RCU synchronize原理分析
RCU synchronize原理分析
http://www.wowotech.net/kernel_synchronization/223.html
RCU(Read-Copy Update)是Linux内核比较成熟的新型读写锁,具有较高的读写并发性能,常常用在需要互斥的性能关键路径。在kernel中,rcu有tiny rcu和tree rcu两种实现,tiny rcu更加简洁,通常用在小型嵌入式系统中,tree rcu则被广泛使用在了server, desktop以及android系统中。本文将以tree rcu为分析对象。
1 如何度过宽限期
RCU的核心理念是读者访问的同时,写者可以更新访问对象的副本,但写者需要等待所有读者完成访问之后,才能删除老对象。这个过程实现的关键和难点就在于如何判断所有的读者已经完成访问。通常把写者开始更新,到所有读者完成访问这段时间叫做宽限期(Grace Period)。内核中实现宽限期等待的函数是synchronize_rcu。
1.1 读者锁的标记
在普通的TREE RCU实现中,rcu_read_lock和rcu_read_unlock的实现非常简单,分别是关闭抢占和打开抢占:
- staticinlinevoid __rcu_read_lock(void)
- {
- preempt_disable();
- }
- staticinlinevoid __rcu_read_unlock(void)
- {
- preempt_enable();
- }
这时是否度过宽限期的判断就比较简单:每个CPU都经过一次抢占。因为发生抢占,就说明不在rcu_read_lock和rcu_read_unlock之间,必然已经完成访问或者还未开始访问。
1.2 每个CPU度过quiescnet state
接下来我们看每个CPU上报完成抢占的过程。kernel把这个完成抢占的状态称为quiescent state。每个CPU在时钟中断的处理函数中,都会判断当前CPU是否度过quiescent state。
- void update_process_times(int user_tick)
- {
- ......
- rcu_check_callbacks(cpu, user_tick);
- ......
- }
- void rcu_check_callbacks(int cpu,int user)
- {
- ......
- if(user || rcu_is_cpu_rrupt_from_idle()){
- /*在用户态上下文,或者idle上下文,说明已经发生过抢占*/
- rcu_sched_qs(cpu);
- rcu_bh_qs(cpu);
- }elseif(!in_softirq()){
- /*仅仅针对使用rcu_read_lock_bh类型的rcu,不在softirq,
- *说明已经不在read_lock关键区域*/
- rcu_bh_qs(cpu);
- }
- rcu_preempt_check_callbacks(cpu);
- if(rcu_pending(cpu))
- invoke_rcu_core();
- ......
- }
细分这些场景是为了提高RCU的效率。rcu_preempt_state将在下文进行说明。
1.3 汇报宽限期度过
每个CPU度过quiescent state之后,需要向上汇报直至所有CPU完成quiescent state,从而标识宽限期的完成,这个汇报过程在软中断RCU_SOFTIRQ中完成。软中断的唤醒则是在上述的时钟中断中进行。
update_process_times
-> rcu_check_callbacks
-> invoke_rcu_core
RCU_SOFTIRQ软中断处理的汇报流程如下:
rcu_process_callbacks
-> __rcu_process_callbacks
-> rcu_check_quiescent_state
-> rcu_report_qs_rdp
-> rcu_report_qs_rnp
其中rcu_report_qs_rnp是从叶子节点向根节点的遍历过程,同一个节点的子节点都通过quiescent state后,该节点也设置为通过。
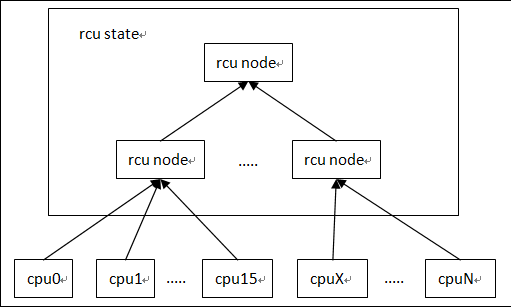
这个树状的汇报过程,也就是“Tree RCU”这个名字得来的缘由。
树结构每层的节点数量和叶子节点数量由一系列的宏定义来决定:
- #define MAX_RCU_LVLS 4
- #define RCU_FANOUT_1 (CONFIG_RCU_FANOUT_LEAF)
- #define RCU_FANOUT_2 (RCU_FANOUT_1 * CONFIG_RCU_FANOUT)
- #define RCU_FANOUT_3 (RCU_FANOUT_2 * CONFIG_RCU_FANOUT)
- #define RCU_FANOUT_4 (RCU_FANOUT_3 * CONFIG_RCU_FANOUT)
- #if NR_CPUS <= RCU_FANOUT_1
- # define RCU_NUM_LVLS 1
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 (NR_CPUS)
- # define NUM_RCU_LVL_2 0
- # define NUM_RCU_LVL_3 0
- # define NUM_RCU_LVL_4 0
- #elif NR_CPUS <= RCU_FANOUT_2
- # define RCU_NUM_LVLS 2
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_1)
- # define NUM_RCU_LVL_2 (NR_CPUS)
- # define NUM_RCU_LVL_3 0
- # define NUM_RCU_LVL_4 0
- #elif NR_CPUS <= RCU_FANOUT_3
- # define RCU_NUM_LVLS 3
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_2)
- # define NUM_RCU_LVL_2 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_1)
- # define NUM_RCU_LVL_3 (NR_CPUS)
- # define NUM_RCU_LVL_4 0
- #elif NR_CPUS <= RCU_FANOUT_4
- # define RCU_NUM_LVLS 4
- # define NUM_RCU_LVL_0 1
- # define NUM_RCU_LVL_1 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_3)
- # define NUM_RCU_LVL_2 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_2)
- # define NUM_RCU_LVL_3 DIV_ROUND_UP(NR_CPUS, RCU_FANOUT_1)
- # define NUM_RCU_LVL_4 (NR_CPUS)
1.3 宽限期的发起与完成
所有宽限期的发起和完成都是由同一个内核线程rcu_gp_kthread来完成。通过判断rsp->gp_flags & RCU_GP_FLAG_INIT来决定是否发起一个gp;通过判断! (rnp->qsmask) && !rcu_preempt_blocked_readers_cgp(rnp))来决定是否结束一个gp。
发起一个GP时,rsp->gpnum++;结束一个GP时,rsp->completed = rsp->gpnum。
1.4 rcu callbacks处理
rcu的callback通常是在sychronize_rcu中添加的wakeme_after_rcu,也就是唤醒synchronize_rcu的进程,它正在等待GP的结束。
callbacks的处理同样在软中断RCU_SOFTIRQ中完成
rcu_process_callbacks
-> __rcu_process_callbacks
-> invoke_rcu_callbacks
-> rcu_do_batch
-> __rcu_reclaim
这里RCU的callbacks链表采用了一种分段链表的方式,整个callback链表,根据具体GP结束的时间,分成若干段:nxtlist -- *nxttail[RCU_DONE_TAIL] -- *nxttail[RCU_WAIT_TAIL] -- *nxttail[RCU_NEXT_READY_TAIL] -- *nxttail[RCU_NEXT_TAIL]。
rcu_do_batch只处理nxtlist -- *nxttail[RCU_DONE_TAIL]之间的callbacks。每个GP结束都会重新调整callback所处的段位,每个新的callback将会添加在末尾,也就是*nxttail[RCU_NEXT_TAIL]。
2 可抢占的RCU
如果config文件定义了CONFIG_TREE_PREEMPT_RCU=y,那么sychronize_rcu将默认使用rcu_preempt_state。这类rcu的特点就在于read_lock期间是允许其它进程抢占的,因此它判断宽限期度过的方法就不太一样。
从rcu_read_lock和rcu_read_unlock的定义就可以知道,TREE_PREEMPT_RCU并不是以简单的经过抢占为CPU渡过GP的标准,而是有个rcu_read_lock_nesting计数
- void __rcu_read_lock(void)
- {
- current->rcu_read_lock_nesting++;
- barrier();/* critical section after entry code. */
- }
- void __rcu_read_unlock(void)
- {
- struct task_struct *t = current;
- if(t->rcu_read_lock_nesting !=1){
- --t->rcu_read_lock_nesting;
- }else{
- barrier();/* critical section before exit code. */
- t->rcu_read_lock_nesting = INT_MIN;
- barrier();/* assign before ->rcu_read_unlock_special load */
- if(unlikely(ACCESS_ONCE(t->rcu_read_unlock_special)))
- rcu_read_unlock_special(t);
- barrier();/* ->rcu_read_unlock_special load before assign */
- t->rcu_read_lock_nesting =0;
- }
- }
当抢占发生时,__schedule函数会调用rcu_note_context_switch来通知RCU更新状态,如果当前CPU处于rcu_read_lock状态,当前进程将会放入rnp->blkd_tasks阻塞队列,并呈现在rnp->gp_tasks链表中。
从上文1.3节宽限期的结束处理过程我们可以知道,rcu_gp_kthread会判断! (rnp->qsmask) && !rcu_preempt_blocked_readers_cgp(rnp))两个条件来决定GP是否完成,其中!rnp->qsmask代表每个CPU都经过一次quiescent state,quiescent state的定义与传统RCU一致;!rcu_preempt_blocked_readers_cgp(rnp)这个条件就代表了rcu是否还有阻塞的进程。