编写一只有下载进度条的爬虫
编写一只有下载进度条的爬虫
- 前言:
- 一、你需要知道的
- 二、实现思路
- 三、实现代码
前言:
一般在使用爬虫爬取一些数据的时候,我们一般不关注其爬取数据的过程,当程序运行结束之后我们去看结果就行了,但当我们想要知道每条数据爬取的进度的时候该如何处理呢?本次博客就为大家分享如何实现一只有下载进度条的小爬虫
一、你需要知道的
在这之前,我们需要先了解一些新的知识内容
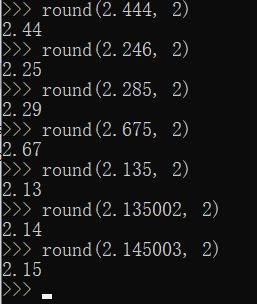
- round( x [, n] ) : 返回一个浮点数的四舍五入值。round(x) 参数代表返回浮点数x的四舍五入的值,round(x,n) 代表返回浮点数x的四舍五入的小数点后的n位数值
round(x)的实例如下图:

round(x,n)的实例如下图:
- 在要下载的视频网页的原页面中都包含一个“content-length”字段,此字段声明了视频内容的大小,我们需要取出该字段的值
- iter_content : 下载流时,python提供此方法来使留直接下载到硬盘中,它接收一个块大小的参数,iter_content(chunk_size=)
二、实现思路
- 获取到视频下载页面的“content-length”的大小,此时获取到值的单位是byte,假定为:video_size
- 我们假定一个下载操作的数据块大小是1024(byte),假定为:chunk_size
- 所以我们可以根据我们设定的块大小算出视频有多少MB,算法是:str(round(float(video_size / chunk_size / 1024), 4)) + “[MB]”)
- 我们设定一个变量size,初始值为0,用来接收已经下载的视频大小,然后通过"int(size / video_size * 100) * “>”" 来不断的根据当前下载的视频大小输入">"符号,表示当前进度
- 再通过""【" + str(round(float(size / video_size) * 100, 2)) + “%” + “】”"来表示百分比进度
三、实现代码
一下就贴上实现进度条的部分的代码,供大家参考:
def save_video():
video = requests.get(url=download, headers=header, stream=True)
# Setting per chunk size is 1024
chunk_size = 1024
# Get size of video that will be download
size = 0
# name = "".join(random.sample(string.digits, 4))
video_size = int(video.headers['content-length'])
print("Start to download number %d video" % (k+1))
print("Video size is : " + str(round(float(video_size / chunk_size / 1024), 4)) + "[MB]")
print("\n")
with open(storage_path + os.sep + "%s.mp4" % name_list[k], "wb") as v:
for data in video.iter_content(chunk_size=chunk_size):
v.write(data)
size = len(data) + size
print('\r' + "Downloading : " + int(size / video_size * 100) * ">" + "【" + str(
round(size / chunk_size / 1024, 2))
+ "MB】" + "【" + str(round(float(size / video_size) * 100, 2)) + "%" + "】", end="") # 加上end表示运行完后不换行
# print("\n")
start = datetime.datetime.now()
print("Start download...")
save_video()
print("\n Download End...")
end = datetime.datetime.now()
print("Spend Times:" + str(end - start).split('.')[0] + " Seconds")