利用selenium 实现对百度图片搜索中的图片的抓取
1. 前言
我们一直非常希望可以抓取百度图片上的图片, 自打我们接触了 python的urllib 库之后, 我们就非常想爬些图片下来, 尤其是从百度图片上面, 在很久之前, 百度图片上的图片是不加密的, 分析他的静态网页源码可以直接提取得到图片的源地址信息 放在 obj_url 中, 当时, 我们还利用这点, 爬取过一些图片下来, 可以参考 http://blog.csdn.net/lerdor/article/details/12047447
然而, 好景不长, 百度把 这个信息给加密了, 于是这个爬取方法自然就失效了。。。。。
2. 基本思路
2.1 项目分析
- 不过最近接触到了一个 selenium 的软件, 这个软件主要是做自动化测试用的, 他可以模拟浏览器行为,于是, 我们看到了希望。
- 我们分析image.baidu.com

于是, 我们知道, 我们可以在 name 为 “word” 的input 框中输入 需要的关键字, 然后提交, 即可获取我们需要的图片页面 - 分析相应的图片搜索页面
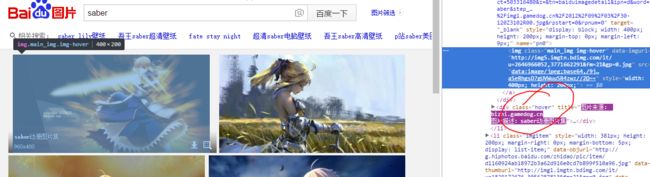
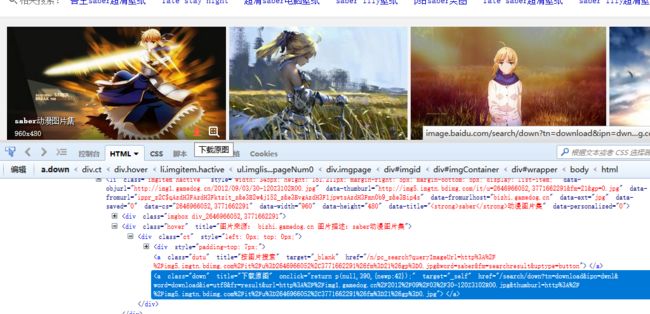
我们知道, 当我们的鼠标从图片元素上移动过的时候, 会出现一个 hover 元素, 在这个元素中 有个下载按钮, 可以看到这个 down 标签中存放了原始图片的下载地址信息,得到这个信息之后, 我们就可以很容以的实现下载了
2.2 基本解决方案
- 于是很显然, 方案就出来了, 我们利用selenium 模拟鼠标按键, 获取hover 浮动标签, 然后, 点击下载, 由此实现图片下载
- 由于,baidu图片的页面是动态加载的, 一次只加载了一页, 如果我们直接抓取的话, 只能抓到一页的图片, 抓不到更多了, 其实这个也是很简单的, 我们可以模拟键盘 的page_down, 实现翻页, 自动触发baidu 图片的加载功能, 但是, 这样做可能会有重复图片出现, 我们可以使用类似 hash_set 的结构, 记录已经处理过的图片元素
- 网上有大神给出, 模拟鼠标右键, 另存为的方法, 具体可以参考: http://blog.csdn.net/seanwang_25/article/details/43318907 。不过这个方法有一定的局限性
- 首先, 另存为, 每次都会有弹窗, 很讨厌
- 其次, 另存为的图片不是原始图片的尺寸
3. 遇到的一些问题
staleElementReferenceException

这个问题, 其实我们没有解决, 直觉上这个和延时有关, 于是, 我们在代码中加了两段延时 sleep(20), 和 thread._sleep(1), 同时将可能出现异常的代码用 try 包裹起来, 避免程序直接崩溃图片下载重复问题
上面提到了, 可以使用类似 hash 表的思想进行处理mkdir 不能创建多级目录, 可以使用 makedirs : http://www.2cto.com/kf/201207/144150.html
4. 实现效果
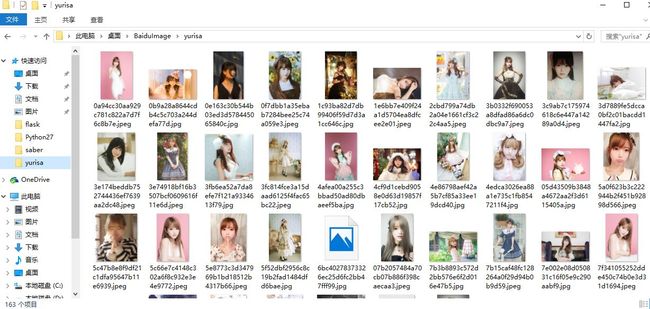
把我们家女神拿来镇楼, 哈哈~~
5. 程序的一些缺陷
- 需要借助firefox 浏览器, 启动比较慢,抓取的效率比较低
- 因为这是模拟鼠标的点击事件, 有时候, 可能需要手工协助一下,移动下鼠标至相应的下载浮动图标上( 否则一直抽风, 就是不存图)
- 刚开始的时候, 由于下载弹框会对我们的浮动窗口有一定干扰, 如果不手工处理掉, 可能无法继续下载

就是那个下载的下拉弹窗, 很讨厌, 手工关闭即可, 后续不会再出现了
6. 实现代码
# -*- coding:utf8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import threading
import time
import os
class BaiduSpider():
'''
爬取百度图片中的图片
'''
def __init__(self, search_keys):
self.search_keys = search_keys
self.url = 'http://image.baidu.com'
self.page_total = 6
# self.url = "http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=saber"
# set profile
fp = webdriver.FirefoxProfile()
fp.set_preference('browser.download.folderList', 2)
fp.set_preference('browser.download.manager.showWhenStarting', False)
downDir = 'C:\\Users\\ThinkPad User\\Desktop\\BaiduImage\\' + self.search_keys
fp.set_preference('browser.download.dir', downDir)
fp.set_preference('browser.helperApps.neverAsk.saveToDisk', 'image/jpeg')
# fp.set_preference('browser.helperApps.neverAsk.saveToDisk', ['image/jpeg', 'image/png', 'image/gif'])
self.fp = fp
if not os.path.exists(downDir):
os.makedirs(downDir)
def Search(self):
# 打开浏览器 , 并在百度图片搜索中输入关键字
driver = webdriver.Firefox(firefox_profile=self.fp)
driver.maximize_window()
driver.get(self.url)
# print driver.title
inputElement = driver.find_element_by_name('word')
inputElement.send_keys(self.search_keys)
inputElement.submit()
time.sleep(20)
return driver
def download(self):
driver = self.Search()
#获取 n pagedown 个页面的内容
# for i in range(5):
# action = ActionChains(self.driver).send_keys(Keys.PAGE_DOWN)
# action.perform()
page_total = self.page_total
page_i = 0
total_elements = 0
remained_pics = [] # 标记已经处理过的图片元素
while page_i < page_total:
elements_all = driver.find_elements_by_xpath('//ul/li/div/a/img') # 一定是单引号
elements = elements_all
# print elements
i = 0
while i < (len(elements)):
print i
try:
element = elements[i]
# 去除重复图片
if element in remained_pics:
i += 1
continue
print "pic element : ", element
# 激活 hover
action = ActionChains(driver).move_to_element(element)
action.perform()
# 查找 a.down
hover = driver.find_element_by_class_name("down")
print "hover element: ", hover
action = ActionChains(driver).move_to_element(hover)
action.click() # 点击下载
action.perform()
i = i + 1
except:
threading._sleep(1)
page_i += 1
remained_pics.extend(elements)
action = ActionChains(driver).send_keys(Keys.DOWN)
action.perform()
if __name__ == "__main__":
# spider = BaiduSpider("saber")
spider = BaiduSpider("yurisa")
spider.download()