Java学习总结之Java IO系统(二)
本文接着Java学习总结之Java IO系统(一),我们继续总结Java IO系统的相关知识。
字符流(Writer、Reader)
Java提供了两个操作字符的字符流基类,分别是Writer和Reader。先来了解两个用于读写文件的字符流FileReader(字符输入流)和FileWriter(字符输出流):
FileReader
FileReader类从InputStreamReader类继承而来。该类按字符读取流中数据。可以通过以下几种构造方法创建需要的对象。
在给定从中读取数据的 File 的情况下创建一个新 FileReader。
FileReader(File file)
在给定从中读取数据的 FileDescriptor 的情况下创建一个新 FileReader。
FileReader(FileDescriptor fd)
在给定从中读取数据的文件名的情况下创建一个新 FileReader。
FileReader(String fileName)
创建FIleReader对象成功后,可以参照以下列表里的方法操作文件。

FileWriter
FileWriter 类从 OutputStreamWriter 类继承而来。该类按字符向流中写入数据。可以通过以下几种构造方法创建需要的对象。
在给出 File 对象的情况下构造一个 FileWriter 对象。
FileWriter(File file)
在给出 File 对象的情况下构造一个 FileWriter 对象。
FileWriter(File file, boolean append)
构造与某个文件描述符相关联的 FileWriter 对象。
FileWriter(FileDescriptor fd)
在给出文件名的情况下构造 FileWriter 对象,它具有指示是否挂起写入数据的 boolean 值。
FileWriter(String fileName, boolean append)
创建FileWriter对象成功后,可以参照以下列表里的方法操作文件。
 字符流的操作比字节流操作方便一点,就是可以直接输出字符串。不在用再像之前那样进行字节转换操作了。使用字符流默认情况下依然是覆盖已有的文件,如果想追加的话,则直接在FileWriter上增加一个可追加的标记即可。
字符流的操作比字节流操作方便一点,就是可以直接输出字符串。不在用再像之前那样进行字节转换操作了。使用字符流默认情况下依然是覆盖已有的文件,如果想追加的话,则直接在FileWriter上增加一个可追加的标记即可。
下面的例子演示了FileReader和FileWriter的使用
import java.io.*;
public class FileRead{
public static void main(String args[])throws IOException{
File file = new File("Hello1.txt");
// 创建文件
file.createNewFile();
// creates a FileWriter Object
FileWriter writer = new FileWriter(file);
// 向文件写入内容
writer.write("This\n is\n an\n example\n");
writer.flush();
writer.close();
//创建 FileReader 对象
FileReader fr = new FileReader(file);
char [] a = new char[50];
fr.read(a); // 从数组中读取内容
for(char c : a)
System.out.print(c); // 一个个打印字符
fr.close();
}
}
字节-字符转换流(OutputStreamWriter、InputStreamReader)
在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类。
InputStreamReader
InputStreamReader是字节流通向字符流的桥梁,它使用指定的charset读取字节并将其解码为字符。它拥有一个InputStream类型的变量,并继承了Reader,使用了对象的适配器模式,如图所示:

根据InputStream的实例创建InputStreamReader的方法有4种:
1.根据默认字符集创建
InputStreamReader(InputStream in)
2.使用给定字符集创建
InputStreamReader(InputStream in, Charset cs)
3.使用给定字符集解码器创建
InputStreamReader(InputStream in, CharsetDecoder dec)
4.使用指定字符集名字符串创建
InputStreamReader(InputStream in, String charsetName)
后面的3个构造函数都制定了一个字符集,最后一个是最简单的,可以直接指定字符集的名称来创建,例如UTF-8等。
注意:在对文件进行读写操作时,默认使用的是项目的编码,如果要读写其他编码方式的文件,要在构造输入输出流时指定对应的编码。这一般通过字节-字符转换流完成。
每次调用InputStreamReader中的一个read()方法都会导致从底层输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从底层流读取更多的字节,使其超过满足当前读取操作所需的字节。共有3个可用的read()方法:
int read(); //读取单个字符
int read(char[] cbuf, int offset, int length);
//将字符读入数组中的某一部分
boolean ready(); //判断此流是否已经准备好用于读取
使用字符流的形式读取字节流的文件,代码如下:
import java.io.* ;
public class InputStreamReaderDemo01{
public static void main(String args[]) throws Exception{
File f = new File("d:" + File.separator +
"test.txt") ;
Reader reader = new InputStreamReader
(new FileInputStream(f)) ;
// 将字节流变为字符流
char c[] = new char[1024] ;
int len = reader.read(c) ; // 读取
reader.close() ; // 关闭
System.out.println(new String(c,0,len)) ;
}
};
OutputStreamWriter
OutputStreamWriter是字符流通向字节流的桥梁,可使用指定的charset将要写入流中的字符编码成字节。因此,它拥有一个OutputStream类型的变量,并继承了Writer,使用对象的适配器模式,如图所示:
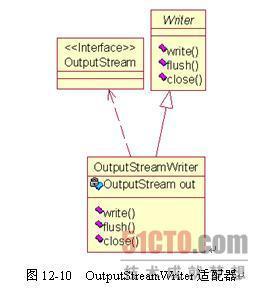
根据OutputStream的实例创建OutputStreamWriter的方法有4种:
1.根据默认字符集创建
OutputStreamReader(OutputStream out)
2.使用给定字符集创建
OutputStreamReader(OutputStream out, Charset cs)
3.使用给定字符集解码器创建
OutputStreamReader(OutputStream out, CharsetDecoder dec)
4.使用指定字符集名字符串创建
OutputStreamReader(OutputStream out, Stroutg charsetName)
后面的3个构造函数都制定了一个字符集,最后一个是最简单的,可以直接指定字符集的名称来创建,例如UTF-8等。
每次调用write()方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积。可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。注意,传递给write()方法的字符没有缓冲。共有3个可用的write()方法:
void write(char[] cbuf, int off, int len); //写入字符数组的某一部分
void write(int c); //写入单个字符
void write(String str, int off, int len); //写入字符串的某一部分
例如:将字节的文件输出流,以字符的形式输出。代码如下:
import java.io.* ;
public class OutputStreamWriterDemo01{
public static void main(String args[]) throws Exception{
File f = new File("d:" + File.separator + "test.txt");
Writer out = new OutputStreamWriter
(new FileOutputStream(f)) ; // 字节流变为字符流
out.write("hello world!!") ;
// 使用字符流输出
out.close() ;
}
};
特别说明:OutputStreamWriter是字符流到字节流的桥梁,这不表示OutputStreamWriter接收一个字符流并将其转换为字节流,恰恰相反,其接收的OutputStream是一个字节流,而它本身是一个字符流。那为什么说它是字符流到字节流的桥梁呢?
我们以文件操作为例,之前已经提到,在内存中数据是以字符形式存在的,而在文件中数据是以字节形式保存的。所以在内存中的字符数据需要通过OutputStreamWriter变为字节流才能保存在文件之中,读取的时候需要将读入的字节流通过InputStreamReader变为字符流。
但OutputStreamWriter和InputStreamReader都是字符流,也就是说,OutputStreamWriter以字符输出流形式操作了字节的输出流,但实际上还是以字节的形式输出。而InputStreamReader,虽然以字符输入流的形式操作,但实际上还是使用的字节流输入,也就是说,传输或者是从文件中读取数据的时候,文件中真正保存的数据永远是字节。

输入流和输出流要指定相同的字符集才能避免乱码!
FileWriter和FileReader的说明
从JDK文档中可以知道FileOutputStream是OutputStream的直接子类,FileInputStream也是InputStream的直接子类,但是在字符流文件的两个操作类却有一些特殊,FileWriter并不直接是Writer的子类,而是转换流OutputStreamWriter的子类,而FileReader也不直接是Reader的子类,而是转换流InputStreamReader的子类,那么从这两个类的继承关系就可以清楚的发现,不管是是使用字节流还是字符流实际上最终都是以字节形式操作输出流的。
缓冲流(BufferedReader和BufferedWriter、BufferedInputStream和BufferedOutputStream)
缓冲流是一系列处理流(包装流),目的是为了提高I/O效率,它们为I/O提供了内存缓冲区,这是一种常见的性能优化,增加缓冲区的两个目的:
(1)允许Java的I/O一次不只操作一个字符,这样提高了整个系统的性能
(2)由于有缓冲区,使得在流上执行skip、mark和reset方法都成为可能。
如果没有缓冲区,每次调用 read() 或 write()方法都会对文件进行读或写字节,在文件和内存之间发生字节和字符的转换,这是极其低效的。
BufferedReader
BufferedReader是一个包装类,是为了提高读效率提供的,其可以接收一个Reader,然后用readLine()逐行读入字符流,直到遇到换行符为止(相当于反复调用Reader类对象的read()方法读入多个字符)。
因此,建议用 BufferedReader 包装所有其 read() 操作可能开销很高的 Reader(如 FileReader 和 InputStreamReader),如:


 markSupported 判断该输入流能支持 mark 和 reset 方法。mark 用于标记当前位置,readlimit 制定可以重新读取的最大字节数,如果标记后读取的字节数不超过 readlimit 可以用 reset 回到标志位置重复读取。
markSupported 判断该输入流能支持 mark 和 reset 方法。mark 用于标记当前位置,readlimit 制定可以重新读取的最大字节数,如果标记后读取的字节数不超过 readlimit 可以用 reset 回到标志位置重复读取。
BufferedWriter
同理建议用BfferedWriter包装所有其write()操作可能开销很高的Writer(如FileWriter和OutputStreamWriter)

BufferedInputStream
BufferedInputStream用于包装其他较为缓慢的InputStream
构造方法摘要
BufferedInputStream(InputStream in)
创建一个使用默认大小输入缓冲区的缓冲字节输入流
BufferedInputStream(InputStream in, int size)
创建一个使用指定大小输入缓冲区的缓冲字节输入流
方法摘要
public int read();
从该输入流中读取一个字节
public int read(byte[] b,int off,int len);
从此字节输入流中给定偏移量处开始将各字节读取到指定的 byte 数组中。
BufferedOutputStream
BufferedOutputStream用于包装其他较为缓慢的OutputStream
构造方法摘要
BufferedOutputStream(OutputStream out);
创建一个使用默认大小输入缓冲区的缓冲字节输出流
BufferedOutputStream(OutputStream out,int size);
创建一个使用默认大小输入缓冲区的缓冲字节输出流
方法摘要
public void write(int b);
向输出流中输出一个字节
public void write(byte[] b,int off,int len);
将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此缓冲的输出流。
public void flush();
刷新此缓冲的输出流。这迫使所有缓冲的输出字节被写出到底层输出流中。
其他
(1)缓冲输入流BufferedInputSTream除了支持read和skip方法意外,还支持其父类的mark和reset方法;
(2)BufferedReader提供了一种新的ReadLine方法用于读取一行字符串(以\r或\n分隔);
(3)BufferedWriter提供了一种新的newLine方法用于写入一个行分隔符;
(4)对于输出的缓冲流,BufferedWriter和BufferedOutputStream,写出的数据会先在缓冲区(由缓冲流提供的一个字节数组,是不可见的)中缓存,直到缓冲区满了会自动写数据到输出流,如果缓冲区未满,可以使用flush方法将会使缓冲区的数据强制写出。关闭输出流也会造成缓冲区中残留的数据被写出。注意BufferedReader和BufferedInputStream没有flush方法,因为flush只用于输出到文件时。
打印流(PrintStream、PrintWriter)
在整个IO包中,打印流是输出信息最方便的类,主要包含字节打印流(PrintStream)和字符打印流(PrintWriter)。打印流提供了非常方便的打印功能,可以打印任何的数据类型,例如:小数、整数、字符串等等。
相较OutputStream在输出时的各种麻烦(比如要将String转为byte[]才能输出)打印流中可以方便地进行输出。
PrintStream
1、public PrintStream(File file) throws FileNotFoundException
//构造方法 通过一个File对象实例化PrintStream类
2、public PrintStream(OutputStream out)
//构造方法 接收OutputStream对象,实例化PrintStream类
3、public PrintStream printf(Locale l, String format, Object ...arg)
//普通方法 根据指定的Locale进行格式化输出
4、public PrintStream printf(String format,Object ... arg)
//普通方法 根据本地环境进行格式化输出
5、public void print(boolean b)
//普通方法 此方法被重载很多次,输出任意数据
6、public void println(boolean b)
//普通方法 此方法被重载很多次,输出任意数据后换行
打印流的好处:在PrintStream中定义的构造方法中可以清楚的发现有一个构造方法可以直接接收OutputStream类的实例,这是因为与OutputStream相比起来,PrintStream可以更加方便的输出数据,这就好比将OutputStream重新包装了一下,使之输出更加方便。
PrintWriter
构造方法
//使用指定文件创建不具有自动行刷新的新 PrintWriter
public PrintWriter(File file);
//创建具有指定文件和字符集且不带自动刷行新的新 PrintWriter
public PrintWriter(File file,String csn);
//根据现有的 OutputStream 创建不带自动行刷新的新PrintWriter
public PrintWriter(OutputStream out);
//通过现有的 OutputStream 创建新的 PrintWriter(具有自动行刷新)
public PrintWriter(OutputStream out,boolean autoFlush);
//创建具有指定文件名称且不带自动行刷新的新PrintWriter
public PrintWriter(String fileName);
//创建具有指定文件名称和字符集且不带自动行刷新的PrintWriter
public PrintWriter(String fileName,String csn);
//创建新 PrintWriter(具有自动行刷新)
public PrintWriter(Writer out,boolean autoFlush)
常用方法
//打印boolean值
public void print(boolean b)
//打印 boolean 值,然后终止该行
public void println(boolean x)
//打印字符
public void print(char c)
//打印字符,然后终止该行
public void println(char x)
//打印字符数组
public void print(char[] s)
//打印字符数组,然后终止该行
public void println(char[] x)
//打印 double 精度浮点数
public void print(double d)
//打印 double 精度浮点数,然后终止该行
public void println(double x)
//打印一个浮点数
public void print(float f)
//打印浮点数,然后终止该行
public void println(float x)
//打印整数
public void print(int i)
//打印整数,然后终止该行
public void println(int x)
//打印 long 整数
public void print(long l)
//打印 long 整数,然后终止该行
public void println(long x)
//打印对象
public void print(Object obj)
//打印 Object,然后终止该行
public void println(Object x)
//打印字符串。如果参数为 null,则打印字符串 "null"
public void print(String s)
//打印 String,然后终止该行
public void println(String x)
//通过写入行分隔符字符串终止当前行
public void println()
//使用指定格式字符串和参数将一个格式化字符串写入此 writer 中。
//如果启用自动刷新,则调用此方法将刷新输出缓冲区
public PrintWriter format(Locale l,String format,Object... args)
//使用指定格式字符串和参数将一个格式化字符串写入此 writer 中。
//如果启用自动刷新,则调用此方法将刷新输出缓冲区
public PrintWriter format(String format,Object... args)
//将指定字符添加到此 writer
public PrintWriter append(char c)
//将指定的字符序列添加到此 writer
public PrintWriter append(CharSequence csq)
//将指定字符序列的子序列添加到此 writer
public PrintWriter append(CharSequence csq,int start,int end)
//写入字符数组
public void write(char[] buf)
//写入字符数组的某一部分
public void write(char[] buf,int off,int len)
//写入单个字符
public void write(int c)
//写入字符串
public void write(String s)
//写入字符串的某一部分
public void write(String s,int off,int len)
提示:由于BufferedWriter没有PrintWriter使用灵活,所以在实际的操作中,我们往往会使用PrintWriter/BufferedReader这种组合。
内存操作流
之前的程序中,输出输入都是在内存和文件之间进行的,当然,输入输出也可以不访问文件,只在内存中进行。也就是把数据的输入源和输出目的地从文件改成了byte数组、char数组或字符串。
字节数组流(ByteArrayInputStream、ByteArrayOutputStream)
ByteArrayInputStream的主要功能是完成将byte数组的内容写入到内存之中,而ByteArrayOutputStream的主要功能是将内存中的数据输出到byte数组。
 ByteArrayInputStream
ByteArrayInputStream
字节数组输入流从内存中的一个字节数组读取字节到内存,这个字节数组就是数据的输入源。创建字节数组输入流对象有以下几种方式。
接收字节数组作为参数创建:
ByteArrayInputStream bArray =
new ByteArrayInputStream(byte [] b);
另一种创建方式是接收一个字节数组,和两个整型变量 off、len,off表示第一个读取的字节,len表示读取字节的长度,即将字节数组中从off开始的len个字节读入该输入流。
ByteArrayInputStream bArray = new
ByteArrayInputStream(byte []b,int off,int len)
成功创建字节数组输入流对象后,可以参见以下列表中的方法,对流进行读操作或其他操作。
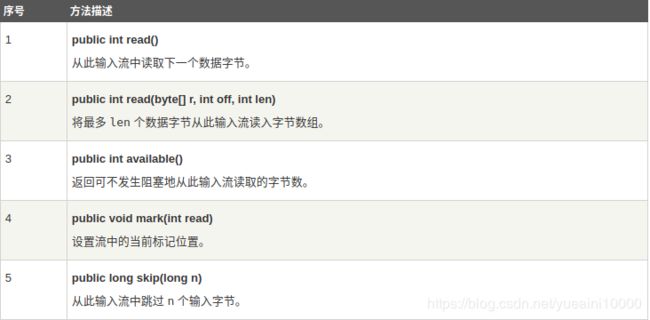 ByteArrayOutputStream
ByteArrayOutputStream
字节数组输出流在内存中创建一个字节数组缓冲区,所有发送到输出流的数据保存在该字节数组缓冲区中,可以用toByteArray()得到该字节数组,也可以用toString()得到缓冲区内容转换得到的字符串。创建字节数组输出流对象有以下几种方式。
下面的构造方法创建一个32字节(默认大小)的缓冲区。
OutputStream bOut = new ByteArrayOutputStream();
另一个构造方法创建一个大小为n字节的缓冲区。
OutputStream bOut = new ByteArrayOutputStream(int n)
成功创建字节数组输出流对象后,可以参见以下列表中的方法,对流进行写操作或其他操作。

下面的例子演示了ByteArrayInputStream 和 ByteArrayOutputStream的使用:
import java.io.* ;
public class ByteArrayDemo01{
public static void main(String args[]){
String str = "HELLOWORLD" ; // 定义一个字符串,全部由大写字母组成
ByteArrayInputStream bis = null ; // 内存输入流
ByteArrayOutputStream bos = null ; // 内存输出流
bis = new ByteArrayInputStream(str.getBytes()) ; // 向内存中输入内容
bos = new ByteArrayOutputStream() ; // 准备从内存ByteArrayInputStream中读取内容
int temp = 0 ;
while((temp=bis.read())!=-1){
char c = (char) temp ; // 读取的数字变为字符
bos.write(Character.toLowerCase(c)) ; // 将字符变为小写
}
// 所有的数据就全部都在ByteArrayOutputStream中
String newStr = bos.toString() ; // 取出内容
try{
bis.close() ;
bos.close() ;
}catch(IOException e){
e.printStackTrace() ;
}
System.out.println(newStr) ;
}
}
字符数据流(CharArrayReader、CharArrayWriter)
CharArrayReader、CharArrayWriter和ByteArrayInputStream、ByteArrayOutputStream类似,只不过后者是字节数组输入流,而前者是字符数组输入流。
CharArrayReader
构造方法摘要
CharArrayReader(char buf[]);
使用传入的buf构造CharArrayReader
CharArrayReader(char buf[], int offset, int length);
使用传入的buf的一部分构造CharArrayReader
方法摘要
void close(); 关闭此流
void mark(int readAheadLimit); 标记当前流读取的位置
void markSupport(); 检测此流是否支持标记
int read(); 读取一个字符、并以整数形式返回
int read(char[] b, int off, int len); 将buf中len个字符读取到
下标从off开始的b中、返回读取的字符个数
boolean ready(); 查看CharArrayReader是否可读。
void reset(); 将此流开始位置重置到最后一次调用mark是流的读取位置
long skip(long n); 丢弃buf中n个字符、返回实际丢弃的字符个数
CharArrayWriter
构造方法摘要
public CharArrayWriter()
使用默认的buf大小创建CharArrayWriter。
public CharArrayWriter(int initialSize)
使用指定的buf大小创建CharArrayWriter。
方法摘要
CharArrayWriter append(CharSequence csq)
将一串有序字符序列写入buf中
CharArrayWriter append(CharSequence csq, int start, int end)
将一串有序字符序列的一部分写入buf中
CharArrayWriter append(char c) 将一个字符写入buf中
void close() 关闭此流(没有效果,因为不访问文件)
void flush() flush此流(没有效果,因为不访问文件)
void reset() 清空buf、重头开始
int size() 查看当前buf中字符总数
char[] toCharArray() 将buf中内容转换成char[]
String toString() 将buf中字符转换成String返回
void write(int c) 写入一个字符。
void write(char c[], int off, int len)
将一个char[]的一部分写入buf中、若buf满、扩容。
void write(String str, int off, int len)
将一个字符串写入buf中、满自动扩容
void writeTo(Writer out)
将buf中现有的字节写入到另一个输出字符流out中
例子:
public static void main(String[] args) throws IOException {
String str = "Hello world!";
// 构建字符输入流
CharArrayReader reader = new CharArrayReader(str.toCharArray());
// 从字符输入流读取字符
char[] chars = new char[1024];
int len = reader.read(chars);
System.out.println(new String(chars, 0, len));
}
//构建字符输出流
CharArrayWriter writer = new CharArrayWriter(1024 * 1024);
// 将字符串写入到CharArrayWriter
String msg = "hello world!!!22121";
writer.write(msg.toCharArray());
System.out.println(writer.toString());
writer.close();
字符串流(StringReader、StringWriter)
字符串流和字符数据流基本一样,只是把char[]数组换成了String,在此不赘述。
合并流(SequenceInputStream、SequenceOutputStream)
SequenceInputStream
有些情况下,当我们需要从多个输入流中向程序读入数据。此时,可以使用合并流,将多个输入流合并成一个SequenceInputStream流对象。
SequenceInputStream会将与之相连接的流集组合成一个输入流并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末 尾为止。 合并流的作用是将多个源合并合一个源。
 构造方法
构造方法
public SequenceInputStream(InputStream s1,InputStream s2)
使用两个输入流对象实例化本类对象。
示例:
import java.io.File ;
import java.io.SequenceInputStream ;
import java.io.FileInputStream ;
import java.io.InputStream ;
import java.io.FileOutputStream ;
import java.io.OutputStream ;
public class SequenceDemo{
public static void main(String args[]) throws Exception {
// 所有异常抛出
InputStream is1 = null ; // 输入流1
InputStream is2 = null ; // 输入流1
OutputStream os = null ; // 输出流
SequenceInputStream sis = null ; // 合并流
is1 = new FileInputStream("d:" + File.separator + "a.txt");
is2 = new FileInputStream("d:" + File.separator + "b.txt");
os = new FileOutputStream("d:" + File.separator + "ab.txt");
sis = new SequenceInputStream(is1,is2) ;
// 实例化合并流
int temp = 0 ; // 接收内容
while((temp=sis.read())!=-1){ // 循环输出
os.write(temp) ; // 保存内容
}
sis.close() ; // 关闭合并流
is1.close() ; // 关闭输入流1`
is2.close() ; // 关闭输入流2
os.close() ; // 关闭输出流
}
};
SequenceOutputStream
同SequenceInputStream,区别在于合并的是两个OutputStream,在此不赘述。
数据操作流(DataInputStream、DataOutputStream)
DataInputStream
数据输入流允许应用程序以与机器无关方式从底层输入流中读取Java 8种基本数据类型,方法命名为readXxx。
下面的构造方法用来创建数据输入流对象。
DataInputStream dis = new DataInputStream(InputStream in);
另一种创建方式是接收一个字节数组,和两个整形变量 off、len,off表示第一个读取的字节,len表示读取字节的长度。
DataInputStream dis = new DataInputStream(byte[] a,int off,int len);
 DataOutputStream
DataOutputStream
数据输出流允许应用程序以与机器无关方式将Java 8种基本数据类型写到底层输出流,方法命名为writeXxx。
下面的构造方法用来创建数据输出流对象。
DataOutputStream out = new DataOutputStream(OutputStream out);
创建对象成功后,可以参照以下列表给出的方法,对流进行写操作或者其他操作。

下面的例子演示了DataInputStream和DataOutputStream的使用,该例从文本文件test.txt中读取5行,并转换成大写字母,最后保存在另一个文件test1.txt中。
import java.io.*;
public class Test{
public static void main(String args[])throws IOException{
DataInputStream d = new DataInputStream(new
FileInputStream("test.txt"));
DataOutputStream out = new DataOutputStream(new
FileOutputStream("test1.txt"));
String count;
while((count = d.readLine()) != null){
String u = count.toUpperCase();
System.out.println(u);
out.writeBytes(u + " ,");
}
d.close();
out.close();
}
}
对象流(ObjectInputStream、ObjectOutputStream)
序列化与反序列化
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程。

**序列化:**对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性。序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。序列化后的字节流保存了Java对象的状态以及相关的描述信息。序列化机制的核心作用就是对象状态的保存与重建。
**反序列化:**客户端从文件中或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
实现序列化的前提
只有实现了 Serializable 或 Externalizable 接口的类的对象才能被序列化,否则抛出异常!
注意:Serializable接口和Cloneable接口一样是一个标记接口,即没有任何方法的接口。但只有一个类实现了Serializable接口,它才能被序列化为二进制流进行传输,否则会抛出NotSerializableException异常。一个类如果实现了Serializable接口,其子类自动实现序列化,不需要显式实现 Serializable 接口。
Serializable 和 Externalizable 接口的关系和区别
① Externalizable接口是Serializable接口的子接口,Serializable是一个空的标记接口,而Externalizable接口中定义了两个方法,如下:
public interface Externalizable extends Serializable {
public void writeExternal(ObjectOutput out) throws IOException;
public void readExternal(ObjectInput in)
throws IOException, ClassNotFoundException;
}
② 若实现Serializble接口,可选择性实现 readObject(ObjectInputStream in) 和 writeObject(ObjectOutputSteam out),如果实现了就参与自定义序列化和反序列化过程,未实现就参与默认序列化和反序列化过程;若实现Externalizable接口则必须实现readExternal(ObjectInput in) 和 writeExternal(ObjectOutput out) 方法。
③ 若实现Externalizable接口,反序列化时会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。所以此时被序列化类必须定义一个无参构造器。
④ 比较而言,Externalizable更为高效, 但Serializable更加灵活,其最重要的特色就是可以自动序列化,因此使用广泛。所以一般只有在对效率要求较高的情况下才会考虑Externalizable,但通常情况下Serializable使用的更多。
实现Java对象序列化与反序列化的方法
假定一个User类,它的对象需要序列化,可以有如下三种方法:
若 User 类仅仅实现了 Serializable 接口,则可以按照以下方式进行序列化和反序列化:
ObjectOutputStream 采用默认的序列化方式,对 User 对象的非 transient 的实例变量进行序列化。
ObjcetInputStream 采用默认的反序列化方式,对对 User 对象的非 transient 的实例变量进行反序列化。
若User类仅仅实现了Serializable接口,并且还定义了 readObject(ObjectInputStream in) 和writeObject(ObjectOutputSteam out),则采用以下方式进行序列化与反序列化:
ObjectOutputStream 调用 User 对象的 writeObject(ObjectOutputStream out) 的方法进行自定义序列化。
ObjectInputStream 会调用 User 对象的 readObject(ObjectInputStream in) 的方法进行自定义反序列化。
若User类实现了 Externalnalizable 接口,且 User 类必须实现 readExternal(ObjectInput in) 和 writeExternal(ObjectOutput out) 方法,则按照以下方式进行序列化与反序列化:
ObjectOutputStream 调用 User 对象的 writeExternal(ObjectOutput out)) 的方法进行序列化。
ObjectInputStream 会调用User对象的 readExternal(ObjectInput in) 的方法进行反序列化。
定义一个可被序列化的类:
public class User implements Serializable{
private String username ;
private String password;
private String gender;
public User(String username,String password,String gender){
this.username = username;
this.password = password;
this.gender = gender;
}
public String toString(){
return "用户名:" + this.username + ";密码:"
+ this.password + ";性别:" + this.gender ;
}
}
以后此类的对象就可以被序列化了。变为二进制byte流。
serialVersionUID
在对象进行序列化或反序列化操作的时候,要考虑类版本的问题,如果序列化后修改了该类,反序列化就则就有可能造成异常。所以在序列化操作中引入了一个serialVersionUID的常量,可以通过此常量来验证版本的一致性,在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现版本不一致的异常。
更多见:Java对象序列化为什么要使用SerialversionUID
ObjectOutputStream(序列化)
步骤一:创建一个对象输出流,它可以包装一个其它类型的目标输出流,如文件输出流:
ObjectOutputStream oos =
new ObjectOutputStream(new FileOutputStream("D:\\object.out"));
步骤二:通过对象输出流的writeObject()方法写对象:
oos.writeObject(new User("xuliugen", "123456", "male"));
ObjectInputStream(反序列化)
步骤一:创建一个对象输入流,它可以包装一个其它类型输入流,如文件输入流:
ObjectInputStream ois= new ObjectInputStream(new FileInputStream("object.out"));
步骤二:通过对象输出流的readObject()方法读取对象:
User user = (User) ois.readObject();
序列化与反序列化示例
为了更好地理解Java序列化与反序列化,举一个简单的示例如下:
p
ublic class SerialDemo {
public static void main(String[] args) throws IOException,
ClassNotFoundException {
//序列化
FileOutputStream fos = new FileOutputStream("object.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
User user1 = new User("Steven1997", "123456", "male");
oos.writeObject(user1);
oos.flush();
oos.close();
//反序列化
FileInputStream fis = new FileInputStream("object.out");
ObjectInputStream ois = new ObjectInputStream(fis);
User user2 = (User) ois.readObject();
System.out.println(user2);
//反序列化的输出结果为:用户名:Steven1997;密码:123456;性别:male
}
}
public class User implements Serializable{
private String username ;
private String password;
private String gender;
public User(String username,String password,String gender){
this.username = username;
this.password = password;
this.gender = gender;
}
public String toString(){
return "用户名:" + this.username + ";密码:"
+ this.password + ";性别:" + this.gender ;
}
}
序列化只针对对象的非静态变量,对于 static 、transient 修饰的变量和成员方法不进行序列化。
当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化。
transient关键字
当使用Serializable接口实现序列化操作时,如果一个对象中的某个属性不希望被JVM默认序列化的话,则可以使用transient关键字进行声明。如果用transient声明一个实例变量,当对象存储时,它的值不需要维持,而会保持默认值。换句话来说就是,用transient关键字标记的成员变量不参与JVM的默认序列化过程。
更多序列化知识见:
Java序列化心得(一):序列化设计和默认序列化格式的问题
Java序列化心得(二):自定义序列化
Java IO操作——对象序列化(Serializable接口、ObjectOutputStream、以及与Externalizable接口的用法和区别)
拓展:ArrayList 中存储数据的数组是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;
压缩流
在日常的使用中经常会使用到像WinRAR或WinZIP这样的压缩文件,通过这些软件可以把一个很大的文件进行压缩以方便传输。
在JAVA中 为了减少传输时的数据量也提供了专门的压缩流,可以将文件或文件夹压缩成ZIP、JAR、GZIP等文件的格式。
具体见大牛博客:
http://blog.csdn.net/u013087513/article/details/52151227
管道流(PipedOutputStream、PipedInputStream)
管道流的作用是可以进行两个线程间的通讯,分为管道输出流(PipedOutputStream)、管道输入流(PipedInputStream)。如果要想进行管道输出,则必须把输出流连在输入流之上,在PipedOutputStream中有一个方法用于连接管道:
public void connect(PipedInputStream snk) throws IOException

例子如下:
import java.io.* ;
class Send implements Runnable{ // 线程类
private PipedOutputStream pos = null ; // 管道输出流
public Send(){
this.pos = new PipedOutputStream() ; // 实例化输出流
}
public void run(){
String str = "Hello World!!!" ; // 要输出的内容
try{
this.pos.write(str.getBytes()) ;
}catch(IOException e){
e.printStackTrace() ;
}
try{
this.pos.close() ;
}catch(IOException e){
e.printStackTrace() ;
}
}
public PipedOutputStream getPos(){ // 得到此线程的管道输出流
return this.pos ;
}
}
class Receive implements Runnable{
private PipedInputStream pis = null ; // 管道输入流
public Receive(){
this.pis = new PipedInputStream() ; // 实例化输入流
}
public void run(){
byte b[] = new byte[1024] ; // 接收内容
int len = 0 ;
try{
len = this.pis.read(b) ; // 读取内容
}catch(IOException e){
e.printStackTrace() ;
}
try{
this.pis.close() ; // 关闭
}catch(IOException e){
e.printStackTrace() ;
}
System.out.println("接收的内容为:" + new String(b,0,len)) ;
}
public PipedInputStream getPis(){
return this.pis ;
}
}
public class PipedDemo{
public static void main(String args[]){
Send s = new Send() ;
Receive r = new Receive() ;
try{
s.getPos().connect(r.getPis()) ; // 连接管道
}catch(IOException e){
e.printStackTrace() ;
}
new Thread(s).start() ; // 启动线程
new Thread(r).start() ; // 启动线程
}
}
类似地,还有管道字符流 PipedReader 和 PipedWriter,用法基本相同,在此不赘述。
回退流(PushbackInputStream和PushbackReader)
在Java IO中所有的数据都是采用顺序的读取方式,即对于一个输入流来讲都是采用从头到尾的顺序读取的,如果在输入流中某个不需要的内容被读取进来,则只能通过程序将这些不需要的内容处理掉,为了解决这样的处理问题,在Java中提供了一种回退输入流(PushbackInputStream、PushbackReader),可以把读取进来的某些数据重新回退到输入流的缓冲区之中。

回退流分为字节回退流和字符回退流,我们以字节回退流PushbackInputStream为例。

对于回退操作来说,提供了三个unread()的操作方法,这三个操作方法与InputStream类中的read()方法是一一对应的。
例子如下,内存中使用ByteArrayInputStream,把内容设置到内存之中:
import java.io.ByteArrayInputStream ;
import java.io.PushbackInputStream ;
public class PushInputStreamDemo{
public static void main(String args[]) throws Exception { // 所有异常抛出
String str = "www.baidu.com" ; // 定义字符串
PushbackInputStream push = null ; // 定义回退流对象
ByteArrayInputStream bai = null ; // 定义内存输入流
bai = new ByteArrayInputStream(str.getBytes()) ; // 实例化内存输入流
push = new PushbackInputStream(bai) ; // 从内存中读取数据
System.out.print("读取之后的数据为:") ;
int temp = 0 ;
while((temp=push.read())!=-1){ // 读取内容
if(temp=='.'){ // 判断是否读取到了“.”
push.unread(temp) ; // 放回到缓冲区之中
temp = push.read() ; // 再读一遍
System.out.print("(退回"+(char)temp+")") ;
}else{
System.out.print((char)temp) ; // 输出内容
}
}
}
};
System类对IO的支持(out、err、in)
System类的常量
System表示系统类,实际上在Java中也对IO给予了一定的支持
1、public static final PrintStream out
//常量 对应系统标准输出,一般是显示器
2、public static final PrintStream err
//常量 错误信息输出
3、public static final InputStream in
//常量 对应标准输出,一般是键盘
使用static final关键字声明的变量是全局常量,只要是常量,则所有的单词字母必须全部大写,按照现在的标准:
System.OUT —> System.out
System.out
使用System.out输出的时候就是将输出的位置定义在了显示器之中。FileOutputStream是定位在文件里,而System.out是定位在屏幕上输出。PrintStream就是OutputStream的子类。
import java.io.OutputStream ;
import java.io.IOException ;
public class SystemDemo01{
public static void main(String args[]){
OutputStream out = System.out ;// 此时的输出流是向屏幕上输出
try{
out.write("hello world!!!".getBytes()) ; // 向屏幕上输出
}catch(IOException e){
e.printStackTrace() ; // 打印异常
}
try{
out.close() ; // 关闭输出流
}catch(IOException e){
e.printStackTrace() ;
}
}

System.err
System.err 表示的是错误的标准输出,如果程序中出现了错误的话,则直接使用System.err进行输出即可。程序如下:
public class SystemDemo02{
public static void main(String args[]){
String str = "hello" ; // 声明一个非数字的字符串
try{
System.out.println(Integer.parseInt(str)) ; // 转型
}catch(Exception e){
System.err.println(e) ;
}
}
};

使用System.out输出错误如下:
public class SystemDemo03{
public static void main(String args[]){
String str = "hello" ; // 声明一个非数字的字符串
try{
System.out.println(Integer.parseInt(str)) ; // 转型
}catch(Exception e){
System.out.println(e) ;
}
}
};

System.out 和System.err 的区别:System.out和System.err都是PrintStream的实例化对象,而且通过代码可以发现,两者都可以输出错误信息,但是一般来讲System.out是将信息显示给用户看,是正常的信息显示,而System.err的正好相反是不希望用户看到的,会直接在后台打印,是专门显示错误的。
一般来讲,如果要输出错误信息的时候最好不要使用System.out而是直接使用System.err 这一点只能从其概念上划分。

System.in
System.in实际上是一个键盘的输入流,其本身是InputStream类型的对象。那么,此时就可以利用此方式完成从键盘读取数据的功能。
InputStream对应的是输入流,输入流的话肯定是从指定位置读取的,之前使用的是FileInputStream,是从文件中读取的。
import java.io.InputStream ;
public class SystemDemo04{
public static void main(String args[]) throws Exception { // 所有异常抛出
InputStream input = System.in ; // 从键盘接收数据
byte b[] = new byte[1024] ; // 开辟空间,接收数据
System.out.print("请输入内容:") ; // 提示信息
int len = input.read(b) ; // 接收数据
System.out.println("输入的内容为:" + new String(b,0,len)) ;
input.close() ; // 关闭输入流
}
};
但是以上的操作存在如下问题:
问题一:指定了输入数据的长度,如果现在输入的数据超过了长度范围,只能输入部分的数据。
问题二:如果byte数组是奇数的话,则还可能出现中文乱码的情况,因为一个字符是两个字节。
可以通过标志位的方式避免指定byte数组大小来解决。实例如下:
import java.io.InputStream ;
public class SystemDemo05{
public static void main(String args[]) throws Exception { // 所有异常抛出
InputStream input = System.in ; // 从键盘接收数据
StringBuffer buf = new StringBuffer() ; // 使用StringBuffer接收数据
System.out.print("请输入内容:") ; // 提示信息
int temp = 0 ; // 接收内容
while((temp=input.read())!=-1){
char c = (char) temp ; // 将数据变为字符
if(c=='\n'){ // 退出循环,输入回车表示输入完成
break ;
}
buf.append(c) ; // 保存内容
}
System.out.println("输入的内容为:" + buf) ;
input.close() ; // 关闭输入流
}
}
但这种方法读取中文还是会乱码,这是因为每读取一个字节就将其转为字符,字母和数字都是占1个字节 可以正常显示。但是如果是中文的话,就相当于每读取到一个字节就是半个字符就进行转化,所以导致乱码的错误。
最好的输入方式是将全部输入的数据暂时存放在一块内存之上,之后一次性的从内存中读取数据,这样所有数据就整体只读了一次,则不会造成乱码,而且也不会受到长度的限制。
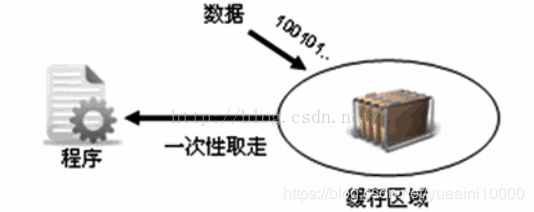 上述功能可以通过BufferedReader实现。
上述功能可以通过BufferedReader实现。
输入输出重定向
从之前的操作中知道System.out、System.err、System.in三个常量的作用,但是通过System类也可以改变System.in的输入流来源,以及System.out和System.err两个输出流的输出位置。
1、public static void setOut(PrintStream out)
//普通方法 重定向标准输出流
2、public static void setErr(PrintStream err)
//普通方法 重定向标准错误输出流
3、public static void setIn(InputStream in)
//普通方法 重定向标准输入流
为System.out输出重定向
import java.io.File ;
import java.io.FileOutputStream ;
import java.io.PrintStream ;
public class SystemDemo06{
public static void main(String args[]) throws Exception {
System.setOut(
new PrintStream(
new FileOutputStream("d:" +
File.separator + "red.txt"))) ; // System.out输出重定向
System.out.print("hello") ; // 输出时,不再向屏幕上输出
System.out.println(",world") ;
}
};
System.out是希望用户看得到信息,一旦有错误,最好保存起来。
import java.io.File ;
import java.io.FileOutputStream ;
import java.io.PrintStream ;
public class SystemDemo07{
public static void main(String args[]){
String str = "hello" ; // 声明一个非数字的字符串
try{
System.out.println(Integer.parseInt(str)) ; // 转型
}catch(Exception e){
try{
System.setOut(
new PrintStream(
new FileOutputStream("d:"
+ File.separator + "err.log"))) ; // 输出重定向
}catch(Exception e1){
}
System.out.println(e) ;
}
}
};
通过此操作就可以完成错误的重定向,保存错误日志。
为System.err重定向
利用System.err向屏幕上输出信息,此时,为了方便起见,使用内存操作流。
import java.io.ByteArrayOutputStream ;
import java.io.PrintStream ;
public class SystemDemo08{
public static void main(String args[]) throws Exception{ // 所有异常抛出
ByteArrayOutputStream bos = null ; // 声明内存输出流
bos = new ByteArrayOutputStream() ; // 实例化
System.setErr(new PrintStream(bos)) ; // 输出重定向
System.err.print("hello") ; // 错误输出,不再向屏幕上输出
System.err.println("world") ; // 向内存中输出
System.out.println(bos) ; // 输出内存中的数据
}
};
一般不建议去修改System.err的输出位置,因为这样的信息都不太希望用户可以看见。
为System.in重定向
默认情况下System.in是指键盘输入,也可以通过setIn()方法,将其输入流的位置改变,例如,现在从文件中读取。
import java.io.FileInputStream ;
import java.io.InputStream ;
import java.io.File ;
public class SystemDemo09{
public static void main(String args[]) throws Exception{ // 所有异常抛出
System.setIn(new FileInputStream("d:"
+ File.separator + "demo.txt")) ; // 设置输入重定向
InputStream input = System.in ; // 从文件中接收数据
byte b[] = new byte[1024] ;// 开辟空间,接收数据
int len = input.read(b) ; //接收
System.out.println("输入的内容为:" + new String(b,0,len)) ;
input.close() ; // 关闭输入流
}
};
总结
三个常量的使用:
System.out是希望用户可以看见的信息。用IDE(Eclipse)的话错误信息使用黑颜色显示的。
System.err 是不希望用户可以看见的信息。则在IDE中将以红色的文字显示错误信息。
System.in 对应键盘输入。
以上三个常量的输入、输出都可以重定向,但是一般建议只修改setOut的重定向。
System.in读取的时候会出现中文乱码的问题,则可以通过BufferedReader完成读取功能。
作者:Steven1997
链接:https://www.jianshu.com/p/6de72c9489cf
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。