DBC转Excel;DBC转位定义;Excel转DBC;Excel转位定义;MatrixCreat(一)之CAN矩阵详解
CAN矩阵详解
- 一、摘要
- 1.描述
- 2.关键字
- 二、什么是CAN
- 1.报文格式
- 2.数据帧格式
- 3.数据错误检测
- 三、CAN矩阵
- 1.矩阵表
- 2.报文名称
- 3.报文类型
- 4.报文标识符
- 5.报文发送类型
- 6.报文周期时间
- 7.报文发送的快速周期
- 8.报文快速发送的次数
- 9.报文延时时间
- 10.报文长度
- 11.信号名称
- 12.信号描述
- 13.排列格式
- 14.起始字节
- 15.起始位
- 16.信号发送类型
- 17.信号长度
- 18.数据类型
- 19.精度
- 20.偏移量
- 21.物理最小值
- 22.物理最大值
- 23.总线最小值
- 24.总线最大值
- 25.初始值
- 26.无效值
- 27.非使能值
- 28.单位
- 29.信号值描述
- 30.备注
- 31.发送节点
- 32.接收节点
- 四、CAN解析方式
- 五、MatrixCreat工具
- 六、其他
- 七、参考
一、摘要
1.描述
本文主要描述的是汽车行业中CAN矩阵的内容,主要描述我们当拿到一份矩阵表的时候如何去看懂内容。
2.关键字
CAN,CAN矩阵,矩阵详解,通信协议,汽车总线。
二、什么是CAN
CAN 是Controller Area Network 的缩写(以下称为CAN),是ISO国际标准化的串行通信协议。在汽车产业中,出于对安全性、舒适性、方便性、低功耗、低成本的要求,各种各样的电子控制系统被开发了出来。
CAN总线是德国BOSCH公司从80年代初为解决现代汽车中众多的控制与测试仪器之间的数据交换而开发的一种串行数据通信协议,它是一种多主总线,通信介质可以是双绞线、同轴电缆或光导纤维。通信速率最高可达1Mbps,我们这儿主要讲的是低速CAN,非CANFD。
1.报文格式
在总线中传送的报文,每帧由7部分组成。CAN协议支持两种报文格式,其唯一的不同是标识符(ID)长度不同,标准格式为11位,扩展格式为29位。
在标准格式中,报文的起始位称为帧起始(SOF),然后是由11位标识符和远程发送请求位 (RTR)组成的仲裁场。RTR位标明是数据帧还是请求帧,在请求帧中没有数据字节。
控制场包括标识符扩展位(IDE),指出是标准格式还是扩展格式。它还包括一个保留位 (ro),为将来扩展使用。它的最后四个位用来指明数据场中数据的长度(DLC)。数据场范围为0~8个字节,其后有一个检测数据错误的循环冗余检查(CRC)。
应答场(ACK)包括应答位和应答分隔符。发送站发送的这两位均为隐性电平(逻辑1),这时正确接收报文的接收站发送主控电平(逻辑0)覆盖它。用这种方法,发送站可以保证网络中至少有一个站能正确接收到报文。
报文的尾部由帧结束标出。在相邻的两条报文间有一很短的间隔位,如果这时没有站进行总线存取,总线将处于空闲状态。
2.数据帧格式
远程帧:
远程帧由6个场组成:帧起始、仲裁场、控制场、CRC场、应答场和帧结束。远程帧不存在数据场。
远程帧的RTR位必须是隐位。
DLC的数据值是独立的,它可以是0~8中的任何数值,为对应数据帧的数据长度。
错误帧:
错误帧由两个不同场组成,第一个场由来自各站的错误标志叠加得到,第二个场是错误界定符
错误标志具有两种形式:
活动错误标志(Active error flag),由6个连续的显位组成
认可错误标志(Passive error flag),由6个连续的隐位组成
错误界定符包括8个隐位
超载帧:
超载帧包括两个位场:超载标志和超载界定符
发送超载帧的超载条件:
要求延迟下一个数据帧或远程帧
在间歇场检测到显位
超载标志由6个显位组成
超载界定符由8个隐位组成
3.数据错误检测
循环冗余检查(CRC):
在一帧报文中加入冗余检查位可保证报文正确。接收站通过CRC可判断报文是否有错。
帧检查:
这种方法通过位场检查帧的格式和大小来确定报文的正确性,用于检查格式上的错误。
应答错误:
如前所述,被接收到的帧由接收站通过明确的应答来确认。如果发送站未收到应答,那么表明接收站发现帧中有错误,也就是说,ACK场已损坏或网络中的报文无站接收。CAN协议也可通过位检查的方法探测错误。
总线检测:
有时,CAN中的一个节点可监测自己发出的信号。因此,发送报文的站可以观测总线电平并探测发送位和接收位的差异。
位填充:
一帧报文中的每一位都由不归零码表示,可保证位编码的最大效率。然而,如果在一帧报文中有太多相同电平的位,就有可能失去同步。为保证同步,同步沿用位填充产生。在五个连续相等位后,发送站自动插入一个与之互补的补码位;接收时,这个填充位被自动丢掉。例如,五个连续的低电平位后,CAN自动插入一个高电平位。CAN通过这种编码规则检查错误,如果在一帧报文中有6个相同位,CAN就知道发生了错误。
三、CAN矩阵
在汽车行业开发的过程中,凡是挂在CAN总线上的产品,客户都会给一份CAN矩阵表,如何去读懂CAN矩阵表显得尤为重要,前面我们讲了CAN的基本概念,相信大家对CAN有一个初步的了解,下面我以某个车厂的CAN矩阵表为例来说明。
1.矩阵表

2.报文名称
Msg_Name主要是通过名称就能区分我们平时描述的是哪条报文,这个名称一般是唯一的,就像人的名称一样,一般客户也不是随便定义该名称,当然这个名称也可以随意定,一般定义的格式就是该报文发送的节点加上报文的标识符。
例如.BCM_ALS_0x2F3 代表BCM_ALS为节点BCM转发ALS发送的报文,报文标识符为0x2F3。
3.报文类型
Msg_Type主要描述的是报文类型,在汽车行业中,报文主要类型有应用报文,网络管理报文,诊断报文。
应用报文 Normal: Normal Communication message;
网络管理报文 NM:Network Mangment message;
诊断报文 Diag: Diagnostic message。
4.报文标识符
Msg_ID是Message identifier的缩写,在矩阵表中,一般同一个报文标识符的内容放在一起,方便他人阅读,这个标识符是我们CAN总线上的唯一标识符,不可与其他信号重复,在矩阵表中,一般加上0x开头,代表16进制显示,在前面已经提到过在标准帧CAN的标识符大小为11位,所以一般大小为0x00 - 0x7FF;扩展帧我们这儿不做描述,因为一般车厂使用的都是标准帧,很少采用扩展帧。
5.报文发送类型
Msg_Send_Type表示的是报文发送的类型,在汽车行业中,报文发送的类型一般主要有事件型,周期型,周期事件型,使能型,周期使能型等,其他的类型我在这儿不做描述。
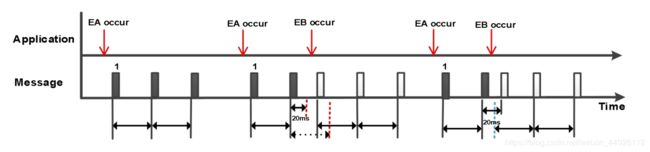
- 事件型(Event)
事件报文的发送取决于事件是否触发,事件发生改变时,按照矩阵发送事件报文,非触发事件发生改变时不允许触发发送事件报文,事件型报文一般车厂都会要求一个事件触发的时候发送多次,为了避免报文丢失,每帧之间也会限定一个帧与帧之间的最小间隔。下图为最小间隔20ms,当在事件报文发送 20ms 之后有新的事件发生,则发送新的事件报文,丢弃上一个事件报文;当在事件报文发送 20ms 之内有新事件发生,则新事件报文延迟到 20ms 之后发送。
- 周期型(Cycle)
报文以一定的间隔时间循环发送,报文的发送周期在矩阵表都会有体现,开发的时候必须按照客户规定的周期进行开发,一般时间两帧之间的误差不能超过规定时间的百分之十。
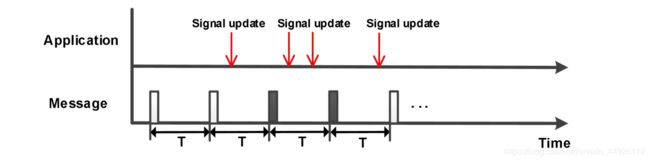
- 周期事件型(CE)
CE意思是 Cycle and Event,当事件未发生时,报文以周期时间 T循环发送,事件发生时,报文以快周期发送规定次数,周期事件型报文是一条比较特殊的报文,一般对实时性要求比较高,但是为了减少总线的负载,采用此方式。假设某车厂要求快周期为20ms,事件报文与周期报文发送的时间间隔不应小于 20ms。如果事件发生在周期报文发送之后 20ms 内,则事件报文延迟到周期报文发送 20ms 后再发送。如果事件报文发生在周期报文发送之前 20ms 内,则周期报文延迟到事件报文发送 20ms 后再发送;如果事件报文和周期报文发生冲突时,周期报文应延时到事件报文发送完成后 20ms 再发送。

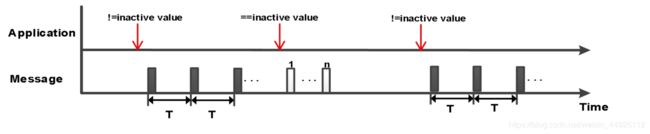
- 使能型(IfActive)
和事件型发送类型一样,使能发送类型由报文中的一个或多个信号触发,引起报文传输。当触发信号的“当前信号值≠非使能值时”,约束条件满足,触发条件发生,使能报文立刻以周期时间 T 循环发送。当信号值由使能值变为非使能值时并且再无其它使能信号,相应报文发送 规定次数。
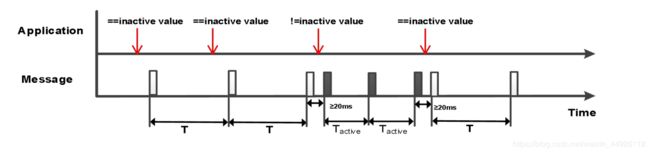
- 周期使能型(CA)
CA意思是Cycle if Active,当触发信号的“当前信号值=非使能值时”,报文以周期时间 T 循环发送,当触发信号的“当前信号值≠非使能值时”,约束条件发生,触发条件满足时,使能报文以周期发送直到“当前信号值=非使能值时”。
6.报文周期时间
Msg_Cycle_Time主要是针对周期型报,周期事件型报文和周期使能型,要注意这个周期世间的单位,一般默认为ms。
7.报文发送的快速周期
Msg_Cycle_Time_Fast指当报文发送类型不为周期型时,报文发送的快速周期。
8.报文快速发送的次数
Msg_Nr_Of_Reption指当报文发送类型不为周期型时,报文快速发送的次数。
9.报文延时时间
Msg_Delay_Time指当报文发送类型不为周期型时,相同ID报文之间的最小间隔。
10.报文长度
Msg_Length是指报文的长度,有的时候客户用lenth表示,有的时候用dlc表示,对于标准帧的传输,这个值最大为8,也就是一帧传输的有效字节数最多为8个有效数据位。
11.信号名称
Signal_Name是指定义在数据位信号名称,这个标识符和报文标识符是差不多的,也是唯一的,一般信号名称都是英文的,这个是为了通过这个标识符来生成信号,可用于位定义,DBC文件名称。
12.信号描述
Signal_Description指该信号的用途,代表的意思,一般是对该信号的描述。
13.排列格式
Byte_Order在汽车行业中有三种格式,分别是Intel,Motorola LSB,Motorola MSB。而有的时候车厂指写了Motorola,这个一般是指Motorola LSB。
- 数据类型定义
在汽车行业中,CAN传输的8个字节按照位定义了信号名称,定义名称如下图所示:

- Intel格式
当一个信号的数据长度不超过1 Byte,并且信号在一个字节内实现时,该信号的高位将被放在该字节的高位,信号的低位将被放在该字节的低位,当一个信号的数据长度超过1 Byte或者数据长度不超过1 Byte,但是采用跨字节的方式实现时,该信号的高位将被放在高字节的高位,信号的低位将被放在低字节的低位,这样信号的起始位就是低字节的低位。
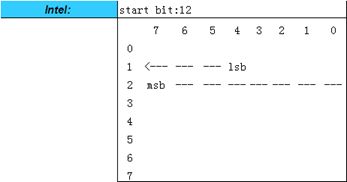
- Motorola LSB格式
当一个信号的数据长度不超过1 Byte并且信号在一个字节内实现时,信号的高位将被放在该字节的高位,信号的低位将被放在该字节的低位,这样,信号的起始位就是该字节的低位,当一个信号的数据长度超过1 Byte或者数据长度不超过一个字节但是采用跨字节方式实现时,该信号的高位将被放在低字节的高位,信号的低位将被放在高字节的低位,这样信号的起始位就是高字节的低位。
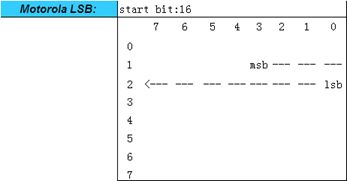
- Motorola MSB格式
当一个信号的数据长度不超过1 Byte并且信号在一个字节内实现时,信号的高位将被放在该字节的高位,信号的低位将被放在该字节的低位,这样,信号的起始位就是该字节的高位,当一个信号的数据长度超过1 Byte或者数据长度不超过一个字节但是采用跨字节方式实现时,该信号的高位将被放在低字节的高位,信号的低位将被放在高字节的低位,这样信号的起始位就是低字节的高位。
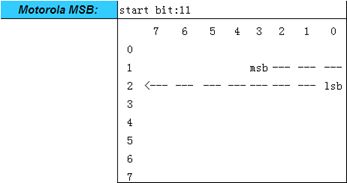
14.起始字节
Start_Byte就是指起始位所在的字节,在标准帧中这个值只能是0-7,不会出现大于7的情况。
15.起始位
Start_Bit对于不同排列格式的起始位是不相同的,这点一定要注意,得出的数据内容可能完全是两个东西,在标准帧中这个值只能是0-63,不会出现大于63的情况。
16.信号发送类型
Signal_Send_Type的类型主要有以下几种:Cycle,OnWrite ,OnWriteWithRepetition,OnChange ,OnChangeWithRepetition,IfActive,IfActiveWithRepetition等。
17.信号长度
Bit_Length代表信号的长度,不同排列格式虽然起始位不同,但是信号长度却是一样的,它代表该信号占了多个数据位,在标准帧中这个值只能是1-64,不会出现大于64的情况。
18.数据类型
Date_Type主要有两种,无符号和有符号,即Unsigned和Signed,其他还有IEEE float, IEEE Double等。
19.精度
Factor十六进制值的比例因子是为了计算信号的物理值。公式如下:
[Physical value] = ( [Hex value] * [Factor] ) + [Offset]
[物理值] = ( [十六进制值] * [精度] ) + [偏移量]
20.偏移量
Offset偏移量用来计算信号的物理值。
21.物理最小值
Signal_Min_Value_Phy指总线实际换算出来的最小值。
22.物理最大值
Signal_Max_Value_Phy指总线实际换算出来的最大值。
23.总线最小值
Signal_Min_Value指总线上的最小值。
24.总线最大值
Signal_Max_Value指总线上的最大值。
25.初始值
Initial_Value指如果在网络启动后没有可用的有效信号,预定义的值将被发送(取决于功能需求)。有效值必须在启动后此时间内可用。
26.无效值
Invalid_Value一般用于节点丢失时的替代值。
27.非使能值
Inactive_Value仅用于使能型及周期使能型报文。
28.单位
Unit指信号的换算单位,比如“%”“℃”等。
29.信号值描述
Signal_Value_Description指信号的代表的意思,比如:0x00:Close;0x01:Open代表当总线上信号的指为0x00的时候代表关闭,0x01代表打开。
30.备注
Comments即其他的描述。
31.发送节点
Transmitter代表该报文信号是哪个ECU发送的,指发送节点。
32.接收节点
Receivers代表该报文信号是哪些ECU接收的,指接收节点。
四、CAN解析方式
当我们拿到客户给过来的CAN矩阵后,我们如何才能快速的解析报文,如何才能快速的使用,其实方法有许多,其中很多人会选择去移位,比如 demo是起始字节是2,起始位是22,占用两个字节,在C语言中,我们可以解析如下:
char demo = (message.byte[0]>>5)&0xFF;
这样虽然能得到demo 信号的指,但是如果现在有无数个信号,解析的效率会非常的低,而且还容易出错,我们可以使用单片机的特性,使用共用体来解析,当然这需要注意一点,不同单片机有大端和小端的问题。
-
大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
-
小端模式:是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
在清楚单片机的大端和小端的情况,我们可以这样去定义一个共用体,假设该报文长度为4;我们可以定义如下共用体,后面称为位定义:
typedef union
{
uint8_t data[4];
struct
{
//Byte[0]
bits_t reserved0_7 :8;
//Byte[1]
bits_t reserved8_15 :8;
//Byte[2]
bits_t reserved16_21 :6;
bits_t demo :2;
//Byte[3]
bits_t reserved24_31 :8;
}bits;
}Msg_TYPE;//单片机为小端
typedef union
{
uint8_t data[4];
struct
{
//Byte[0]
bits_t reserved0_7 :8;
//Byte[1]
bits_t reserved8_15 :8;
//Byte[2]
bits_t demo :2;
bits_t reserved16_21 :6;
//Byte[3]
bits_t reserved24_31 :8;
}bits;
}Msg_TYPE;//单片机为大端
当报文接收到的时候,我们可以直接强制转换。
Msg_TYPE* p_msg = (Msg_TYPE)message.byte;
demo = p_msg -> demo;
这样就可以快速解析所有报文,但是如果手动去生成位定义的话也会显得十分麻烦,而且也容易出错,因此我写了一个上位机,可以直接解析Excel的数据内容,自动生成位定义,这样就可以大大的减轻工程师的负担。对于工具的使用后面有详细的讲解吗,在这儿我就不再重复讲解。
五、MatrixCreat工具
这儿我只把链接放上,具体使用说明见后续章节。
DBC转Excel;DBC转位定义;Excel转DBC;Excel转位定义:https://download.csdn.net/download/weixin_44926112/12594467
六、其他
本文主要是讲解对CAN矩阵的理解,有些地方可能会有描述性的错误,希望看到的朋友及时指出,我会及时更正错误,其他地方有些借鉴的描述,写此文章的目的是为了交流,非商业用途,欢迎私信讨论,感谢大家阅读。
七、参考
【1】:https://baike.baidu.com/item/CAN%E6%80%BB%E7%BA%BF/297754?fr=aladdin
【2】:https://www.jianshu.com/p/adeed02a552f
【3】:https://blog.csdn.net/jingling122/article/details/78599636