对比Attention的几种结构
前言
Attention是一种思想,在当前输出上,是存在部分输入需要重点关注的,其对该输出贡献非常大。之前看到几篇关于attention思想的应用文章,现对比下其中的Attention具体结构上的区别。
NMT using Attention
这篇文章是Bahdanau的2015年佳作,将Attention引入到NMT中并取得了非常好的效果,其中的attention结构不是非常容易理解。
NMT面临的问题:通常的Encoder-Decoder翻译模式下,Encoder会将所有必要的信息压缩到一个定长向量中,而Decoder则依赖这个定长向量来做翻译。定长向量成了制约翻译效果的瓶颈,拓展模型自动寻找与待预测部分相关的source作辅助,会有更好的效果。该方法的主要思路是:每次翻译某个词之前,先找到source中最相关信息的位置,然后利用包含这些位置信息及之前预测词的context vector来预测下个词。其最大的特点:将输入序列编码到序列向量中,自适应地选择其子集供翻译时使用。
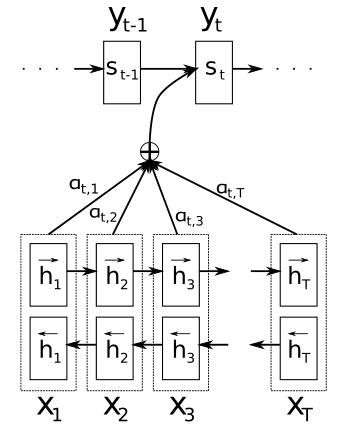
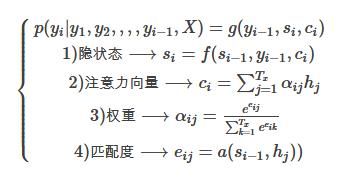
让我们仔细地研究下Decoder其中的公式关系。
当预测某个词时:
依赖于三个变量,前刻预测词 yi−1 y i − 1 ,当前的隐状态 si s i ,当前的上下文向量 ci c i 。
而当前的隐状态:
上下文向量 ci c i 涵盖了当前待预测词 yi y i 需要关注的source信息总和, ci=∑Txj=1αijhj c i = ∑ j = 1 T x α i j h j 。到底需要关注哪些source信息呢?对输入序列的对应定义 解释变量 hj h j ,该变量描述了输入序列位置 j j 处及附近的信息。 αij α i j 则表示当前待预测词 yi y i 与source词 xj x j 附近信息的 相关性程度(对每个 xj x j 的关注度)。
疑问1:为什么不直接model xj x j 与 yi y i 的关系呢?后文后有解释。
疑问2:如何具体表示 αij α i j 呢?
αij=exp(eij)∑Txk=1exp(eik) α i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) ,根据所有输入词对 yi y i 的相关值 eij e i j 作normalize,得到归一化的概率权重,其中 eij=a(si−1,hj) e i j = a ( s i − 1 , h j )
疑问3:如何理解 eij e i j 能够描述source词 xj(隐藏着[hj] x j ( 隐 藏 着 [ h j ] )与 yi y i 相关性。
eij e i j 表达的是输入 j j 附近与输出位置 i i 的相关性评估, eij e i j 反映了 hj h j 在考虑前刻隐状态 si−1 s i − 1 在决定当前隐状态 si s i 和生成预测值 yi y i 时的某种重要性。
还是那个问题, 为什么不直接model xj x j 和 yi y i 的关系?一方面,会跳过解释变量 h h ,没法跟当前的RNN模型结合在一起;另一方面,在预测时,不能直接得到 yi y i 的变量来计算(因为还没预测到),必须要借助前刻的信息 si−1 s i − 1 ,而 si−1 s i − 1 也刚好包括前刻的必备信息。
疑问4:关联函数 a a 怎么表达呢?
这里用了个前向网络 eij=vTatanh[Wasi−1+Uahj]) e i j = v a T t a n h [ W a s i − 1 + U a h j ] ) 来表达(concate的形式,后面会介绍有好几种alignment形式),与模型一块训练。
疑问5:如何在翻译模式中体现 hj h j 呢?
输入序列的解释变量 h h 如何实现的?与 s s 是什么结构关系?解码器: Bidirection GRU for hj=[hj→;hj←] h j = [ h j → ; h j ← ] ,可以得知 h h 是BRNN的隐状态,那么 s s 又是什么呢?Encode时和Decode时的隐状态名称不同,前者称为 h h ,后者称为 s s ,这下明白了吧。
来个Google的带有Attention的NMT动图,看下Encoder和Decoder在注意力机制下是如何交互的。
Global/Local Attention-based NMT
Luong2015年的非常经典的文章,探索了Attention在NMT中的应用性,基于如何得到上下文向量 c c ,定义了两种attention的结构形式,分别命名为global和local Attention。
其中Global考虑Encoder的所有隐状态来生成上下向量 c c ,而Local Attention则是仅考虑局部隐状态来生成上下文向量 c c ,两种结构如下图描述:
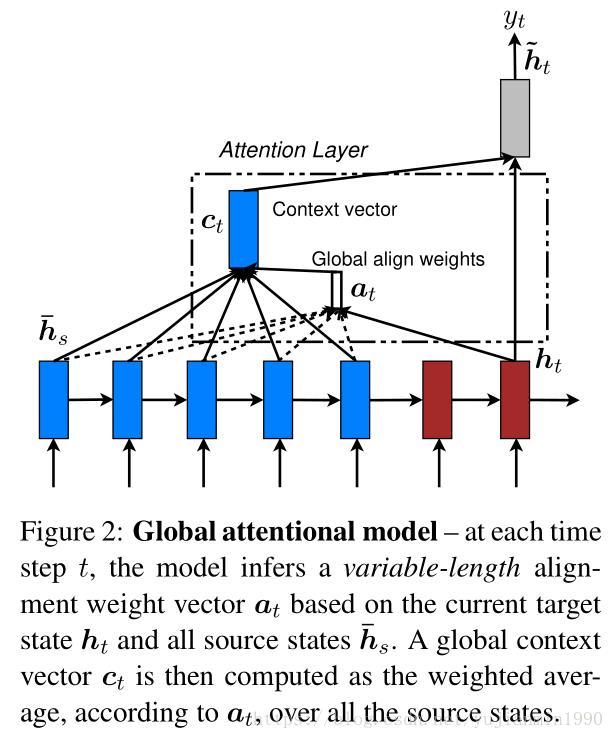

定义了几种target的隐状态 ht h t 与source的解释变量(隐状态) h¯s h ¯ s 之间的相关性评估函数,如下:
注意:这里的 ht h t 的下标只是定义方便,在使用的时候,还是第一小节里面的 st−1 s t − 1 ,预测某个 y y 时的target输入隐状态。
在Location的 第一种形态下location-m,直接指定 pt=t p t = t ,然后使用窗口 D×2 D × 2 内解释变量。而在Location的 第二种形态location-p,对align关系引入波峰强度变化,以某个 h h 为中心呈正态分布。
局部中心的函数定义为:(其中 S S 是source长度)
align weight定义为:
其中 align(ht,h¯s)=exp(score(ht,h¯s))∑s′score(ht,h¯s′) a l i g n ( h t , h ¯ s ) = e x p ( s c o r e ( h t , h ¯ s ) ) ∑ s ′ s c o r e ( h t , h ¯ s ′ ) , 2σ=D 2 σ = D , D是窗口大小size/2 D 是 窗 口 大 小 s i z e / 2 。
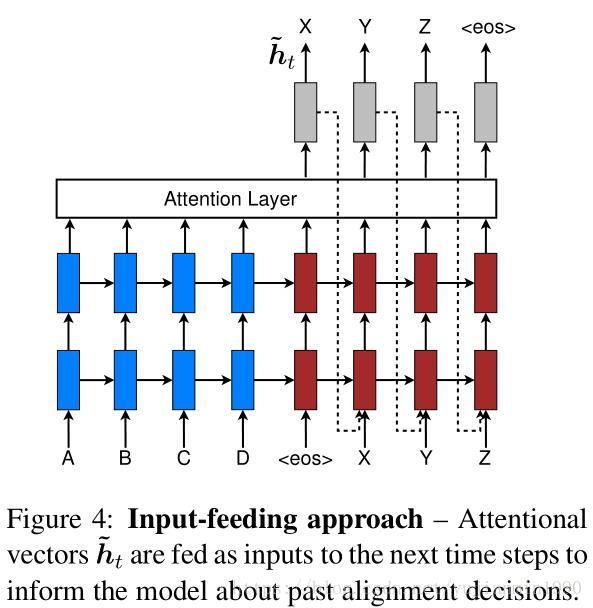
为了在预测时,告知模型以往的align决策,将 h˜t h ~ t 也作为当前预测的输入,称其为 Input-Feeding Approach。【这个地方,感觉好像也没什么必要,不管是global还是local里面,都有 ct c t 对 h˜t h ~ t 作贡献(隐藏着收敛效果),是不是就可以不用了】converage set 指的是,在翻译任务中通常会包括份收敛集,来记录追踪哪些source词已经被翻译了。在带有Attention的NMT中,align决策也需要知道之前的align信息。在Global和Local结构中,align决策都是独立的,需要有个操作将之前的align决策告诉当前的预测操作,因此需要单独的结构来完成这一功能,因此Input-Feed还是有必要的(可能这也是虽然结构简单但是效果仍然非常好的另外一个助力)。
Neural Image Caption Generation with Visual Attention
图像注释问题非常接近于Encoder-Decoder结构,在生成图像的某部分描述时,能够集中于图像某部分,Attention是个非常匹配的机制。K Xu2015时在图像注释的工作中使用Attention机制,命名为Visual Attention。其中定义了两种Attention机制:Stochastic Hard Attention 和 Deterministic Soft Attention,都可以压缩一张图片用以生成一段语言描述。
使用卷积网络CNN来提取图像特征作为解释变量,提取 L L 个解释向量,每一个都表示了图像的某一部分。 a={a1,a2,...,aL},ai∈RD a = { a 1 , a 2 , . . . , a L } , a i ∈ R D ,为了能够描述更基础的图像特征,在底层卷积层上来抽取解释向量;用LSTM来作为解码器,生成描述语句。
1)Stochastic Hard Attention
st,i=1 s t , i = 1 表示生成第 t t 个词时,第 i i 部分图像被关注(一共 L L 部分)。将注意位置作为隐变量,可以将由解释变量 ai a i 确定的上下文 z^t z ^ t 看作是随机变量【一方面,为随机选择关注部分图像作解释,一方面为采样寻优方法作约束】。
定义目标函数 Ls L s ,其下限值逼近于 logp(y|a) l o g p ( y | a )
上式指出基于MonteCarlo的采样方法来估计参数梯度是可行的,通过对 αi α i 决定的Multinoulli分布采样具体位置 st s t ,来估计参数导数,如下:
引入滑动平均来降低估计方差波动,对第 k k 个mini-batch,如下处理:
为进一步降低估计方差,引入熵 H[s] H [ s ] ,
最终的梯度如下:
λr和λe λ r 和 λ e 是两个超参,上述式子相当于强化学习,对注意集中的后续动作收益是目标句子的似然概率值,在采样注意策略下。
为什么称之为Hard Attention呢?是因为上下文 z^ z ^ 所用的解释向量是通过服从 αi α i 的分布采样得来的。
2)Deteriministic Soft Attention
若是不使用采样,而是直接使用所有的区域,就变成了soft attention,在Bahdanau的15年文章里就是类似的方法。
总结
Attention的基本结构:
1)可用采样估计梯度优化的Hard形式。
2)可直接计算梯度来优化的Soft形式。
Reference
- 2017 - 《Attention is All You Need》
- 2015 - 《Neural Machine Translation by Jointly Learning to Align and Translate》
- 2015 - 《NMT by Jointly Learning to Align and Translate》 source-code
- 2015 - 《Effective Approaches to Attention-based Neural Machine Translation》
- 2015 - 《Effective Approaches to Attention-based NMT》 source-code
- 2015 - 《Show, Attention and Tell: Neural Image Caption Generation with Visual Attention》
- 2015 - 《Deep Visual-Semantic Alignments for Generating Image Descriptions》
- https://ai.googleblog.com/2016/09/a-neural-network-for-machine.html