我写的ad
文章目录
- 训练姐和测试集合的product_category有没有不同的
- 训练姐和测试集合的advertiser_id有没有不同的
- 训练姐和测试集合的creative_id有没有不同的
- 训练姐和测试集合的product_id有没有不同的
- 训练姐和测试集合的user_id有没有相同的
- 在腾讯云上根据click_log_test随机给一个user_id一个age和gender看看能得几分
- 本地根据click_log_test随机给一个user_id一个age和gender看看能得几分
- 测试机概要
- click_log,csv
- ad.csv
- 怎么读取训练集啊
- 这样却失败了
- 获得三个文件大小
- 三个文件啥样子
- 分析三文件的内容
- click_log.csv的内容
- user.csv的内容
- ad.csv的东西
- ad_id唯一吗?
- advertiser_id唯一码?
- creative_id是唯一的吗?
- 没有清理前,我看看category的构成
- 对ad.csv清理\N
- 训练集和测试集
- 怎么获取测试机啊?
训练姐和测试集合的product_category有没有不同的
import pandas as pd
ad_test = pd.read_csv('D:\\txcent\\test\\ad_test.csv')
list1=list(ad_test['product_category'])
dict1=dict.fromkeys(list1)
ad = pd.read_csv('D:\\txcent\\ad.csv')
list2=list(ad['product_category'])
dict2=dict.fromkeys(list2)
print ("测试集一共有",len(dict1),"个product_category,算上\\N")
print ("训练集一共有",len(dict2),"个product_category,算上\\N")
number_1=0
number_2=0
number_3=0
for i in dict1:
if(i not in dict2):
number_1=number_1+1
else:
number_2=number_2+1
for i in dict2:
if(i not in dict1):
number_3=number_3+1
print ("测试集一共有",number_1,"个product_category没有出现在训练集中")
print ("测试集一共有",number_2,"个product_category出现在训练集中")
print ("训练集一共有",number_3,"个product_category没出现在测试集中")
测试集一共有 18 个product_category,算上\N
训练集一共有 18 个product_category,算上\N
测试集一共有 0 个product_category没有出现在训练集中
测试集一共有 18 个product_category出现在训练集中
训练集一共有 0 个product_category没出现在测试集中
训练姐和测试集合的advertiser_id有没有不同的
import pandas as pd
ad_test = pd.read_csv('D:\\txcent\\test\\ad_test.csv')
list1=list(ad_test['advertiser_id'])
dict1=dict.fromkeys(list1)
ad = pd.read_csv('D:\\txcent\\ad.csv')
list2=list(ad['advertiser_id'])
dict2=dict.fromkeys(list2)
print ("测试集一共有",len(dict1),"个advertiser_id,算上\\N")
print ("训练集一共有",len(dict2),"个advertiser_id,算上\\N")
number_1=0
number_2=0
number_3=0
for i in dict1:
if(i not in dict2):
number_1=number_1+1
else:
number_2=number_2+1
for i in dict2:
if(i not in dict1):
number_3=number_3+1
print ("测试集一共有",number_1,"个advertiser_id没有出现在训练集中")
print ("测试集一共有",number_2,"个advertiser_id出现在训练集中")
print ("训练集一共有",number_3,"个advertiser_id没出现在测试集中")
测试集一共有 52861 个advertiser_id,算上\N
训练集一共有 52090 个advertiser_id,算上\N
测试集一共有 5780 个advertiser_id没有出现在训练集中
测试集一共有 47081 个advertiser_id出现在训练集中
训练集一共有 5009 个advertiser_id没出现在测试集中
训练姐和测试集合的creative_id有没有不同的
import pandas as pd
ad_test = pd.read_csv('D:\\txcent\\test\\ad_test.csv')
list1=list(ad_test['creative_id'])
dict1=dict.fromkeys(list1)
ad = pd.read_csv('D:\\txcent\\ad.csv')
list2=list(ad['creative_id'])
dict2=dict.fromkeys(list2)
print ("测试集一共有",len(dict1),"个creative_id,算上\\N")
print ("训练集一共有",len(dict2),"个creative_id,算上\\N")
number_1=0
number_2=0
number_3=0
for i in dict1:
if(i not in dict2):
number_1=number_1+1
else:
number_2=number_2+1
for i in dict2:
if(i not in dict1):
number_3=number_3+1
print ("测试集一共有",number_1,"个creative_id没有出现在训练集中")
print ("测试集一共有",number_2,"个creative_id出现在训练集中")
print ("训练集一共有",number_3,"个creative_id没出现在测试集中")
- 结果
测试集一共有 2618159 个creative_id,算上\N
训练集一共有 2481135 个creative_id,算上\N
测试集一共有 931637 个creative_id没有出现在训练集中
测试集一共有 1686522 个creative_id出现在训练集中
训练集一共有 794613 个creative_id没出现在测试集中
训练姐和测试集合的product_id有没有不同的
import pandas as pd
ad_test = pd.read_csv('D:\\txcent\\test\\ad_test.csv')
list1=list(ad_test['product_id'])
dict1=dict.fromkeys(list1)
ad = pd.read_csv('D:\\txcent\\ad.csv')
list2=list(ad['product_id'])
dict2=dict.fromkeys(list2)
print ("测试集一共有",len(dict1),"个product_id,算上\\N")
print ("训练集一共有",len(dict2),"个product_id,算上\\N")
number_1=0
number_2=0
number_3=0
for i in dict1:
if(i not in dict2):
number_1=number_1+1
else:
number_2=number_2+1
for i in dict2:
if(i not in dict1):
number_3=number_3+1
print ("测试集一共有",number_1,"个product_id没有出现在训练集中")
print ("测试集一共有",number_2,"个product_id出现在训练集中")
print ("训练集一共有",number_3,"个product_id没出现在测试集中")
测试集一共有 34111 个product_id,算上\N
训练集一共有 33273 个product_id,算上\N
测试集一共有 5784 个product_id没有出现在训练集中
测试集一共有 28327 个product_id出现在训练集中
训练集一共有 4946 个product_id没出现在测试集中
5784+4946+2*28327
67384
34111+33273
67384
训练姐和测试集合的user_id有没有相同的
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\test\\click_log_test.csv')
list1=list(click_log['user_id'])
dict1=dict.fromkeys(list1)
click_log = pd.read_csv('D:\\txcent\\user.csv')
for i in click_log['user_id']:
if(i not in dict1):
print ("测试集的user出现在训练集的user.csv啦!")
- 很遗憾,并没有啊
在腾讯云上根据click_log_test随机给一个user_id一个age和gender看看能得几分
import pandas as pd
import os
import argparse
import numpy as np
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--test_path', type=str, default = None)
args = parser.parse_args()
click_log = pd.read_csv(args.test_path+'/click_log.csv')
dic_age={}
dic_gender={}
for i in click_log['user_id']:
dic_age[i]=np.random.randint(1,high=11)
dic_gender[i]=np.random.randint(1,high=3)
a=list(dic_age.keys())
b=list(dic_age.values())
c=list(dic_gender.values())
result=np.array([a,b,c])
result=result.transpose()
result=pd.DataFrame(result,columns=['user_id','predicted_age','predicted_gender'])
result.to_csv('/cos_person/kobe_predict/submission.csv',index=None)
本地根据click_log_test随机给一个user_id一个age和gender看看能得几分
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\test\\click_log_test.csv')
dic_age={}
dic_gender={}
for i in click_log['user_id']:
dic_age[i]=np.random.randint(1,high=11)
dic_gender[i]=np.random.randint(1,high=3)
a=list(dic_age.keys())
b=list(dic_age.values())
c=list(dic_gender.values())
result=np.array([a,b,c])
result=result.transpose()
result=pd.DataFrame(result,columns=['user_id','predicted_age','predicted_gender'])
result.to_csv('D:\\txcent\\test\\submission.csv',index=None)
测试机概要
click_log,csv
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\test\\click_log_test.csv')
- 通过观察每一列的类型,发现都是int64
- 发现click_log_test没有缺失值
print (click_log['time'])
Name: time, Length: 33585512, dtype: int64
print (click_log['user_id'])
Name: user_id, Length: 33585512, dtype: int64
print (click_log['creative_id'])
Name: creative_id, Length: 33585512, dtype: int64
print (click_log['click_times'])
Name: click_times, Length: 33585512, dtype: int64
ad.csv
- product_id和industry的丢了
print (ad['creative_id'])
Name: creative_id, Length: 2618159, dtype: int64
print (ad.columns)
Index(['Unnamed: 0', 'creative_id', 'ad_id', 'product_id', 'product_category',
'advertiser_id', 'industry'],
dtype='object')
print (ad['ad_id'])
Name: ad_id, Length: 2618159, dtype: int64
print (ad['product_id'])
0 \N
Name: product_id, Length: 2618159, dtype: object
print (ad['advertiser_id'])
Name: advertiser_id, Length: 2618159, dtype: int64
print (ad['product_category'])
Name: product_category, Length: 2618159, dtype: int64
print (ad['industry'])
2618154 \N
Name: industry, Length: 2618159, dtype: object
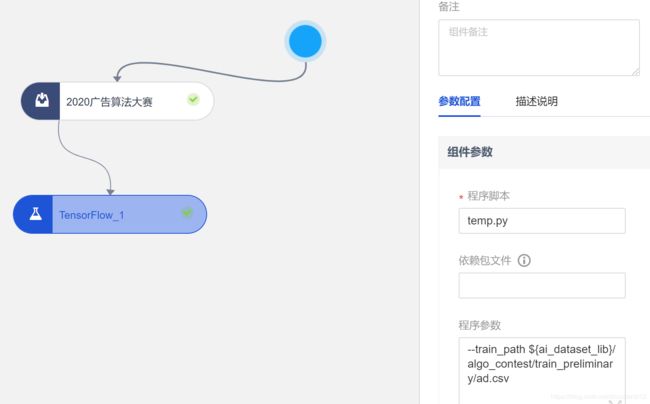
怎么读取训练集啊
import pandas as pd
import argparse
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--train_path', type=str, default = None)
args = parser.parse_args()
data = pd.read_csv(args.train_path)
#data.to_csv('/cos_person/kobe_predict/ad1.csv')
这样却失败了
import pandas as pd
import argparse
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--train_path', type=str, default = None)
args = parser.parse_args()
#ad = pd.read_csv(args.train_path+'/ad.csv')
click_log = pd.read_csv(args.train_path+'/click_log.csv')
#user = pd.read_csv(args.train_path+'/user.csv')
#ad.to_csv('/cos_person/kobe_predict/ad.csv')
#click_log.to_csv('/cos_person/kobe_predict/click_log.csv')
#user.to_csv('/cos_person/kobe_predict/user.csv')
- 如果你想把click_log这个文件下载到cos存储桶,那你就失败了
- 难道太大了??
- 没错,我把那个资源牛逼了一下就好了
获得三个文件大小
import pandas as pd
import os
import argparse
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--train_path', type=str, default = None)
args = parser.parse_args()
#ad = pd.read_csv(args.train_path+'/ad.csv')
#click_log = pd.read_csv(args.train_path+'/click_log.csv')
#user = pd.read_csv(args.train_path+'/user.csv')
fsize = os.path.getsize(args.train_path+'/click_log.csv')
f=open('/cos_person/kobe_predict/ad.txt','a')
f.write(str(fsize))
f.close()
# print (len(click_log))
# print (len(user))
#ad.to_csv('/cos_person/kobe_predict/ad.csv')
# click_log.to_csv('/cos_person/kobe_predict/click_log.csv')
#user.to_csv('/cos_person/kobe_predict/user.csv')
三个文件啥样子

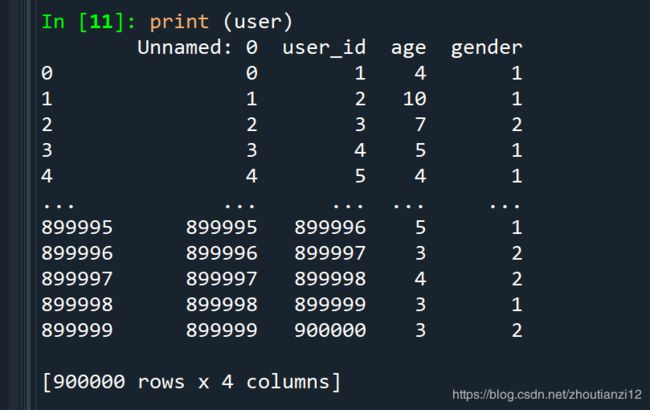
print (ad.columns)
Index(['Unnamed: 0', 'creative_id', 'ad_id', 'product_id', 'product_category',
'advertiser_id', 'industry'],
dtype='object')
- product_id和industry的丢了
print (ad['creative_id'])
Name: creative_id, Length: 2481135, dtype: int64
print (ad['ad_id'])
Name: ad_id, Length: 2481135, dtype: int64
print (ad['product_id'])
0 \N
Name: product_id, Length: 2481135, dtype: object
print (ad['product_category'])
0 5
Name: product_category, Length: 2481135, dtype: int64
print (ad['advertiser_id'])
0 381
Name: advertiser_id, Length: 2481135, dtype: int64
print (ad['industry'])
2481131 \N
2481132 \N
2481133 \N
2481134 \N
Name: industry, Length: 2481135, dtype: object

分析三文件的内容
click_log.csv的内容
- 没异常
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\click_log.csv')
print (click_log['time'])
Name: time, Length: 30082771, dtype: int64
print (click_log['user_id'])
Name: user_id, Length: 30082771, dtype: int64
print (click_log['creative_id'])
Name: creative_id, Length: 30082771, dtype: int64
print (click_log['click_times'])
Name: click_times, Length: 30082771, dtype: int64
- 查看click_times的分布
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\click_log.csv')
dic_click_times={}
for i in click_log['click_times']:
dic_click_times[i]=dic_click_times.get(i,0)+1
print (dic_click_times)
keys=dic_click_times.keys()
keys=list(keys)
keys.sort()
# 对keys排好序了
values=dic_click_times.values()
plt.bar( [i for i in keys],[dic_click_times[i] for i in keys],color='red')
plt.xticks([i for i in keys])
plt.xlabel('click_times')
plt.ylabel('frequency')
plt.title('click_times')

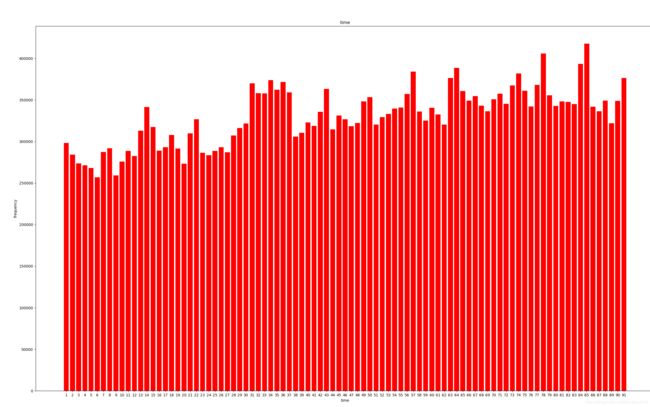
- 查看time的分布
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\click_log.csv')
dic_time={}
for i in click_log['time']:
dic_time[i]=dic_time.get(i,0)+1
print (dic_time)
keys=dic_time.keys()
#keys=list(keys)
#keys.sort()
# 对keys排好序了
values=dic_time.values()
plt.bar( [i for i in keys],[dic_time[i] for i in keys],color='red')
plt.xticks([i for i in keys])
plt.xlabel('time')
plt.ylabel('frequency')
plt.title('time')
- 查看user_id,看看每个人出现的次数的分布
# -*- coding: utf-8 -*-
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
click_log = pd.read_csv('D:\\txcent\\click_log.csv')
dic_user_id={}
for i in click_log['user_id']:
dic_user_id[i]=dic_user_id.get(i,0)+1
print (dic_user_id)
dic_user={}
for i in dic_user_id.values():
dic_user[i]=dic_user.get(i,0)+1
keys=dic_user.keys()
keys=list(keys)
keys.sort()
# 对keys排好序了
values=dic_user.values()
plt.bar( [i for i in keys],[dic_user[i] for i in keys],color='red')
plt.xticks([i for i in keys])
plt.xlabel('user_number')
plt.ylabel('frequency')
plt.title('user_number')

user.csv的内容
- 没有异常值
# -*- coding: utf-8 -*-
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad = pd.read_csv('D:\\txcent\\ad.csv')
click_log = pd.read_csv('D:\\txcent\\click_log.csv')
user = pd.read_csv('D:\\txcent\\user.csv')
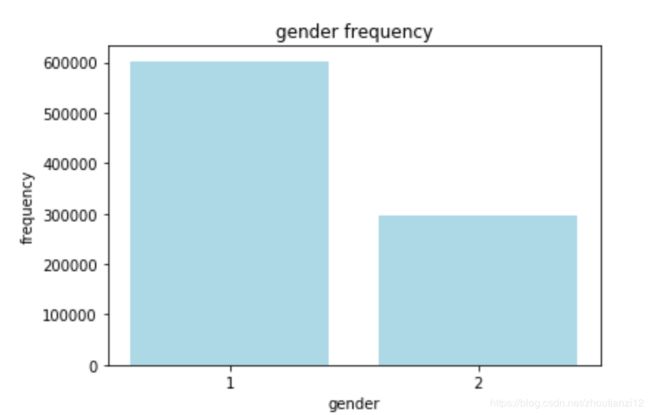
- 性别分析
dic_gender={}
for i in user['gender']:
dic_gender[i]=dic_gender.get(i,0)+1
print (dic_gender)
plt.bar((1,2),[dic_gender[i] for i in range(1,3)],color='lightblue')
plt.xticks((1,2),dic_gender.keys())
plt.xlabel('gender')
plt.ylabel('frequency')
plt.title('gender frequency')
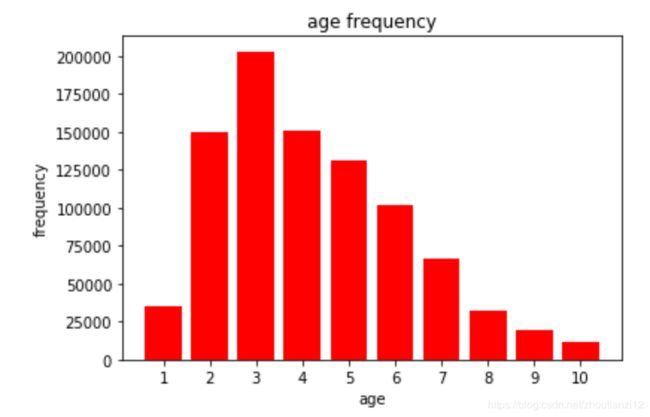
- 看看age的分布
dic_age={}
for i in user['age']:
dic_age[i]=dic_age.get(i,0)+1
print (dic_age)
plt.bar(range(1,11),[dic_age[i] for i in range(1,11)],color='red')
plt.xticks(range(1,11))
plt.xlabel('age')
plt.ylabel('frequency')
plt.title('age frequency')
ad.csv的东西
ad_id唯一吗?
- 训练集
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\ad.csv')
dict1={}
for i in ad['ad_id']:
dict1[i]=dict1.get(i,0)+1
print (len(dict1))
print (len(ad['ad_id']))
runfile(‘D:/txcent/untitled0.py’, wdir=‘D:/txcent’)
2264190
2481135
- 测试集
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\test\\ad_test.csv')
dict1={}
for i in ad['ad_id']:
dict1[i]=dict1.get(i,0)+1
print (len(dict1))
print (len(ad['ad_id']))
runfile(‘D:/txcent/untitled0.py’, wdir=‘D:/txcent’)
2379475
2618159
advertiser_id唯一码?
- 训练集
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\ad.csv')
dict1={}
for i in ad['advertiser_id']:
dict1[i]=dict1.get(i,0)+1
print (len(dict1))
print (len(ad['advertiser_id']))
runfile(‘D:/txcent/untitled0.py’, wdir=‘D:/txcent’)
52090
2481135
- 测试集
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\test\\ad_test.csv')
dict1={}
for i in ad['advertiser_id']:
dict1[i]=dict1.get(i,0)+1
print (len(dict1))
print (len(ad['advertiser_id']))
runfile(‘D:/txcent/untitled0.py’, wdir=‘D:/txcent’)
52861
2618159
creative_id是唯一的吗?
-
唯一的!!
-
训练集
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\ad.csv')
dict1={}
for i in ad['creative_id']:
dict1[i]=dict1.get(i,0)+1
print (len(dict1))
print (len(ad['creative_id']))
runfile(‘D:/txcent/untitled0.py’, wdir=‘D:/txcent’)
2481135
2481135
- 测试集
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\test\\ad_test.csv')
dict1={}
for i in ad['creative_id']:
dict1[i]=dict1.get(i,0)+1
print (len(dict1))
print (len(ad['creative_id']))
runfile(‘D:/txcent/untitled0.py’, wdir=‘D:/txcent’)
2618159
2618159
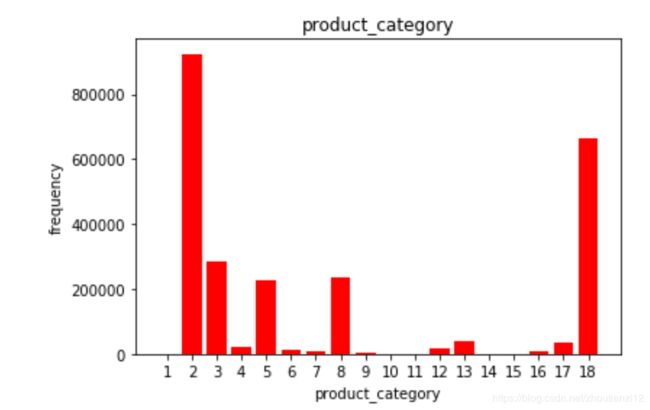
没有清理前,我看看category的构成
dic_product_category={}
for i in ad['product_category']:
dic_product_category[i]=dic_product_category.get(i,0)+1
print (dic_product_category)
keys=dic_product_category.keys()
values=dic_product_category.values()
plt.bar(range(1,len(keys)+1),[dic_product_category[i] for i in range(1,len(keys)+1)],color='red')
plt.xticks(range(1,len(keys)+1))
plt.xlabel('product_category')
plt.ylabel('frequency')
plt.title('product_category')
-
上面的是训练集的
-
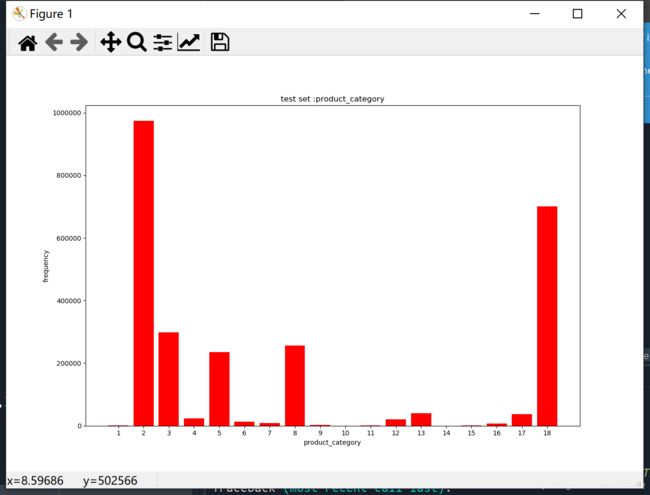
那测试集合的product_category呢?
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
ad= pd.read_csv('D:\\txcent\\test\\ad_test.csv')
dic_product_category={}
for i in ad['product_category']:
dic_product_category[i]=dic_product_category.get(i,0)+1
print (dic_product_category)
keys=dic_product_category.keys()
values=dic_product_category.values()
plt.bar(range(1,len(keys)+1),[dic_product_category[i] for i in range(1,len(keys)+1)],color='red')
plt.xticks(range(1,len(keys)+1))
plt.xlabel('product_category')
plt.ylabel('frequency')
plt.title('test set :product_category')
对ad.csv清理\N
- 首先将所有\N的行删除
clean_index=ad[(ad=='\\N').any(1)].index
ad.drop(clean_index,axis=0,inplace=True)
ad['product_id']=ad['product_id'].astype('int64')
ad['industry']=ad['industry'].astype('int64')
print (ad['creative_id'])
print (ad['ad_id'])
print (ad['product_id'])
print (ad['product_category'])
print (ad['advertiser_id'])
print (ad['industry'])
print (ad)
ad.to_csv('D:\\txcent\\ad_cleaning.csv')
- 并且写入到了ad_cleaning.csv了
训练集和测试集
${ai_dataset_lib}/algo_contest/train_preliminary/ad.csv
${ai_dataset_lib}/algo_contest/train_preliminary/click_log.csv
${ai_dataset_lib}/algo_contest/train_preliminary/user.csv

${ai_dataset_lib}/algo_contest/test/ad.csv
${ai_dataset_lib}/algo_contest/test/click_log.csv
怎么获取测试机啊?
- 获取测试集的代码
import pandas as pd
import os
import argparse
parser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument('--test_path', type=str, default = None)
args = parser.parse_args()
ad = pd.read_csv(args.test_path+'/ad.csv')
click_log = pd.read_csv(args.test_path+'/click_log.csv')
#user = pd.read_csv(args.train_path+'/user.csv')
#fsize = os.path.getsize(args.test_path+'/ad.csv')
#f=open('/cos_person/kobe_predict/ad.txt','w')
#f.write(str(fsize))
#f.close()
ad.to_csv('/cos_person/kobe_predict/ad_test.csv')
click_log.to_csv('/cos_person/kobe_predict/click_log_test.csv')
#user.to_csv('/cos_person/kobe_predict/user.csv')