【线上问题】一次长事务导致数据库锁等待超时问题跟踪
1.一次线上日志巡检发现下面的日志,最近15天出现了4000多次
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException:
Lock wait timeout exceeded; try restarting transaction
2.通过日志堆栈定位到具体的业务代码,发现业务代码中更新数据库的SQL都类似这种,where条件后面都带有字段seq_no,且该字段上有唯一索引
update sms_batch set status = ?1, send_time = ?4 where seq_no = ?3 and status = ?23.仔细走查代码,发现代码中所有更新事务都是自动提交,且确认:不存在长事务和死锁
4.查询了一下DB,查看当前数据库设置的行锁超时时间 为5秒,查询语句
show GLOBAL VARIABLES like '%innodb_lock_wait_timeout%';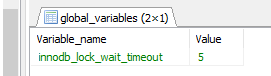
5.于是我有点怀疑是不是并发高了,再次走查代码,发现代码中极端情况,同一个seq_no做条件更新才12个并发,非常低
6.我还有点不信邪,我在测试环境,把数据库的锁超时时间设置成同样的5秒,100个线程并发更新,没有复现 锁等待超时。
修改锁等待超时脚本
set GLOBAL innodb_lock_wait_timeout=5;
7.在查数据库的时候,我们发现处理的批量任务的个数有1700个,正常情况一天才几十个,再次翻开代码,发现我们处理批量任务是通过线程池执行的,1700个任务不会造成并发很高;
8.当发现批量任务的数量异常增大后,紧接着又发现了另外一个问题,这1700个批量任务的批量文件为空,且部分任务一直不能走到终态,(不能走到终态就是相当于几天前发的批量任务每天都打捞执行,但是每次都执行失败,但是任务状态还是待执行)
于是又一头扎进这个问题的排查中
9.把代码又翻了个底朝天,终于发现了一个坑:批量任务执行之前会先通过乐观锁更新批量任务状态为解析中,然后往Redis中记录当前批量任务的开始解析时间,业务上期望的是更新任务状态和往Redis写任务开始时间是在一个事务中执行,但是实际代码中未能保证两个操作在一个事务中执行,所以解析中的任务一直在执行不能终止。往Redis写任务开始时间这个失败就是因为在它之前写了一次数据库,且因为锁等待超时了。感觉问题还是没找到,什么导致锁等待超时呢?
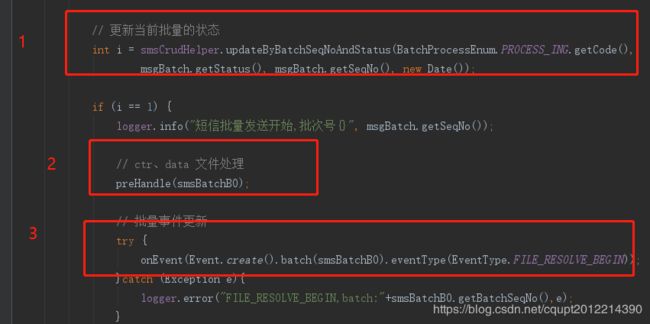 如图:期望的是1、3在一个事务中执行,但是2因为锁等待超时失败了,导致1没有回滚
如图:期望的是1、3在一个事务中执行,但是2因为锁等待超时失败了,导致1没有回滚
10.废了半天劲还是没找到根本问题,于是准备找DBA抓一些数据库执行的情况看看,于是联系上了DBA 小哥哥
DBA小哥哥很热情,很快甩了我下面三个抓取的数据图: 图数据库-1、图数据库-2、图数据库-3;
图数据库-1中的事务开启后长期执行,未提交,导致图数据库-2、图数据库-3中的事务锁等待超时,且肯定是大于数据据设置的锁等待超时时间5秒。比较坑的是图数据库-1中不能看到执行的SQL,那我看到等待锁超时的SQL也没意义,好像问题还是没找到,为什么事务长期不提交,且是周期性的长期未提交(并没有死锁,只是事务执行的时间比较长),我有点抓狂了。
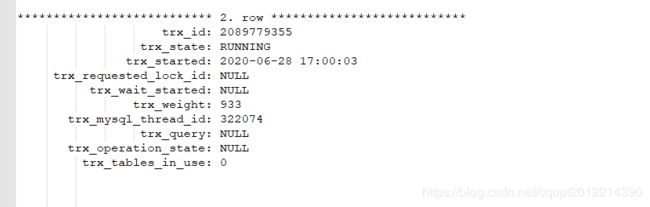 数据库-1
数据库-1
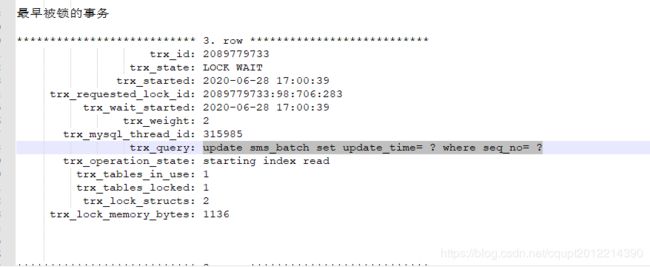 数据库-2
数据库-2
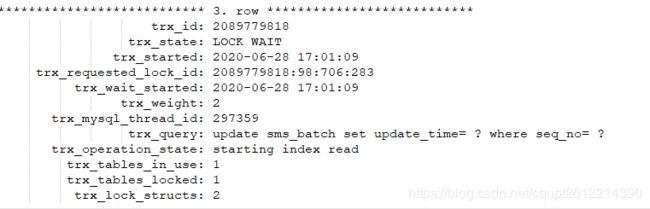 数据库-3
数据库-3
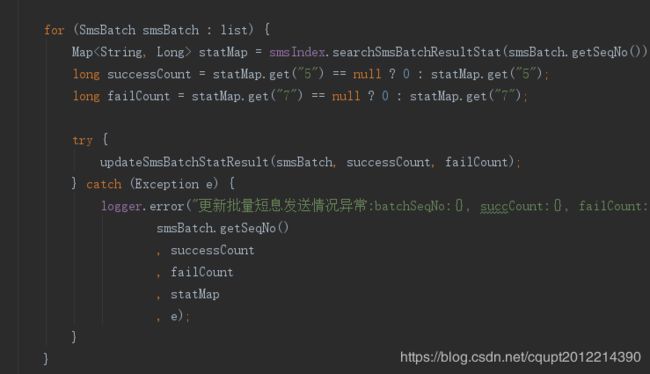
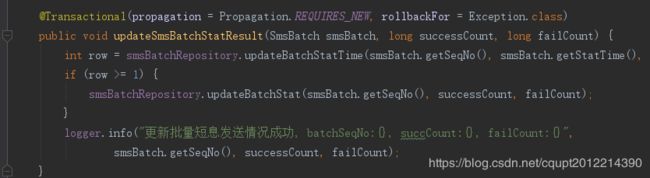
11.我只能静下心来好好回顾一下任务的所有情况,我隐隐的猜到那个地方还有隐藏的代码在更新表数据,且是开启了长事务。我拿到表名在Idea中搜索,果真发现另外一个项目XX(不是当前出事的业务模块OO),中有一个定时的统计任务在更新表数据。感觉高潮来了,问题有可能就是这里,上代码。截图中1和2都开启了Spring的注解事务,且默认都是 Propagation.REQUIRED传播属性,也就是说当前统计方法会等for循环的所有批量统计完成后再提交,每个一层循环中都会查ES统计数据(统计有点耗时,但是当几十次循环还不会出现问题),问题是批量任务被上游一天怼了1700个,这个循环就导致事务执行时间很长了,然后导致其它地方更新这个批量的地方都锁等待超时,我了个去,太坑了,害我转了一大圈
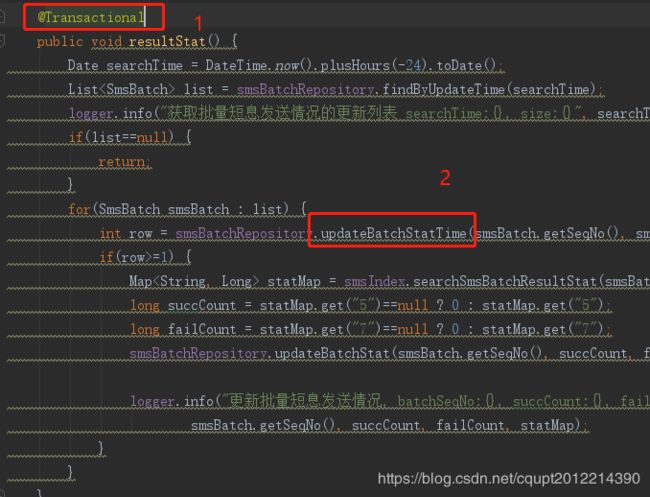
总结:
问题定位到了,但是为啥饶了这么多圈圈?我反省有以下内容:
排查问题流程:
- 当看到锁等待超时的时候我首先走查代码,思路没错,但是走查不仔细,漏掉了隐藏更新表的逻辑
- 于是我自己怀疑是并发高,且做了一顿测试环境验证,测试环境验证否定了之前的猜想
- 被附带问题干扰,在排查批量任务不能走到终态的地方花了不少时间,问题是找到了,但是这个问题也是因为锁等待超时导致的批量任务不能走到终态,根本原因没找到。
- 这里其实还穿插一个点,业务系统为什么给大量的空文件给我们,我把这个问题的一些数据和情况组织成了一个邮件发到业务系统那边,让他们排查问题也花了不少时间
- 中间还找了DBA抓数据库执行数据,遗憾的是发现了受影响的SQL,但是是不能看到长期未提交的那个事务对应的SQl。DBA提供的数据没能直接定位到问题,但是让我非常肯定有个地方在更新表数据且长期未提交事务
- 于是我静下心来再好好搜索以下代码,一下就找到了问题
反思:
- 如果我第一步就走查代码仔细点可能问题就找到了
- A模块和B块都公用一个数据库更新模型,都在更新m表,我当时一直A中找问题,没想到B中也可能有问题
- 如果中途不被牵扯出来的问题干扰就更好了
FixBug
第11点中优化为如下,更新任务状态和往Redis写数据在一个事务中完成
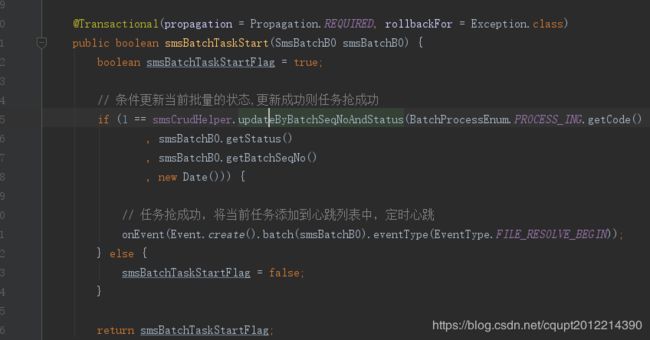
For循环中更新数据库,每次更新单独开启一个事务
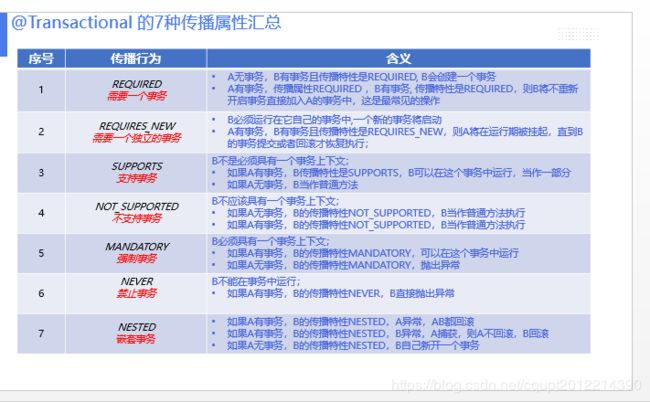
事务的传播属性知识回忆一下,我之前写的PPT中截图,一般我们遇到最多的就第一个和第二个传播属性