《持续交付》(一)概念与配置管理
引言
最近一段时间阅读了《持续交付》这本书,打算用几篇文章的篇幅总结一下阅读的收获。此为第一篇。我看的是英文原版的,书名是 Continuous Delivery,作者是 Jez Humble,由人民邮电出版社出版。

概念:持续交付
软件交付,就是软件从源代码形态到最终形成可交付的软件产品,并发布给用户的过程。那持续交付(Continuous Delivery)是什么意思呢?你可能听过持续集成(CI, Continuous Integration)和持续部署(Continuous Deployment) 等概念,这些概念和流程已经在业界广泛使用。以我的理解,这里的“持续”是一种结果,我们为了达到某种目的而“持续”,满足了某些条件的软件交付操作和行为,就是持续交付。那么为了达到什么目的呢?这就是:
以有效的、快速的和可靠的方式交付高质量、有价值的软件产品。
这是《持续集成》这本书中总结的目标,简单的一句话内涵比较丰富,可以说整本书都是围绕如何达到这个目标而展开。
那如何到达上述目标呢?只要做好两点:1. 自动化 2. 频繁发布。
自动而频繁的交付方式就达到了所谓的“持续”效果。书中使用部署流水线(Deployment Pipeline)的概念来形象地描述持续交付的过程。软件就像一个工业零件,在流水线上经过多重步骤的研发、生产、加工、检测,最后作为成熟产品交付给客户。下面是一个部署流水线的例子,有开发经验的同学看起来并不陌生:
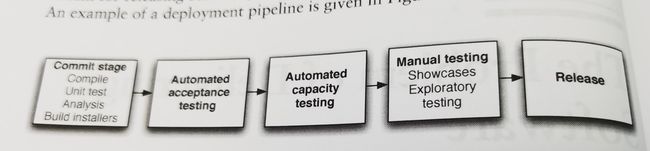
理解了持续交付的概念,我们来看为什么自动化、频繁地发布就能达到目标呢?这要从软件开发的一些反模式(Anti-pattern)行为说起。
为什么要采用持续交付?
想要弄清这个问题,我们先来看几个软件发布过程中的反模式(Anti-pattern)。
1、手动部署软件。现代软件系统和应用已经变得越来越复杂,部署过程涉及的技术和操作的细节也是很繁琐,即使是受过专业训练和资深的运维工程师(DevOps、SRE等)也难免犯错。
2、直到所有开发工作结束才开始部署类生产(Production-like)环境。通常在软件企业内部,类生产环境,如staging和production环境,是由运维团队(DevOps)或者(SRE, Site Reliability Engineer)团队完成,而如果这些团队直到开发工作接近尾声才第一次拿到可部署的软件版本,部署过程就很容易出问题。比如,拿到的配置在开发者那里是没问题的,但是不适用于部署类生产环境。还有一个问题是,在类生产环境通常还会发现一些bug,如果这些环境的部署很晚才进行,一些很严重的bug可能很晚才被发现,因而影响产品发布。
3、对生产环境进行手动配置。一旦生产环境的配置需要改变,比如线程池的大小、依赖库的版本等,运维人员直接去修改生产环境的配置文件或者数据库记录。这可能导致生产集群中的服务器有意无意地采用了不同的配置,而且修改的记录也不好追溯。当出现问题时,想回退到某个版本的配置也十分不便。
针对上述反模式的实践,我们来看自动化(automation)和频繁发布(frequent release)如何解决问题。
-
自动化:如果构建(build)、部署(deploy)、测试(test)和发布(release)过程全部自动化,那么这个过程就是可重复的。这就意味着每次交付的做法都是一致的,经过多次验证的,且不会引入人为失误。这也是频繁发布的基础。
-
频繁发布:如果频繁发布产品,那么每次发布产品特性的增量就是很小的,这就降低了风险。如果发现了问题,也可以快速及时回退。同时,频繁的发布新版本,也能及时得到反馈(feedback)。依据反馈,我们可以尽快发现整个软件交付流程中的问题。
附图有一个反馈的例子,你可以看到,在部署流水线上每一步都有反馈跟上,以此推动整个团队的行动。

《持续交付》这本书即围绕上述原则展开,我们就从配置管理开始。
配置管理(一)
下面我们来学习配置管理(Configuration Management)。配置管理可以用来解决以下问题:
- 如何重现一个软件运行环境,包括环境中各种配置?
- 在配置文件进行了小的改动,如何简单地将这个改动部署到需要的环境上?
- 如何追踪某个配置在何时、由谁修改过?
- 配置文件如何能够对团队成员共享以加速开发?
我想大家在软件开发的实践中,或多或少都接触过上述问题。其实看到这些问题,我们很自然想到的解决方案就是:使用版本控制系统。
《持续交付》这本书推荐将一切配置都使用版本控制系统来管理,即把配置像代码一样管理。好处就是,你可以始终对配置的改动进行追踪,找到需要的版本进行升级或回退,找到对应的修改者,以及拿到其他工程师最新的改动。
除了上述好处,我们在使用版本控制工具管理配置文件时还需要注意:
1、及时check-in代码:及时提交代码能保证自动化的持续交付过程始终在用最新的配置进行。如果长时间不提交,新的配置得不到验证,那么时间久了就可能引发较大的问题,阻断交付的流程。
2、使用有意义的提交信息:这一点很直观,有意义的信息可以帮助自己和他人理解每一次改动,从而定位问题和找到需要的版本。
配置文件可能存在于持续交付的各个阶段,比如在构建(build)、部署和运行时,都可能使用到配置。我们常见的是在部署和软件运行时动态使用配置文件,对于build阶段,配置可能会提供一些工具上的支持。
从功能上看,配置文件可用于管理依赖、管理软件应用和管理环境。我们先看管理依赖。如果你做过Web前端开发,对NPM的package.json文件应该很熟悉。如果你做过.NET应用的开发,对package.config文件应该很熟悉。这些都是管理内部和外部依赖包的配置文件,并且通常需要跟源代码一起管理起来。应用程序在构建时,会读取这个配置,从内部或外部的服务器上下载构建需要的依赖包。对于依赖管理有两点要注意:
1、依赖包的版本不能随意更改。因为依赖可能来自第三方的开发者,新版本的特性可能会导致你的应用程序出错。
2、依赖包的服务器可以在企业内部自己搭建,这样可以有好的响应速度,也可以解决上述依赖更新导致的问题。
接下来我们来看配置管理的另外两个功能。
配置管理(二)
下面我们继续看应用程序和运行环境的配置管理。
应用程序中的配置通常是跟程序的逻辑相关的,为了实现上的灵活性,我们需要把一些数据写到配置文件中。这样我们通过更改配置文件,就可以实现程序逻辑的控制。我们常见的配置文件有Java程序的properties文件,JavaScript程序的JSON文件,Ruby程序的YAML文件,以及通用的XML文件等等。
不过这里有一个权衡的问题。如果过度重视灵活性,即可配置的程度太高,那么程序就可能丧失一些功能性;反之,如果可配置的逻辑很少,那么很多代码都是写死的,就不容易动态修改程序行为。
另一个问题是对配置文件的测试。我们容易忽略对配置文件的测试,甚至是最基本的语法检查都不注意,因为很多代码编辑器都不会检查配置文件的语法。在开发时候,配置文件可以正常被读写,但是部署到线上,由于环境和应用程序逻辑的变化,配置文件可能出问题。解决的方案就是积极地进行部署测试,即冒烟测试(smoke test)。冒烟测试的目的就是看看部署后的环境是否能正常工作,考察配置文件的功能是其中一个关注点。
还有一个问题是配置文件的访问。好的实践方式是在应用程序中采用统一的配置存储和访问方式。比如,配置可以来自文件、API以及数据库,那么在各个模块中就尽量采用同一种方式,这样配置除了问题,排查起来就容易定位。另外,我们通常会在程序中定义专门访问配置的模块(类、接口),并开放给其他模块使用,将配置的读写逻辑抽象和封装起来,这样也有利于配置的管理和代码重构。
在建模一个配置对象时,通常考虑三个因素:
- 配置是给哪个应用和模块用的。
- 应用和模块的版本。
- 配置适用的环境。不同的模块的配置通常不同,而随着版本更新,配置也应该更新,因为有些配置可能已经失效了,或者添加了新的配置。对于不同的环境,如test,staging和production,通常采用不同的配置。
最后我们来看环境的配置管理。我们希望能够随时自动生成一个满足要求的运行环境,这个环境包含的配置可能有:
- 操作系统的类型以及设置(如Windows Server 2012)。
- 预装的软件和服务(如IIS服务器)。
- 网络拓扑(如外网访问)。
- 外部的服务。
有了这些配置,环境的部署和重建就是可重复的,并且可以在预期时间内完成。我的经验是,很多项目组并没有把环境部署也写成配置,每次部署都需要很多人工操作,这对于持续交付来说是不可接受的。另外,在环境部署时需要建立基线(baseline) 的概念,即把上一次成功部署的环境配置作为基线,每次有新的配置改动,就更新基线配置。这样下次重新部署时,就可以以基线为准,省去了很多重复工作。其实,这背后的思想就是把环境也当作代码来维护。
以上就是关于配置管理的学习总结,欢迎讨论。接下来我们关注持续交付流程中的第一个重头戏:持续集成(continuous integration)。