ava多线程:volatile变量、happens-before关系及内存一致性
请参考来自 Jean-philippe Bempel 的评论。他提到了一个真实因 JVM 优化导致死锁的例子。我尽可能多地写博客的原因之一是一旦自己理解错了,可以从社区中学到很多。谢谢!
什么是 Volatile 变量?
认真点,别开玩笑,什么是 Volatile 变量?我们应该什么时候使用它?
volatile 关键字的典型使用场景是在多线程环境下,多个线程共享变量,由于这些变量会缓存在 CPU 的缓存中,为了避免出现内存一致性错误而采用 volatile 关键字。
考虑下面这个生产者/消费者的例子,我们每次生成/消费一个元素:

在上面的类中,produce 方法通过存储参数来生成一个新的值,然后将 hasValue 设置为 true。while 循环检测标识变量(hasValue)是否 true,true 表示一个新的值没有被消费,要求当前线程睡眠(sleep),该睡眠一直循环直到标识变量 hasValue 变为 false,只有在新的值被 consume 方法消费完成后才能变为 false。如果没有有效的新值,consume 方法要求当前睡眠,当一个 produce 方法生成一个新值时,睡眠循环终止,并改变标识变量的值。
现在想象有两个线程在使用这个类的对象,一个生成值(写线程),另个一个消费值(读线程)。通过下面的测试来解释这种方式:
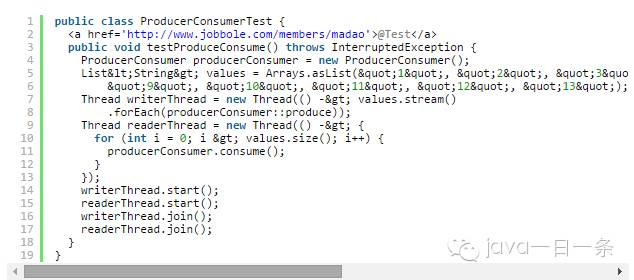
这个例子大部分时候都能输出期望的结果,但是也有很大概率会出现死锁!
怎么会?
我们都知道计算机是由内存单元和 CPU (还有许多其他部分)组成。主内存就是程序指令、变量、数据存储的地方。程序执行期间,为了获得更好的性能,CPU 可能会将变量拷贝到自己的内存中(即所谓的 CPU 缓存)。由于现代计算机有多个 CPU,同样也存在多个 CPU 缓存。
在多线程环境下,有可能多个线程同时执行,每个线程使用不同的 CPU(虽然这完全依赖于底层的操作系统),每个 CPU 都从主内存中拷贝变量到它自己的缓存中。当一个线程访问这些变量时,是直接访问缓存中的副本,而不是真正访问主内存中的变量。
现在,假设在我们的测试中有两个线程运行在不同的 CPU 上,并且其中的有一个缓存了标识变量(或者两个都缓存了)。现在考虑如下的执行顺序
1、写线程生成一个值,并将 hasValue 设置为 true。但是只更新缓存中的值,而不是主内存。
2、读线程尝试消费一个值,但是它的缓存副本中 hasValue 被设置为 false,所以即使写线程生产了一个新的值,也不能被消费,因为读线程无法跳出睡眠循环(hasValue 的值为 false)。
3、因为读线程不能消费新生成的值,所以写线程也不能继续,因为标识变量没有设置回 false,因此写线程阻塞在睡眠循环中。
4、这样,就产生了死锁!
这种情况只有在 hasValue 同步到所有缓存才能改变,这完全依赖于底层的操作系统。
那怎么解决这个问题? volatile 怎么会适合这个例子?
|
1
|
private
volatile
boolean
hasValue =
false
;
|
volatile 变量强制线程每次读取的时候都直接从主内存中读取,同时,每次写 volatile 变量的时候也要立即刷新主内存中的值。如果线程决定缓存变量,就需要每次读写的时候都与主内存进行同步。
做这个改变之后,我们再来考虑前面导致死锁的执行步骤
1、写线程生成一个值,并将 hasValue 设置为 true,这次直接更新主内存中的值(即使这个变量被缓存了)。
2、读线程尝试消费一个值,先检查 hasValue 的值,每次读取都强制直接从主内存中获取值,所以能获取到写线程改变后的值。
3、读线程消费完生成的值后,重新设置标识变量的值,这个新的值也会同步到主内存(如果这个值被缓存了,缓存的副本也会更新)。
4、写线程获每次都是从主内存中取这个改变了的值,这样就能继续生成新的值。
现在,大家都很幸福了^_^ !
我知道了,强制线程直接从内存中读写线程,这是 Volatile 所能做全部的事情吗?
什么是 happens-before 关系?
这与 Volatile 是怎么关联的?
嗯…,好吧…,我有点明白了,但是可能通过一个例子会更清楚。
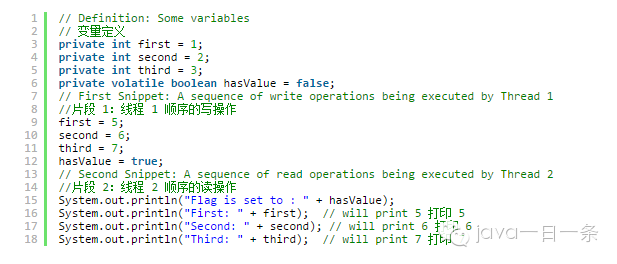
我们假设上面的两个代码片段有由两个线程执行:线程 1 和线程 2。当第一个线程改变 hasValue 的值时,它不仅仅是刷新这个改变的值到主存,也会引起前面三个值的写(之前任何的写操作)刷新到主存。结果,当第二个线程访问这三个变量的时候,就可以访问到被线程 1 写入的值,即使这些变量之前被缓存(这些缓存的副本都会被更新)。
这就是为什么我们不需要像第一个示例一样将变量标示为 volatile 。因为我们的写操作在访问 hasValue 之前,读操作在 hasValue 的读之后,它会自动与主内存同步。
还有另一个有趣的结论。JVM 因它的程序优化机制而闻名。有时对程序语句的重排序可以大幅度提高性能,并且不会改变程序的输出结果。例如,它可能会修改如语句的顺序:

即使从程序的正确性的角度来说,上面两种情况是相等的。但请注意,JVM 仍然允许对前三个变量的写操作进行重排序,只要它们都出现在 volatile 写之前即可。
类似的,JVM 也不会将 volatile 变量读之后的读操作重排序到 volatile 变量之前。意思就是说,下面的顺序:
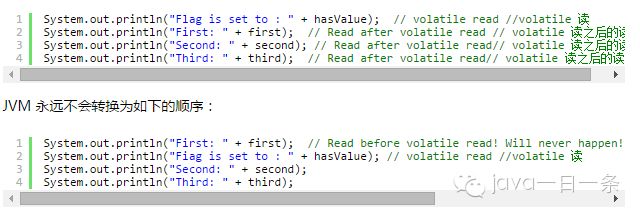
但是,JVM 也有可能会对最后的三个读操作重排序,只要它们在 volatile 变量读之后即可。
我感觉 Volatile 变量会对性能有一定的影响。
我们总能用 Volatile 变量来维护多线程之间的数据一致性吗?

这段代码具有非常好的自说明性。一个线程增加计数器,另一个线程将计数器减少同样次数。运行这个测试,期望的结果是计数器的值为 0,但这无法得到保证。大部分时候是 0,但有的时候是 -1, -2, 1, 2 等,任何位于[-5, 5]之间的整数都有可能。
为什么会发生这种情况?这是因为对计数器的递增和递减操作都不是原子的——它们不是一次完成的。这两种操作都由多个步骤组成,这些步骤可能相互交叉。你可以认为递增操作如下:
递减操作的过程如下:
读取计数器的值。
现在我们考虑一下如下的执行步骤
第一个线程从主存中读取计数器的值,初始值是 0,然后加 1。
怎么防止这类事件的发生?

我个人的选择是使用 AtomicInteger,因为 synchronized 只允许一个线程访问 inc/get/get 方法,对性能影响较大。
我注意到采用 Synchronized 的版本并没有将计数器标识为 volatile,难道这意味着……?
关于一开始提到的 volatile, 这些是所有我想说的。所有的例子都上传到了我的 github 仓库。