Flink 流处理流程 API详解
目录
流处理的简单流程
Environment 执行环境
Source 初始化数据
transform 执行转换操作
sink 输出结果
execute 程序触发
流处理API的衍变
Storm:TopologyBuilder 构建图的工具,然后往图中添加节点,指定节点与节点之间的有向边是什么。构建完成后就可以将这个图提交到远程的集群或者本地的集群运行。
Flink:不同之处是面向数据本身的,会把DataStream 抽象成一个本地集合,通过面向集合流的编程方式进行代码编写。两者没有好坏之分,Storm比较灵活自由。更好的控制。在工业界Flink会更好点。开发起来比较简单、高效。经过一些列优化、转化最终也会像Storm一样回到底层的抽象。Strom API 是面向操作的,偏向底层。Flink 面向数据,相对高层次一些。
流处理的简单流程
其他分布式处理引擎一样,Flink应用程序也遵循着一定的编程模式。不管是使用 DataStream API还是 DataSet API基本具有相同的程序结构,如下代码清单所示。通过流式计算的方式实现对文本文件中的单词数量进行统计,然后将结果输出在给定路径中。
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
// 1、获取运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、通过socket获取源数据
DataStreamSource sourceData = env.socketTextStream("192.168.52.12", 9000);
/**
* 3、数据源进行处理
* flatMap方法与spark一样,对数据进行扁平化处理
* 将每行的单词处理为
*/
DataStream> dataStream = sourceData.flatMap(new FlatMapFunction>() {
public void flatMap(String s, Collector> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2(word, 1));
}
}
})
// 相同的单词进行分组
.keyBy(0)
// 聚合数据
.sum(1);
// 4、将数据流打印到控制台
dataStream.print();
/**
* 5、Flink与Spark相似,通过action进行出发任务执行,其他的步骤均为lazy模式
* 这里env.execute就是一个action操作,触发任务执行
*/
env.execute("streaming word count");
}
} 整个Flink程序一共分为5步,分别为设定Flink执行环境、创建和加载数据集、对数据集指定转换操作逻辑、指定计算结果输出位置、调用execute方法触发程序执行。对于所有的Flink应用程序基本都含有这5个步骤,下面将详细介绍每个步骤。

操作概览
如果给你一串数据你会怎么去处理它?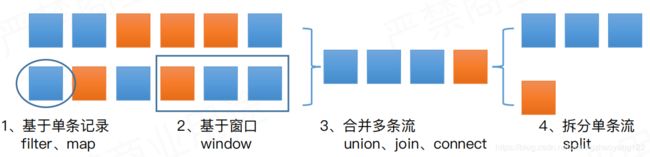
【1】基于单条记录进行 Filter、Map
【2】基于窗口 window 进行计算,例如小时数,看到的就不一定是单数。
【3】有时会可能会合并多条流 union(多个数据流合并成一个大的流)、Join(多条流按照一定的条件进行合并)、connect(针对多种不同类型的流进行合并)。
【4】有时候需要将一条流拆分成多个流,例如 split,然后针对特殊的流进行特殊操作。
DataStream 基本转换
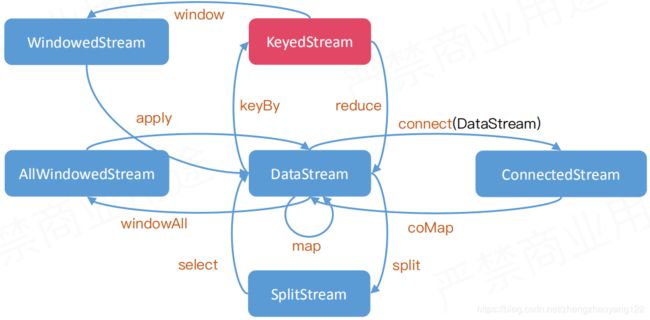
【1】对 DataStream 进行一对一转换,输入是SataStream 输出也是 DataStream。比较有代表性的,例如map;
【2】将一条DataStream 拆分成多条,例如使用 split,并给划分后的每一个结果都打上一个标签;
【3】通过调用 SplitStream 对象的 select 方法,根据标签抽取一个感兴趣的流,它也是一个 DataStream对象。
【4】把两条流通过 connect 合并成一个 ConnectedSteam,对 ConnectedSteam流的操作可能与 DataStream 流的操作有不太一样的地方。ConnectedSteam 中不同类型的流在处理的时候对应不同的 process 方法,他们都位于同一个 function中,会存在一些共享的数据信息。我们在后期做一些底层的join操作的时候都会用到这个 ConnectedSteam。
【5】对ConnectedSteam 也可以做类似于 Map的一些操作,它的操作名叫coMap,但是在API中写法是 Map。
【6】我们可以对流按照时间或者个数进行一些切分,可以理解为将无线的流分成一个一个的单位流,怎么切分根据用户自定的逻辑决定的。例如调用 windowAll 生成一个 AllWindowedStream。
【7】我们对 AllWindowedStream 去应用自己的一些业务逻辑(apply),最终形成原始的 DataStream。
【8】对 DataStream 进行keyBy 进行分组操作形成 KeyedStream。
【9】我们不能对普通的 DataStream 做 reduce操作,只能对 KeyedStream 进行 reduce。主要出于计算量的考虑。
【10】我们也可以对 KeyedStream 进行 window 操作形成 WindowedStream。
【11】我们对 WindowedStream 进行 apply 操作,形成原始的 DataStream 操作。
Environment 执行环境
【1】getExecutionEnvironment:创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,与就是说,执行环境决定了程序执行在什么环境 getExecutionEnvironment 会根据查询运行的方式返回不同的运行环境,是最常用的一种创建执行环境的方式。批量处理作业和流式处理作业分别使用的是不同的ExecutionEnvironment。例如 StreamExecutionEnvironment是用来做流式数据处理环境,ExecutionEnvironment是批量数据处理环境。
//流处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//块梳理
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();如果没有设置并行度,会以 flink-conf.yaml 中的配置为准,默认为1:parallelism.default:1
//可以设置并行度(优先级最高)
env.setParallelism(1);如果是本地执行环境底层调用的是 createLocalEnvironment:需要在调用时指定默认的并行度
val env = StreamExecutionEnvironment.createLocalEnvironment(1)如果是集群执行环境 createRemoteEnvironment:将 Jar 提交到远程服务器,需要在调用时指定 JobManager 的 IP和端口号,并指定要在集群中运行的Jar包。flink 将这两种都进行了包装,方便我们使用。
var env = ExecutionEnvironment.createRemoteEnvironment("jobmanager-hostname",6123,"YOURPATH//wordcount.jar")Source 初始化数据
创建完成 ExecutionEnvironment后,需要将数据引入到 Flink系统中。ExecutionEnvironment 提供不同的数据接入接口完成数据的初始化,将外部数据转换成 DataStream或 DataSet数据集。如以下代码所示,通过调用 readTextFile()方法读取file:///pathfile路径中的数据并转换成 DataStream数据集。我们可以吧 streamSource 看做一个集合进行处理。
//readTextFile读取文本文件的连接器 streamSource 可以想象成一个集合
DataStreamSource streamSource = env.readTextFile("file:///path/file"); 通过读取文件并转换为 DataStream[String]数据集,这样就完成了从本地文件到分布式数据集的转换,同时在 Flink中提供了多种从外部读取数据的连接器,包括批量和实时的数据连接器,能够将Flink系统和其他第三方系统连接,直接获取外部数据。
transform 执行转换操作
数据从外部系统读取并转换成 DataStream或者 DataSet数据集后,下一步就将对数据集进行各种转换操作。Flink 中的Transformation操作都是通过不同的 Operator来实现,每个 Operator内部通过实现 Function接口完成数据处理逻辑的定义。在DataStream API 和 DataSet API提供了大量的转换算子,例如map、flatMap、filter、keyBy等,用户只需要定义每种算子执行的函数逻辑,然后应用在数据转换操作 Dperator接口中即可。如下代码实现了对输入的文本数据集通过 FlatMap算子转换成数组,然后过滤非空字段,将每个单词进行统计,得到最后的词频统计结果。
DataStream> dataStream = sourceData.flatMap(new FlatMapFunction>() {
public void flatMap(String s, Collector> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2(word, 1));
}
}
// keyBy 相同的单词进行分组,sum聚合数据
}).keyBy(0).sum(1); 在上述代码中,通过 Java接口处理数据,极大地简化数据处理逻辑的定义,只需要通过传入相应 Lambada计算表达式,就能完成 Function定义。特殊情况下用户也可以通过实现 Function接口来完成定义数据处理逻辑。然后将定义好的 Function应用在对应的算子中即可。Flink中定义 Funciton的计算逻辑可以通过如下几种方式完成定义。
【1】通过创建 Class实现 Funciton接口
Flink中提供了大量的函数供用户使用,例如以下代码通过定义MyMapFunction Class实现MapFunction接口,然后调用DataStream的map()方法将 MyMapFunction实现类传入,完成对实现将数据集中字符串记录转换成大写的数据处理。
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
DataStreamSource sourceData = env.socketTextStream("192.168.52.12", 9000);
//......
//数据源进行处理
sourceData.map(new MyMapFunciton());
//......
}
}
class MyMapFunciton implements MapFunction {
@Override
public String map(String s) throws Exception {
return s.toUpperCase();
}
} 【2】通过创建匿名类实现 Funciton接口
除了以上单独定义 Class来实现 Function接口之处,也可以直接在 map()方法中创建匿名实现类的方式定义函数计算逻辑。
DataStreamSource sourceData = env.socketTextStream("192.168.52.12", 9000);
//通过创建 MapFunction 匿名函数来定义 Map 函数计算逻辑
sourceData.map(new MapFunction() {
@Override
public String map(String s) throws Exception {
//实现字符串大写转换
return s.toUpperCase();
}
}); 【3】通过实现 RichFunciton接口
前面提到的转换操作都实现了Function接口,例如 MapFunction和 FlatMapFunction接口,在 Flink中同时提供了RichFunction接口,主要用于比较高级的数据处理场景,RichFunction接口中有open、close、getRuntimeContext和setRuntimeContext等方法来获取状态,缓存等系统内部数据。和 MapFunction相似,RichFunction子类中也有 RichMapFunction,如下代码通过实现RichMapFunction定义数据处理逻辑。
sourceData.map(new RichFunction() {
@Override
public void open(Configuration configuration) throws Exception {
}
@Override
public void close() throws Exception {
}
@Override
public RuntimeContext getRuntimeContext() {
return null;
}
@Override
public IterationRuntimeContext getIterationRuntimeContext() {
return null;
}
@Override
public void setRuntimeContext(RuntimeContext runtimeContext) {
}
});分区Key指定:在 DataStream数据经过不同的算子转换过程中,某些算子需要根据指定的key进行转换,常见的有 join、coGroup、groupBy类算子,需要先将 DataStream或 DataSet数据集转换成对应的 KeyedStream和 GroupedDataSet,主要目的是将相同 key值的数据路由到相同的 Pipeline中,然后进行下一步的计算操作。需要注意的是,在 Flink中这种操作并不是真正意义上将数据集转换成 Key-Value结构,而是一种虚拟的 key,目的仅仅是帮助后面的基于 Key的算子使用,分区人 Key可以通过两种方式指定:
【1】根据字段位置指定
在DataStream API中通过 keyBy()方法将 DataStream数据集根据指定的 key转换成重新分区的 KeyedStream,如以下代码所示,对数据集按照相同 key进行sum()聚合操作。
// 根据第一个字段进行重分区,相同的单词进行分组。第二个字段进行求和运算
dataStream.keyBy(0).sum(1);在DataSet API中,如果对数据根据某一条件聚合数据,对数据进行聚合时候,也需要对数据进行重新分区。如以下代码所示,使用DataSet API对数据集根据第一个字段作为 GroupBy的 key,然后对第二个字段进行求和运算。
// 根据第一个字段进行重分区,相同的单词进行分组。max 求相同key下的最大值
dataStream.groupBy(0).max(1);【2】根据字段名称指定
KeyBy 和GroupBy 的Key 除了能够通过字段位置来指定之外,也可以根据字段的名称来指定。使用字段名称需要DataStream 中的数据结构类型必须是Tuple类或者 POJOs类的。如以下代码所示,通过指定name字段名称来确定groupby 的key字段。
DataStreamSource sourceData = env.fromElements(new Persion("zzx", 18));
//使用 name 属性来确定 keyBy
sourceData.keyBy("name").sum("age"); 如果程序中使用 Tuple数据类型,通常情况下字段名称从1开始计算,字段位置索引从0开始计算,以下代码中两种方式是等价的。
//通过位置指定第一个字段
dataStream.keyBy(0).sum(1);
//通过名称指定第一个字段名称
dataStream.keyBy("_1").sum("_2");【3】通过Key选择器指定
另外一种方式是通过定义Key Selector来选择数据集中的Key,如下代码所示,定义KeySelector,然后复写 getKey方法,从Person对象中获取 name为指定的Key。
DataStreamSource persionData = env.fromElements(new Persion("zzx", 18));
persionData.keyBy("name").sum("age");
persionData.keyBy(new KeySelector() {
@Override
public Object getKey(Persion persion) throws Exception {
return persion.getName();
}
}); 理解 KeyedStream
假设有一条数据流,可以利用窗口的操作,进行一些竖向的切分,得到就是一个个大的 AllWindowedStream,再根据 keyBy() 进行横向切分,把数据流中不同类别任务输入到不同的算子中进行处理,不同的算子之间是并行的操作。同时不同的节点只需要维护自己的状态。前提是 key数 >> 并发度
sink 输出结果
数据集经过转换操作之后,形成最终的结果数据集,一般需要将数据集输出在外部系统中或者输出在控制台之上。在Flink DataStream 和 DataSet接口中定义了基本的数据输出方法,例如基于文件输出 writeAsText(),基于控制台输出print()等。同时Flink在系统中定义了大量的 Connector,方便用户和外部系统交互,用户可以直接通过调用 addSink()添加输出系统定义的DataSink类算子,这样就能将数据输出到外部系统。以下实例调用 DataStream API中的 writeAsText()和 print()方法将数据集输出在文件和客户端中。
//将数据流打印到控制台
dataStream.print();
//将数据输出到文件中
dataStream.writeAsText("file://path/to/savenfile");execute 程序触发
所有的计算逻辑全部操作定义好之后,需要调用 ExecutionEnvironment的 execute()方法来触发应用程序的执行,因为flink在执行前会先构建执行图,再执行。其中 execute()方法返回的结果类型为 JobExecutionResult,里面包含了程序执行的时间和累加器等指标。需要注意的是,execute方法调用会因为应用的类型有所不同,DataStream流式应用需要显性地指定 execute()方法运行程序,如果不调用则 Flink流式程序不会执行,但对于 DataSet API输出算子中已经包含对 execute()方法的调用,则不需要显性调用 execute()方法,否则会出现程序异常。
//调用 StreamExecutionEnvironment 的 execute 方法执行流式应用程序
env.execute("App Name");物理分组
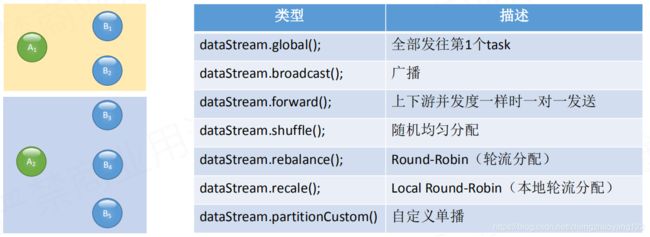
如上,有两个DataSource实例A1,A2。不同颜色代表不同的实例,Flink 为我们提供了比较完整的物理分组方案:
global() 作用就是无论你下游有多少个实例(B),上游的数据(A)都会发往下游的第一个实例(B1);
broadcast() 广播,对上游的数据(A)复制很多份发往下游的所有实例(B),数据指数级的增长,数据量大时要注意;
forward() 当上下游并发度一致的时候一对一发送,否则会报错;
shuffle() 随机均匀分配;
rebalance() 轮询;
recale() 本地轮流分配,例如上图A1只能看到两个实例B1和B2;
partitionCustom() 自定义单播;
类型系统
Flink 它里面的抽象都是强类型的,与它自身的序列化和反序列化机制有关。这个引擎对类型信息知道的越多,就可以对数据进行更充足的优化,序列化与反序列化就会越快。每一个DataStream 里面都需要有一个明确的类型和TypeInformation,Flink内置了如下类型,都提供了对应的 TypeInfomation。
API 原理
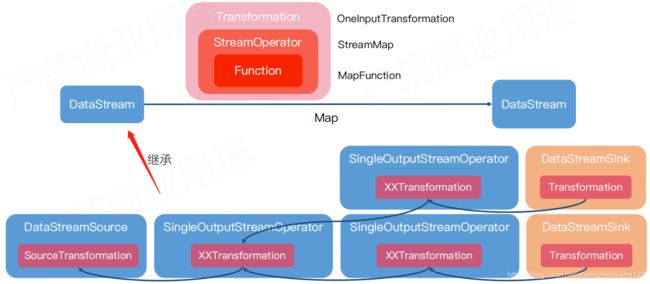
一个 DataStream 是如何转化成另一个 DataStream 的,其实我们调用 map方法的时候,Flink 会给我们创建一个 OneInputTransformation ,需要一个 StreamOperator 参数 Flink 内部会有预先定义好的 StreamMap转换的算子。Operator 内部我们需要自定义一个 MapFunction,一般Function才是我们写代码需要关注的点。如果需要更深一点就会写一些 Operator。

----架构师资料,关注公众号获取----