retorder,c
String[] columns = new String(payloadColumn).split(",");
// 解析flume采集过来的每行的值
String[] values = new String(payload).split(",");
for (int i = 0; i < columns.length; i++) {
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(Charsets.UTF_8);
// 数据校验:字段和值是否对应
if (columns.length != values.length) break;
String datetime = values[0].toString();
String userId = values[1].toString();
rowKey = SimpleRowKeyGenerator.getKfkRowKey(userId, datetime);//获取自定义RowKey
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
/*---------------------------代码修改结束---------------------------------*/
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
} 2)在SimpleRowKeyGenerator类中,根据具体业务自定义Rowkey生成方法
// 根据业务需求自定义rowKey
public static byte[] getKfkRowKey(String userId, String datetime) throws UnsupportedEncodingException {
return (userId + datetime + String.valueOf(System.nanoTime())).getBytes("UTF8");
}3) 执行命令打包:mvn install -Dmaven.test.skip=true
4) 镜像添加:
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
7. 自定义编译程序打jar包
1)在idea工具中,选择File——》ProjectStructrue
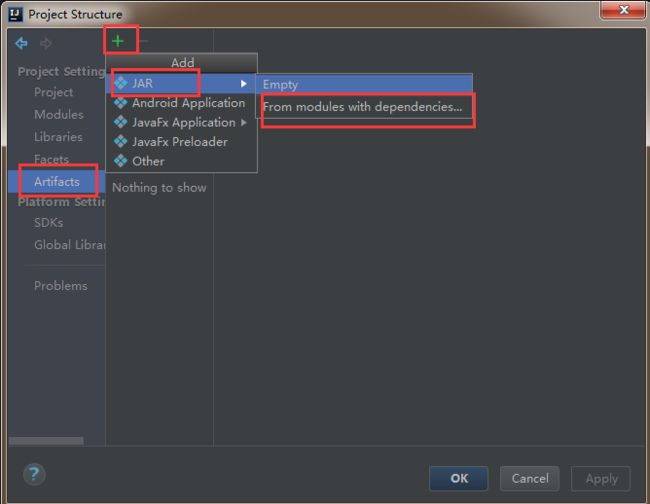
2)左侧选中Artifacts,然后点击右侧的+号,最后选择JAR——》From modules with dependencies
3)然后直接点击ok
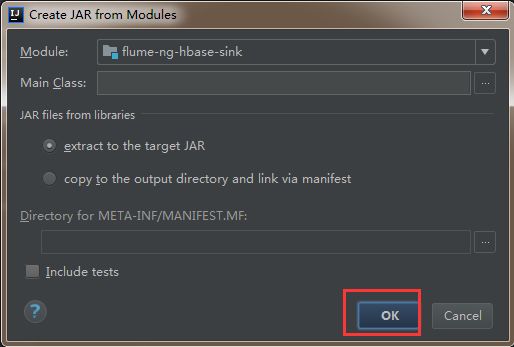
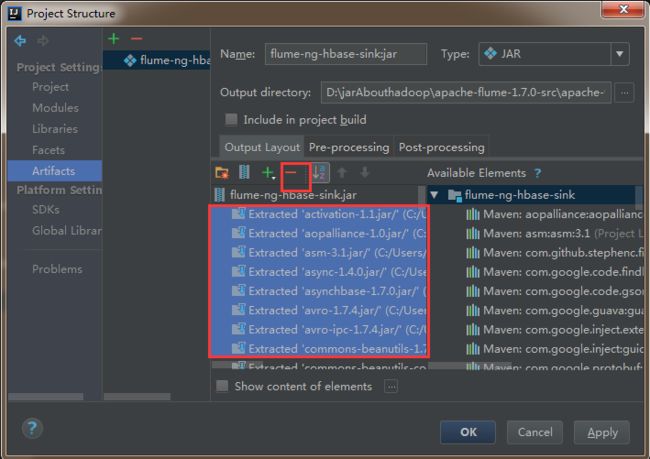
4)删除其他依赖包,只把flume-ng-hbase-sink打成jar包就可以了。
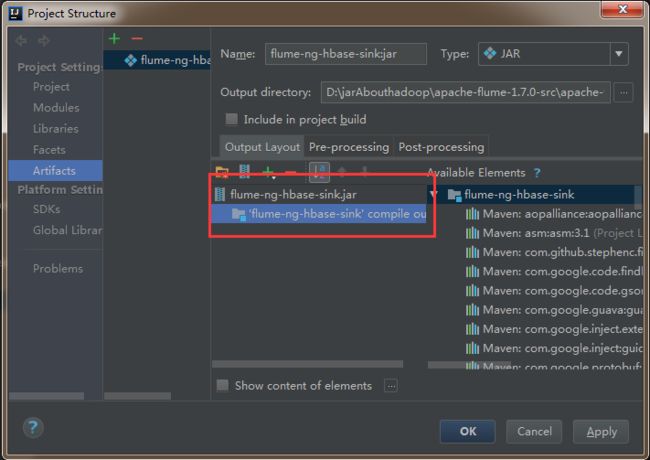
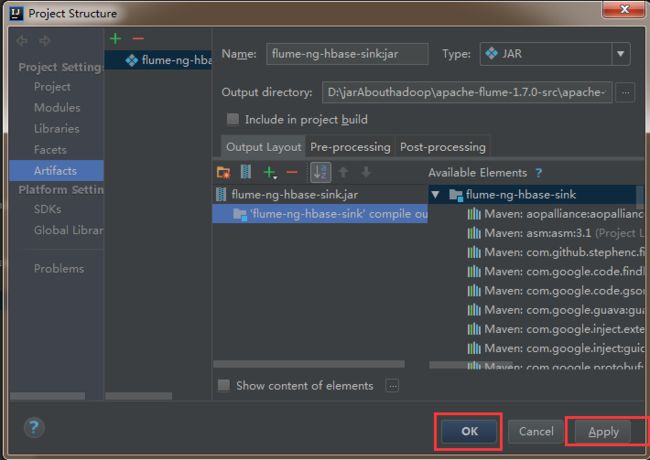
5)然后依次点击apply,ok
6)点击build进行编译,会自动打成jar包
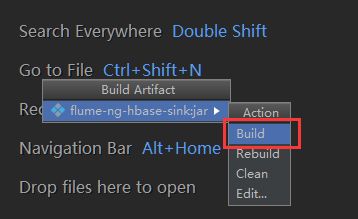
7)到项目的apache-flume-1.7.0-src\flume-ng-sinks\flume-ng-hbase-sink\classes\artifacts\flume_ng_hbase_sink_jar目录下找到刚刚打的jar包
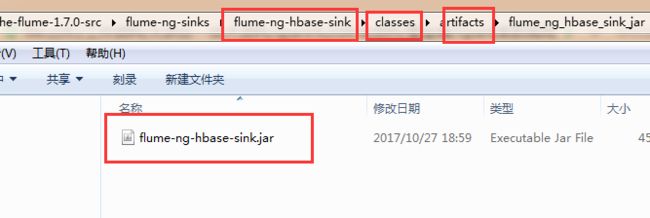
8)将打包名字替换为flume自带的包名flume-ng-hbase-sink-1.7.0.jar ,然后上传至flume/lib目录下,覆盖原有的jar包即可。
7. 数据采集/存储/分发完整流程测试
1. 在idea开发工具中构建weblogs项目,编写数据生成模拟程序。
package com.example.weblogs;
import java.io.*;
public class ReadWrite {
static String readFileName;
static String writeFileName;
public static void main(String args[]) {
readFileName = args[0];
writeFileName = args[1];
try {
// readInput();
readFileByLines(readFileName);
} catch (Exception e) {
}
}
public static void readFileByLines(String fileName) {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
String tempString = null;
try {
System.out.println("以行为单位读取文件内容,一次读一整行:");
fis = new FileInputStream(fileName);// FileInputStream
// 从文件系统中的某个文件中获取字节
isr = new InputStreamReader(fis, "GBK");
br = new BufferedReader(isr);
int count = 0;
while ((tempString = br.readLine()) != null) {
count++;
// 显示行号
Thread.sleep(300);
String str = new String(tempString.getBytes("UTF8"), "GBK");
System.out.println("row:" + count + ">>>>>>>>" + tempString);
method1(writeFileName, tempString);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (isr != null) {
try {
isr.close();
} catch (IOException e1) {
}
}
}
}
public static void method1(String file, String conent) {
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file, true)));
out.write("\n");
out.write(conent);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2. 参照前面idea工具项目打包方式,将该项目打成weblogs.jar包,然后上传至netcloud03节点的/usr/local/data/jars目录下(目录需要提前创建)
3. 将weblogs.jar分发到另外两个节点(netcloud04和netcloud05) 修改权限 : chmod 777 weblogs.jar
1)在另外两个节点上分别创建/usr/local/data/jars目录
mkdir /usr/local/data/jars
2)将weblogs.jar分发到另外两个节点
scp weblogs.jar netcloud04:/usr/local/data/jars
scp weblogs.jar netcloud05:/usr/local/data/jars
4. 编写运行模拟程序的shell脚本
在netcloud04和netcloud05节点的/usr/local/data/目录下,创建weblog-shell.sh脚本。内容为
#/bin/bash
echo "start log......"
#第一个参数是原日志文件,第二个参数是日志生成输出文件
java -jar /usr/local/data/jars/weblogs.jar /usr/local/data/weblog.log /usr/local/data/weblog-flume.log
修改weblog-shell.sh可执行权限
chmod 777 weblog-shell.sh
5. 编写启动flume服务程序的shell脚本
在各节点的flume安装目录下编写flume启动脚本flume-kfk-start.sh。
下面是netcloud03中的配置写法,netcloud04与netcloud05中将a1分别改为a2和a3。
#/bin/bash
echo "flume-1 start ......"
bin/flume-ng agent --conf conf -f conf/flume-conf -n a1 -Dflume.root.logger=INFO,console
6. 编写Kafka Consumer执行脚本kfk-test-consumer.sh。
#/bin/bash
echo "kfk-kafka-consumer.sh start......"
bin/kafka-console-consumer.sh --zookeeper netcloud03:2181,netcloud04:2181,netcloud05:2181 --from-beginning --topic weblogs
7. 将kfk-test-consumer.sh脚本分发另外两个节点
scp kfk-test-consumer.sh netcloud04:/usr/local/kafka_2.10/
scp kfk-test-consumer.sh netcloud05:/usr/local/kafka_2.10/
8. 启动模拟程序并测试
在netcloud04节点启动日志产生脚本,模拟产生日志是否正常。
/usr/local/data/weblog-shell.sh
9. 启动数据采集所有服务
1)启动Zookeeper服务 zkServer.sh start
2)启动hdfs服务 start-dfs.sh start-yarn.sh
3)启动HBase服务 start-hbase.sh
创建hbase业务表
create 'weblogs','info'
4)3台机器启动Kafka服务,并在netcloud03节点创建业务数据topic
bin/kafka-server-start.sh config/server.properties &
bin/kafka-topics.sh --create --zookeeper netcloud03:2181,netcloud04:2181,netcloud05:2181 --topic weblogs --partitions 1 --replication-factor 3
10. 完成数据采集全流程测试
1)在netcloud04和netcloud05节点上完成数据采集。
(1)使用shell脚本模拟日志产生
cd /usr/local/data
./weblog-shell.sh
(2)netcloud04、netcloud05 启动flume采集日志数据发送给聚合节点
2)在netcloud03节点上启动flume聚合脚本,将采集的数据分发到Kafka集群和hbase集群。(Hbase相关类找不到异常,将 Hbase的jar包拷贝到 flume的lib下)
./flume-kfk-start.sh
3)启动Kafka Consumer查看flume日志采集情况
bin/kafka-console-consumer.sh --zookeeper netcloud03:2181,netcloud04:2181,netcloud05:2181 --from-beginning --topic weblogs
4)查看hbase数据写入情况
./hbase-shell
scan 'weblogs
8. MySQL安装
参考博客、ysj博客
9. Hive与HBase集成进行数据分析
1. Hive安装(本地mysql模式),参考博客
2. Hive与HBase集成
1)在hive-site.xml文件中配置Zookeeper,hive通过这个参数去连接HBase集群。也可以将Hbase的配置文件复制到hive的配 置文件目录下
2)将hbase的9个包拷贝到hive/lib目录下。如果是CDH版本,已经集成好不需要导包。
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.0
export HIVE_HOME=/opt/modules/hive-0.13.1/lib
ln -s $HBASE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/htrace-core-2.04.jar$HIVE_HOME/lib/htrace-core-2.04.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compact-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-hadoop2-compact-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compact-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-hadoop-compact-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/lib/high-scale-lib-1.1.1.jar
ln -s $HBASE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar
3)在hive中创建与hbase集成的外部表
CREATE EXTERNAL TABLE weblogs(
id string,
datetime string,
userid string,
searchname string,
retorder string,
cliorder string,
cliurl string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping"=
":key,info:datetime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl")
TBLPROPERTIES("hbase.table.name"="weblogs");
#查看hbase数据记录
select count(*) from weblogs;
4)netcloud05节点启动hive
执行 命令:hive --service metastore
netcloud03节点启动客户端
执行命令 :hive命令
10. Cloudera HUE大数据可视化分析
参考博客
11. Spark2.X环境准备、编译部署及运行
源码编译的方式参考博客;
预编译安装的方式搭建spark集群参考博客
基于yarn方式的任务的提交,只需要安装一个spark节点用作任务提交。
修改配置文件 spark-env.sh 但是slaves可以不做修改。也不需要启动spark服务
export JAVA_HOME=/opt/java
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_IP=netcloud02
export SPARK_WORKER_MEMORY=1G
export SPARK_MASTER_PORT=7077
spark与hive集成的时候(spark程序中创建hive表以及加载查询数据)
需要将hive conf目录下的hive-site.xml 复制到 spark/conf 目录下
同时在 spark-env.sh 中添加hive的安装目录
export HIVE_HOME=/opt/hive
提交任务的是报错信息 java.lang.NoClassDefFoundError: scala/Product$class 这可能是安装的版本和程序编译版本不一致造成。
12. Spark SQL快速离线数据分析
1. Spark SQL 与Hive集成(spark-shell),参考博客
2. Spark SQL 与Hive集成(spark-sql),参考博客
3. Spark SQL之ThriftServer和beeline使用,参考博客
4. Spark SQL与MySQL集成,参考博客
5. Spark SQL与HBase集成,参考博客
13. Structured Streaming业务数据实时分析
1、NC服务安装
在netcoud05节点下安装nc服务: yum install -y nc
在netcloud03节点下词频统计执行命令: bin/run-example --master local[2 ] streaming.NetworkWordCount netcloud05 9999
将spark conf 目录下的log4j.properties 文件的日志级别改为WARN 避免打印出过多的日志信息。
2、SparkStreaming读取socket流数据 在IDEA程序执行
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("HdfsTest")
.getOrCreate()
val ssc = new StreamingContext(spark.sparkContext,Seconds(5));
val lines = ssc.socketTextStream("netcloud05", 9999)
val words = lines.flatMap(_.split(" "))
}
}上面的程序可以在本地执行,也可以将程序打包通过集群执行。
3、SparkStreaming结果存储到外部数据库中。
object TestStreaming {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate()
val sc =spark.sparkContext
val ssc = new StreamingContext(sc, Seconds(5))
val lines = ssc.socketTextStream("netcloud05", 9999)
val words = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
words.foreachRDD(rdd => rdd.foreachPartition(line => {
Class.forName("com.mysql.jdbc.Driver")
val conn = DriverManager
.getConnection("jdbc:mysql://node5:3306/test","root","1234")
try{
for(row <- line){
val sql = "insert into webCount(titleName,count)values('"+row._1+"',"+row._2+")"
conn.prepareStatement(sql).executeUpdate()
}
}finally {
conn.close()
}
}))
ssc.start()
ssc.awaitTermination()
}
}4.sparkStreaming 与kafka集成
1)Maven引入相关依赖:spark-streaming-kafka
2)编写测试代码并启动运行
object StreamingKafka8 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate()
val sc =spark.sparkContext;
val ssc = new StreamingContext(sc, Seconds(5))
// Create direct kafka stream with brokers and topics
val topicsSet =Set("weblogs")
val kafkaParams = Map[String, String]("metadata.broker.list" -> "netcloud03:9092")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
val lines = kafkaStream.map(x => x._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
3)启动Kafka服务并测试生成数据
bin/kafka-server-start.sh config/server.properties
bin/kafka-console-producer.sh --broker-list bigdata-pro01.kfk.com --topic weblogs
5、Structured Streaming 读取Socket 进行单词统计
scala> :paste
// Entering paste mode (ctrl-D to finish)
val lines = spark.readStream
.format("socket")
.option("host", "netcloud05")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
输出的结果值 是单词的聚合值
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+
...输出模式是update的情况 输出的结果值 是单词的输入新值的统计结果,不包括之前的计算值。
.outputMode("update")
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|hadoop| 1|
+------+-----+
...5. Structured Streaming与kafka集成
1)Structured Streaming是Spark2.2.0新推出的,要求kafka的版本0.10.0及以上。集成时需将如下的包拷贝到Spark的jar包目录下。
kafka_2.11-0.10.1.0.jar
kafka-clients-0.10.1.0.jar
spark-sql-kafka-0-10_2.11-2.2.0.jar
spark-streaming-kafka-0-10_2.11-2.1.0.jar
2)与kafka集成代码
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "netcloud03:9092")
.option("subscribe", "weblogs")
.load()
import spark.implicits._
val lines = df.selectExpr("CAST(value AS STRING)").as[String]
val words = lines.flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
3)在netcloud03节点启动kafka生产者 输入数据
6. Structured Streaming与MySQL集成
1)mysql创建相应的数据库和数据表,用于接收数据
create database test;
use test;
CREATE TABLE `webCount` (
`titleName` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`count` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2)与mysql集成代码
/**
* 结构化流从kafka中读取数据存储到关系型数据库mysql
* 目前结构化流对kafka的要求版本0.10及以上
*/
object StructuredStreamingKafka {
case class Weblog(datatime:String,
userid:String,
searchname:String,
retorder:String,
cliorder:String,
cliurl:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate()
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "netcloud03:9092") //从哪台服务器接收
.option("subscribe", "weblogs")
.load()
import spark.implicits._
val lines = df.selectExpr("CAST(value AS STRING)").as[String]
val weblog = lines.map(_.split(","))
.map(x => Weblog(x(0), x(1), x(2),x(3),x(4),x(5)))
val titleCount = weblog
.groupBy("searchname").count().toDF("titleName","count")
val url ="jdbc:mysql://netcloud04:3306/test"
val username="root"
val password="hadoop"
val writer = new JDBCSink(url,username,password)
val query = titleCount.writeStream
.foreach(writer)
.outputMode("update")
.trigger(ProcessingTime("5 seconds"))
.start()
query.awaitTermination()
}
/**
* 处理从StructuredStreaming中向mysql中写入数据
*/
class JDBCSink(url: String, username: String, password: String) extends ForeachWriter[Row] {
var statement: Statement = _
var resultSet: ResultSet = _
var connection: Connection = _
override def open(partitionId: Long, version: Long): Boolean = {
connection = new MySqlPool(url, username, password).getJdbcConn()
statement = connection.createStatement()
return true
}
override def process(value: Row): Unit = {
val titleName = value.getAs[String]("titleName").replaceAll("[\\[\\]]", "")
val count = value.getAs[Long]("count")
val querySql = "select 1 from webCount " +
"where titleName = '" + titleName + "'"
val updateSql = "update webCount set " +
"count = " + count + " where titleName = '" + titleName + "'"
val insertSql = "insert into webCount(titleName,count)" +
"values('" + titleName + "'," + count + ")"
try {
//查看连接是否成功
var resultSet = statement.executeQuery(querySql)
if (resultSet.next()) {
statement.executeUpdate(updateSql)
} else {
statement.execute(insertSql)
}
} catch {
case ex: SQLException => {
println("SQLException")
}
case ex: Exception => {
println("Exception")
}
case ex: RuntimeException => {
println("RuntimeException")
}
case ex: Throwable => {
println("Throwable")
}
}
}
override def close(errorOrNull: Throwable): Unit = {
// if(resultSet.wasNull()){
// resultSet.close()
// }
if (statement == null) {
statement.close()
}
if (connection == null) {
connection.close()
}
}
}7. Structured Streaming向mysql数据库写入中文乱码解决
修改数据库文件my.cnf(linux下)
[client]
socket=/var/lib/mysql/mysql.sock //添加
default-character-set=utf8 //添加
[mysqld]
character-set-server=utf8 //添加
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
14. 大数据Web可视化分析系统开发
1. 基于业务需求的WEB系统设计(具体参照代码)
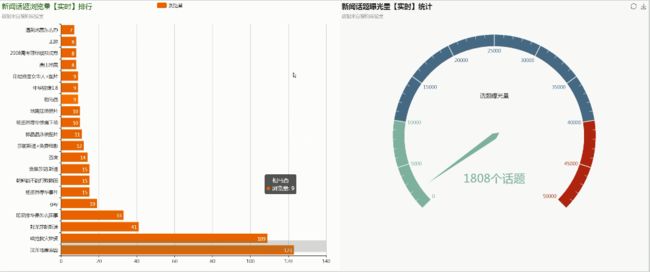
2. 基于Echart框架的页面展示层开发
1)echart、JQuery下载
2)页面效果图选取及代码实现
3. 工程编译并打包发布
参照之前将的idea打包方式,将spark web项目(scala)打包发布提交到spark集群执行。
4. 启动各个服务
1)启动zookeeper: zkServer.sh start
2)启动hadoop: start-all.sh
3)启动hbase: start-hbase
4)启动mysql: service mysqld start
5)netcloud05(netcloud04)启动flume: flume-kfk-start.sh,将数据发送到netcloud03中
6)netcloud03启动flume: flume-kfk-start.sh,将数据分别传到hbase和kafka中
7)启动kafka-0.10(最好三台都启动,不然易出错):
bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &
8)启动netcloud05(netcloud04)中的脚本:weblog-shell.sh
9)启动 StructuredStreamingKafka来从kafka中取得数据,处理后存到mysql中
10)启动web项目(sparkStu),该项目会从mysql数据库中读取数据展示到页面
5. 最终项目运行效果