GNN在计算机视觉中的应用综述
摘 要:近几年,机器学习和深度学习发展迅速。研究人员借鉴了卷积神经网络(CNN)、循环神经网络(RNN)和深度自动编码器(AutoEncoder)的思想,定义和设计了用于处理图数据的神经网络结构,这类方法统称为图神经网络(Graph Neural Networks,GNN)。如今,GNN在人工智能领域应用广泛,其中最大应用领域之一是计算机视觉(Computer Vision, CV)。近年来,国内外许多研究机构和科研人员不断探索利用GNN解决图像分类、目标检测、动作识别等多种计算机视觉任务,并取得很多优秀成果。
关键词:GNN;计算机视觉;深度学习
1引 言
计算机视觉是以图像或视频为输入,以对环境的表达和理解为目标,研究图像信息组织、物体和场景识别、进而对事件给予解释的学科,诞生于1966年MIT AI Group的“the summer vision project”。计算机视觉经过50余年的发展,已成为一个十分活跃的研究领域。据统计,目前互联网上超过70%的数据是图像和视频,全世界的监控摄像头数目已超过人口数,每天生成超过八亿小时的监控视频数据。如此大的数据量亟待自动化的视觉理解与分析技术。作为深度学习的新兴领域,GNN因强大而灵活的特性,在计算机视觉的相关任务上取得不俗成绩。本文主要介绍GNN在图像分类(Image Classification)、目标检测(Object Detection)、图像分割(Object Segmentation)、图像重构(Image Reconstruction)、图像生成(Image Synthesis)、视觉问答(Visual Question & Answering,VOA)、行为识别(Action Recognition)、3D视觉(3D vision)等计算机视觉任务。
2 GNN在CV中应用现状
2.1 图像分类
2.1.1 概念
图像分类是指给定一组被标记为单一类别的图像,对一组新的测试图像的类别进行预测,并计算预测的准确性结果。
2.1.2 经典模型
GNN模型在图像分类研究领域始于1998年,当年Yann Lecun发表的关于卷积神经网络的探索[1],但在深度学习真正爆发之前历经了多年的沉寂。随着机器处理能力的大幅提升,以及海量的数据和先进的算法技术的涌现,陆续出现了AlexNet[2]、VGGnet[3]、GoogLeNet[4]、ResNet[5]、SENet[6]等。目前较为流行的图像分类架构是CNN,它将图像送入网络,网络再对图像数据分类。现在,大部分图像分类技术都是在ImageNet数据集上开展训练。
- AlexNet
AlexNet是(首届ImageNet竞赛)ILSVRC2012的冠军,由Alex Krizhevsky等人提出,错误率首次达到15.4%。AlexNet创新:使用ReLU激活函数;使用dropout;大量使用数据扩充技术。AlexNet极大地震动了计算机视觉领域,使人们意识到卷积神经网络的优势,促使深度学习和卷积神经网络的爆发性增长。
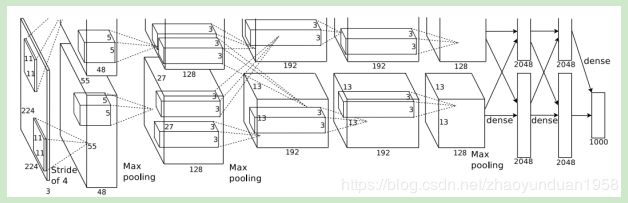
图1 AlexNet模型网络结构图
- VGGnet
VGGnet是ISLVRC2014亚军,由牛津大学的Karen Simonyan和Andrew Zisserman于2014年提出。VGGnet展示了可以在先前网络架构的基础上通过增加网络层数和深度来提高网络的性能。VGGnet包含16-19层权重网络,比先前的网络架构更深层数更多。VGGnet关键点:结构简单,只有3×3卷积和2×2卷积两种配置;参数多,且大部分参数集中在全连接层中;合适的网络初始化和使用批量归一层对训练深层网络很重要。

图2 VGGnet模型网络结构图
(3)GoogleNet
GoogleNet是ISLVRC2014冠军,是由Google的Christian Szegedy等人提出的22层神经网络,错误率仅6.7%。该模型架构极大改善了计算机计算资源的利用率:模型的计算开销在深度和宽度增加的情况下保持常数。GoogleNet在模型中引入Inception模块,利用非序列化的并行方式来提高模型的性能。

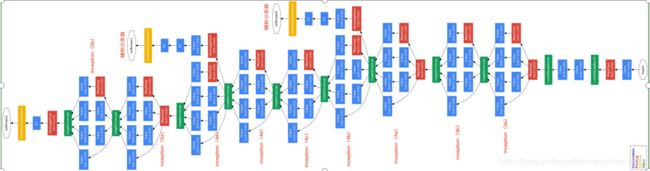
图3 GoogleNet模型网络结构图
(4)ResNet
ResNet是ILSVRC2015冠军,由微软的Kaiming He等人提出。ResNet旨在解决网络加深后训练难度增大的问题。ResNet创新:使用快捷连接,使训练深层网络更容易,并且重复堆叠相同的模块组合;大量使用批量归一层;对于深层网络(超过50层),ResNet使用了更高效的瓶颈(bottleneck)结构。
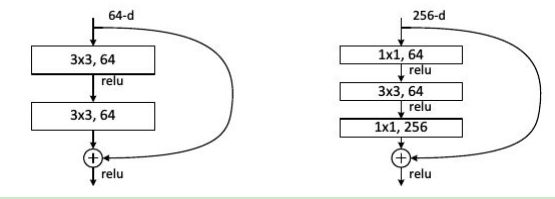
图4 快捷结构(左图)与瓶颈结构(右图)示意图
(5)SENet
SENet是ILSCRV2017冠军。SENet包含特征压缩、激发和重配权重等过程。SENet在不引入新的空间维度的前提下,使用了“特征重标定”的策略对特征进行处理;通过学习获取每个特征通道的重要程度,根据重要性抑制或提升相应的特征,最终在当年的比赛测试集中达到2.251%的Top-5错误率。
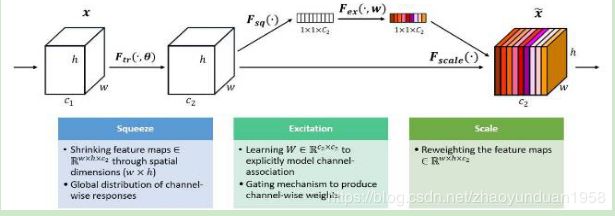
图5 SENet 模型示意图
2.1.3 图像分类算法
(1)输入是由N个图像组成的训练集,共有K个类别,每个图像都被标记为其中一个类别。
(2)使用该训练集训练一个分类器,学习每个类别的外部特征。
(3)预测一组新图像的类标签,评估分类器的性能,用分类器预测的类别标签与真实的类别标签进行比较。
2.2 目标检测
2.2.1 概念及分类
给定一张输入图片,算法自动找出图片中的常见物体,并将其所属类别及位置输出出来。目标检测可分为单物体检测和多物体检测,包含人脸检测(Face Detection),车辆检测(Viechle Detection)等。
2.2.2 算法
分三类:第一类,传统的目标检测算法(Cascade + HOG/DPM + Haar/SVM等);第二类,基于Region Proposal的R-CNN系算法(R-CNN[7],Fast R-CNN[8],Faster R-CNN[9],R-FCN[10]等two-stage算法),算法先产生目标候选框,再对候选框做分类与回归;第三类,基于直接回归的目标检测算法(YOLO[11],YOLO(v3)[12],SSD[13]等one-stage算法),仅用一个CNN直接预测不同目标的类别与位置。
- 传统的目标检测算法
基本思路:对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,CNN会输出该框得分(classification)以及这个框图片对应的x,y,h,w(regression)。
存在问题:1)基于滑动窗口的区域选择策略无针对性,时间复杂度高,窗口冗余;2)手工设计的特征对多样性的变化无很好的鲁棒性。
(2)基于区域的卷积神经网络(R-CNN)
R-CNN基本思路:输入一张图片,通过指定算法从图片中提取2000个类别独立的候选区域;对每个候选区域,用CNN获取一个特征向量;对每个区域相应的特征向量,用支持向量机(SVM)进行分类,并通过一个bounding box regression调整目标包围框的大小。
R-CNN贡献:使用CNN提取特征,使用bounding box regression进行目标包围框的修正。R-CNN缺点:训练和推理速度慢,需要大量的磁盘空间。
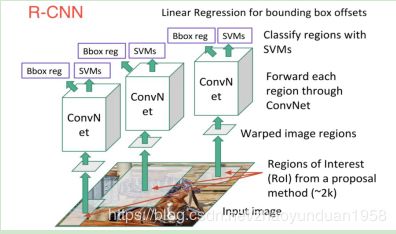
图6 R-CNN模型结构图
Fast R-CNN基本思路:采用selective search提取2000个候选框RoI;使用一个CNN对全图进行特征提取;使用一个RoI Pooling Layer在全图特征上提取每个RoI对应的特征;分别经过为21和84维的全连接层。
Fast R-CNN贡献:取代R-CNN的串行特征提取方式,直接采用一个CNN对全图提取特征;除了selective search,其他部分都可合在一起训练。Fast R-CNN缺点:耗时的selective search依旧存在。
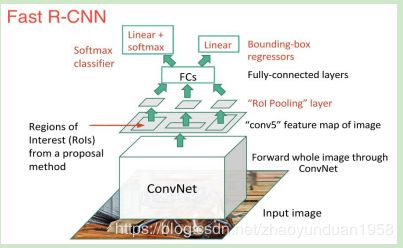
图7 Fast R-CNN模型结构图
Faster R-CNN基本思路:整张图片经CNN,得到feature map;卷积特征输入到RPN,得到候选框的特征信息;对候选框中提取出的特征,使用分类器判别是否属于一个特定类;对属于某一类别的候选框,用回归器进一步调整位置。Faster R-CNN使用RPN取代SS算法获取RoI,实现端到端的训练。
Faster R-CNN由共享卷积层、RPN、RoI pooling及分类和回归四部分组成。
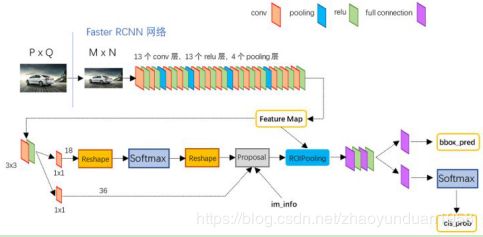
图8 Faster R-CNN模型结构图
(3)基于直接回归的目标检测算法
YOLO基本思路:将输入图像划分成7*7的网格;对每个网格,都预测2个边框;根据上一步可预测出7*7*2个目标窗口,根据阈值去除可能性比较低的目标窗口,由NMS去除冗余窗口。YOLO主要构成:卷积层,目标检测层,NMS筛选层。
YOLO算法贡献:开创one-stage检测先河,它将物体分类和物体检测网络合二为一,都在全连接层完成,大大降低目标检测的耗时,提高了实时性。YOLO算法缺点:识别物体位置精准性差;召回率低。

图9 YOLO模型结构图
SSD基本思想:SSD结合YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN类似精度。SSD和YOLO都采用一个CNN网络来检测,但却采用多尺度特征图。SSD分为卷积层,目标检测层和NMS筛选层。

图10 SSD模型结构图
2.3 图像分割
2.3.1 概念及分类
图像分割是基于图像检测的,它需要检测到目标物体,然后把物体分割出来。
2.3.2 分类
图像分割分三种:
(1)普通分割:将不同分属于不同物体的像素区域分开,如前景区域和后景区域的分割;
(2)语义分割:在普通分割基础上,把属于同一类的像素归为一类,比如分割出不同类别的物体。代表模型有FCN[14],它提出了端到端的卷积神经网络体系结构,在没有任何全连接层的情况下进行密集预测。这种方法允许针对任何尺寸的图像生成分割映射,并且比块分类算法快得多,几乎后续所有的语义分割算法都采用了这种范式。
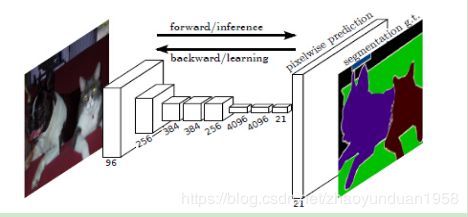
图11 FCN模型结构图
(3)实例分割:在语义分割基础上,分割出每个实例物体,比如对图片中的每个人都分割出来,识别出它们是不同的个体。代表模型有Mask R-CNN[15],它用FPN进行目标检测,并通过添加分类、坐标回归和分割三个输出分支进行语义分割。另一代表模型是Mask Scoring R-CNN[16],它研究了实例分割中mask得分问题,通过给Mask R-CNN添加MaskIoU head,把mask的得分和MaskIoU结合起来进行预测,不同于以往的实例分割框架。

图12 Mask R-CNN整体架构
2.4 图像重构
图像重构,也称图像修复(Image Inpainting),目的是修复图像中缺失的地方,比如修复一些老的有损坏的黑白照片和影片。2018年,NVIDIA使用“Partial Convolutions”[17],瞬间“修补”照片中被删除的部分,实现了一键P图,通过使用“部分卷积”层,该方法效果优于其他方法。余家辉提出的基于深度生成模型的方法DeepFill v1[18],不仅可以生成新的图像结构,还能很好利用周围的图像特征作为参考,以做出更好预测。该模型是一个前馈卷积神经网络,可处理包含多个缺失区域的图像,且在修复图像的时候,输入图像大小没有限制,在人脸图像、自然图像、纹理图像等测试集上,都好于现有方法效果。Kamyar Nazeri等人[19]提出用两阶段对抗网络,生成edge,恢复被污染的图片,能较好复原被破坏的细节。
2.5 图像生成
图像生成是根据一张图片生成修改部分区域的图片或是全新图片的任务。图像生成使用2014年提出GAN[20]模型。GAN利用博弈不断地优化生成器和判别器,使得生成的图像与真实图像在分布上越来越相近。2016年,DeepMind的Aaron van den Oord 提出PixelCNN[21],并引入Gated PixelCNN。Gated PixelCNN基于对像素点的概率分布进行建模,凭借一组描述性的向量,可生成大量有变化的图片。2018年,DeepMind的Andrew Brock等人提出BigGAN[22],BigGAN通过把正交正则化的思想引入GAN,对输入先验分布z的适时截断,大大提升了GAN的生成性能,保证了大型生成对抗网络训练过程的稳定性。该模型生成数据的质量远超之前方法。
2.6 视觉问答
视觉问答(VQA)是近年来非常热门的一个方向,是对视觉图像的自然语言问答,作为视觉理解 (Visual Understanding) 的一个研究方向,连接着视觉和语言,模型需要在理解图像的基础上,根据具体问题然后作出回答。除问答以外,还有一种算法被称为标题生成算法(Caption Generation),即计算机根据图像自动生成一段描述该图像的文本,而不进行问答。对于这类跨越两种数据形态(如文本和图像)的算法,称为多模态,或跨模态问题。
VQA模型一般是先分别对图像和问题提取特征,然后联合这两个做一些多模态融合处理,最终经过分类器输出答案。
VQA使用的融合图像和文本特征方法包括:
- 联合嵌入方法(joint embedding approaches),即学习视觉与自然语言的两个不同模态特征在一个共同的特征空间的嵌入表达(embedding)。Zhou Yu等人[23]提出MFB模型,使用一种端对端深度学习网络设计了一种“co-attention”(双重注意)机制,实现同时在图像和问题上学习,并将MFB模型和双重注意学习结合成一个专门针对VQA开发的网络模型。
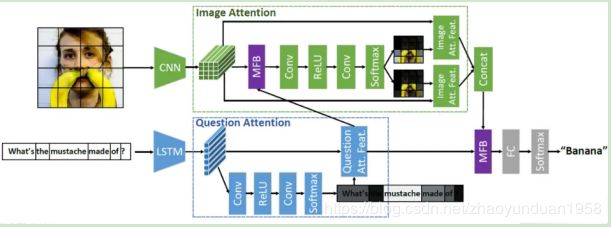
图13 带有“co-attention”的MFB模型
- 注意力机制(attention mechanisms)。在VQA中,attention能够根据具体的问题,把重点集中在想要的图像特征中(权重),最后给出答案。
- 组合模型(compositional models)。把模型分解为模块的组合的方法,模块化有利于任务分解,重用等。Jacob Andreas[24]等人提出NMN模型,该模型将问题进行语义分析,得到语法树,然后使用特定的模块来代替树的每个节点,最后构成一个总模型。
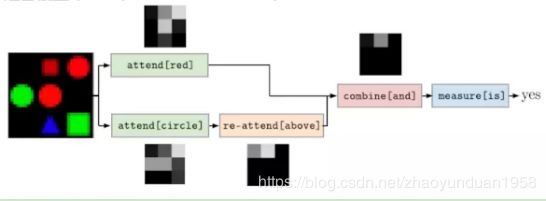
图14 NMN模型
- 知识增强方法(knowledge base-enhanced approaches)。该法结合图片以外额外知识,如关于某个词的描述,作答。Qi Wu[25]等人将综合Attributes(从图片captions中提取)和External Knowledge(属性相关描述)转化的向量,得到最终答案。
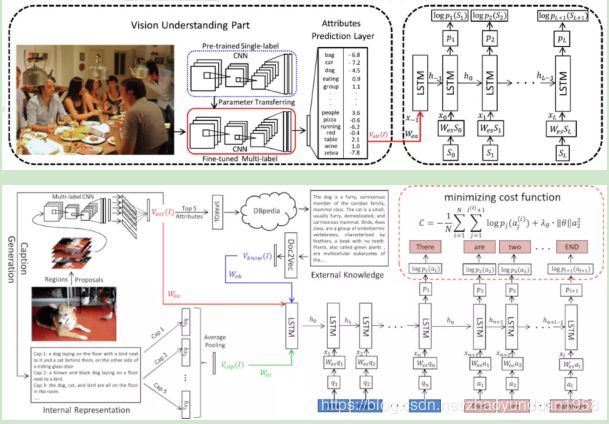
图15 论文模型
2.7 行为识别
2.7.1 概念
人体行为识别主要根据采集到的视频来分析人体行为,这在视频监控、医疗康复、健身评估、人机交互等领域应用广泛,是计算机视觉研究的热点问题。
2.7.2 处理步骤
动作时域分割,特征提取,特征处理,学习算法输出结果。

图 16 行为识别流程
2.7.3 GNN应用
(1)动作时域分割算法
Lea等人[26]提出TS-CNN方法,引入低级编码视觉信息的时空CNN(ST-CNN)和捕获高级时间信息的半马尔可夫模型。ST-CNN的空间分量是VGG 的一个变体,用于编码对象状态、位置和对象间关系的细粒度任务。分段组件使用半马尔可夫和条件随机场(CRF)共同分割并分类动作。Lea等人[27]提出了TCN方法,TCN又可分为ED-TCN和Dilated TCN,其中ED-TCN引入了编码和解码网络,而Dilated TCN是从WaveNet改进过来的,但它们又具有共同的特点:a)计算层次执行,这意味着每个时间步同步更新,而不是逐帧更新;b)卷积是时间计算;c)在每个帧处的预测是固定长度的时间段的函数,被称为接收场。其中ED-TCN的效果优于Dilated TCN。
上述方法是目前研究的热点,一般都使用CNN(或自动编码器)加其他机器学习方法的组合,效果也要优于其他方法,但是对硬件配置的要求较高,而且依赖大量的数据,实现起来比较困难,不过模型小型化也是一个不错的选择。
- 提取特征算法
1)时空网络
一般使用CNN提取空间特征,再利用LSTM等方法提取时间信息,时间信息和空间信息使用的类似于电路中的串联架构,这种网络架构在早期的方法中比较流行,效果一般也优于传统方法,得到广泛应用。Li Chuankun等人[28]提出了基于LSTM和CNN的方法,提取多个人工定义的不同特征,然后分别输入到3个LSTM网络和7个CNN网络,再把这10个网络进行融合,并提出最大融合、平均融合和逐元素相乘融合三种融合方式,最后输出最终结果,其中逐元素相乘融合表现最好。Wang 等人[29]提出3D CNN和LSTM相结合的网络,同时对原始视频进行显著性检测,这可以有效降低网络的参数,降低训练的难度,另外对3D CNN在sport-1M上进行预训练,该方法在UCF-101上能达到84.0%的识别率。
2)双流网络(Two-Stream Convolutional Networks)
Simonyan等人[30]在2014年首次提出了创造性的双流网络,它采用两个相同的CNN,其中一个网络输入视频帧以获取空间信息,另一个网络输入视频的光流信息以获取时间信息,最后两个网络进行融合,融合方式为平均融合或使用SVM进行融合分类,其中使用SVM进行融合分类效果表现最好。同时,很多人在双流网络上进行了一系列的改进。Feichtenhofer等人[31]从融合策略上进行改进,即从中间开始进行融合,实验效果比原有的双流网络好,同时显著减少了参数的数量。Wang等人[32]在双流网络的基础上,加入了分段和稀疏化采样的思想,提出TSN网络,这样不仅可以减少复杂度,还可以对多个分段进行融合,能够获取更多的上下文信息。时间流网络的输入使用弯曲的光流(warped optical flow fields)来代替原有光流,这样可以消除相机运动带来的影响。
双流网络时目前研究重点框架,不仅是由于效果好,而且为行为识别的并联架构提供了很好的思路。但GNN对硬件要求高,极度依赖海量的数据,对实际应用提出了新的挑战。
2.8 3D视觉
继卷积神经网络在2D视觉上获得前所未有的成功之后,近几年,如何让计算机理解3D世界,特别是如何延续深度学习技术在3D视觉问题上的表现受到了越来越多的研究人员的关注。3D视觉数据的表示方式有多种,其中,最具代表性的点云(Point Cloud)数据的学习。点云数据是一种有效的三维物体的表示方法,它随着深度感知技术发展而流行起来。点云数据由一组点组成,每个点都记录有三维坐标(x,y,z),此外,还可记录采集点的颜色、强度等其他丰富的信息,被广泛应用于无人驾驶、体感游戏、文化数字遗产保护、医疗、城市规划、农林业等领域。
点云数据同图数据一样,是一种非规则结构的数据,无法用卷积神经网络进行处理中来。图卷积技术的发展极大地推动了点云的处理方法的进步,人们提出了很多基于GNN的方法,在点云分类、分割等问题上展现了优异的性能。
点云数据中的点是离散存在的,点与点间的距离d是确定点彼此间关系的基础。基于点坐标(x,y,z)的欧式空间距离是一种常见的选择;其他非欧式空间的距离选择如测地(geodesic)距离、形 状感知距离等,可以很好地处理非刚性特征,也被很多研究者应用,如Charles R.Qi等人提出的PointNet++算法[33]。有了距离即可确定点与点之间的邻接关系。如何将距离转化成邻接关系,成为运用GNN技术的一个关键点。点之间的邻接关系在每一层的图中并不是固定不变的。PointNet++算法中采用了每一层固定邻域点进行卷积操作的策略,而在Edge-Conv的算法[34]中,每一层中的图都可以动态地调整图中节点之间的邻接关系,K邻域内的点随着网络的更新发生变化,这样就能自适应地捕捉和更新点云的局部几何特征,在点云分类和分割中取得很好的效果。
3 GNN在VC应用趋势
3.1 强大的图数据拟合能力
作为一种建立在图上的端对端学习框架,GNN展示出了强大的图数据拟合能力。图数据是科学与工程学领域中一种十分常见的数据研究对象,因此,GNN也被应用到很多相关场景,并且都取得了不错的效果。通常这些应用均会利用GNN去拟合研究对象的一些性质,从而指导或加速相应的科研与开发工作。
3.2 强大的推理能力
计算机要完成推理任务,离不开对语义实体的识别以及实体之间关系的抽取,GNN理所当然地被应用到了很多推理任务的场景中去。相较于之前大多基于关系三元组的建模方式,GNN能够对表征语义关系的网络进行整体性的建模,习得更加复杂与丰富的语义信息,这对提升推理任务的效果大有裨益。比如计算机视觉中的视觉问答、视觉推理等。
4 GNN在VC应用展望
4.1在推理任务上的应用与学习机制的研究改进
推理任务已经成为当下深度学习系统面临的核心任务之一,GNN虽然已经展现出了在相关任务上的独特优势,但是内在的作用机理还有待充分研究。通过对其学习机制的不断完善与发展,来促使GNN在更多、更复杂的推理任务中获得更好的表现。
4.2对超大规模图建模的支持
现有的大多数图神经网络都无法扩展到规模巨大的图数据中去。GNN的训练是一种协同的学习方式,在一次迭代中,节点固有的上下文会导致其状态的更新需要涉及大量邻居节点的隐藏状态,复杂度极高,难以应用小批量训练方式提升计算效率。尽管已有研究提出基于抽样与分区的手段来解决这类问题,但这些手段仍不足以扩展到工业级超大规模属性图的学习中去。
参考文献
- Yann Le Cun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278–2324.
- Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]// NIPS 2012.
- Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[C]// ICLR 2015.
- Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]// CVPR 2015.
- He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition[C]// CVPR 2016.
- Jie Hu, Li Shen, Gang Sun. Squeeze-and-Excitation Networks[C]// CVPR 2017.
[7] Ross Girshic,Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// CVPR 2014.
[8] R. Girshick, Fast R-CNN[C]// ICCV 2015.
[9] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[C]// NIPS 2015.
[10] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: Object detection via region-based fully convolutional networks[C]// NIPS 2016.
[11] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once:Unified, real-time object detection[C]// CVPR 2016.
[12] J. Redmon and A. Farhadi. YOLOv3: An incremental improvement. arXiv, 2018.
[13] Liu, Wei, et al. SSD: Single shot multibox detector. European Conference on Computer Vision. Springer International Publishing, 2016.
[14] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation[C]// CVPR 2015.
[15] Kaiming He, Georgia Gkioxari, et al.Mask R-CNN[C]// ICCV 2017.
[16] Zhaojin Huang, Lichao Huang, Yongchao Gong, Chang Huang, Xinggang Wang.Path Aggregation Network for Instance Segmentation[C]// CVPR 2019.
[17] Guilin Liu,Fitsum A. Reda, et al.Image Inpainting for Irregular Holes Using Partial Convolutions. arXiv, 2018.
[18] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, Thomas S. Huang. Generative Image Inpainting with Contextual Attention[C]// CVPR 2018.
[19] Kamyar Nazeri, Eric Ng, et al. Generative Image Inpainting with Adversarial Edge Learning. arXiv, 2019.
[20] Ian J. Goodfellow, et al. Generative Adversarial Networks[C]// NIPS 2014.
[21] Aaron van den Oord, et al.Conditional Image Generation with PixelCNN Decoders[C]// NIPS 2016.
[22] Andrew Brock, Jeff Donahue, Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Synthesis[C]. ICLR 2019.
[23] Zhou Yu, Jun Yu, Jianping Fan, Dacheng Tao. Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering[C]// ICCV 2017.
[24] Jacob Andreas, Marcus Rohrbach, Trevor Darrell, Dan Klein. Neural Module Networks. arXiv, 2017.
[25] Qi Wu, Chunhua Shen, Anton van den Hengel, Peng Wang, Anthony Dick. Image Captioning and Visual Question Answering Based on Attributes and External Knowledge. arXiv, 2016.
[26] Lea C, Reiter A, Vidal R, et al. Segmental spatiotemporal cnns for fine-grained action segmentation[C]// ECCV 2016: 36-52.
[27] Lea C, Flynn M D, Vidal R, et al. Temporal convolutional networks for action segmentation and detection[C]// CVPR 2017: 156-165.
[28] Li Chuankun, Wang Pichao, Wang Shuang, et al. Skeleton-based action recognition using LSTM and CNN[C]// Proc of IEEE International Conference on Multimedia & Expo. 2017: 585-590.
[29] Wang Xuanhan, Gao Lianli, Song Jingkuan, et al. Beyond frame-level cnn: Saliency-aware 3D CNN with lstm for video action recognition[J]. IEEE Signal Processing Letters, 2017, 24 (4): 510-514.
[30] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]// NIPS 2014: 568-576.
[31] Feichtenhofer C, Pin A, Zisserman A. Convolutional Two-Stream Network Fusion for Video Action Recognition [C]// CVPR 2016:1933-1941.
[32] Wang Limin, Xiong Yuanjun, Wang Zhe, et al. Temporal segment networks:
Towards good practices for deep action recognition[C]// ECCV 2016: 20-36.
[33] Qi C R,Yi L,Su H,et al. Pointnet++:Deep hierarchical feature learning on point sets in a metric space[C]// NIPS 2017:5099-5108.
[34] Wang Y,Sun Y,Liu Z,et al. Dynamic graph cnn for learning on point clouds. arXiv, 2018.