Centos7环境搭建hadoop2.9.0集群全流程
1.安装环境配置
1.1 虚拟机安装
本案例是在虚拟机平台搭建hadoop,由于笔记本限制仅以2台设备构建内部局域网环境下的集群。
虚拟机版本:VMwareWorkstation_10.04_Lite_CHS_V2
系统:CentOS-7-x86_64
安装2台虚拟机(本来准备装3台,但太卡了所以最后只保留了hserver1,hserver3)
1.2 虚拟机设置固定IP
虚拟机每次启动后,一般IP地址是通过DHCP随机分配的,为了方便以后的设备访问这里需要对每台机器手动配置固定IP。
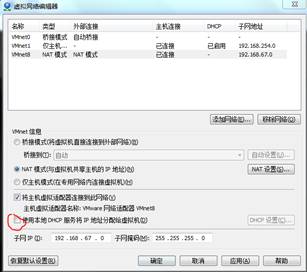
(1)进入:编辑—>虚拟网络编辑器,在VMnet8的配置中取消勾选使用本地DHCP服务。
(2)登陆centOS7系统,在设置中找到network connections。在wired connection中添加IPV4 Settings:

这里地址的192.168.67.XX与上面子网IP相同,XX自己定义。网关掩码也与上面子网掩码相同。DNS服务器一般都是192.168.XX.2,可以在/etc/resolv.conf中name server找到对应。
设置好后可以重启系统,再通过ifconfig查看:
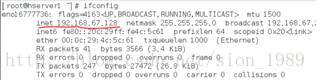
同样方法配置hserver3固定IP,最后结果如下:
hserver1 192.168.67.128
hserver3 192.168.67.1322. 配置机器名称
2.1 修改机器名称
为了方便后续操作,需要hserver1和hserver3机器名称修改。
以hserver1机器为例:从root账户登录,输入host命令可以查看机器名称,系统默认为localhost.localdomain。执行:
[root@hserver1 ~]#host hserver1该指令只能暂时修改机器名,重启后还是会恢复默认。永久修改机器名应当采用hostnamectl,执行:
[root@hserver1 ~]# hostnamectl set-hostname hserver1同样方法修改hserver3机器名。
2.2 修改hosts文件
分别在2机器上通过 vim/etc/hosts打开hosts文件,添加:
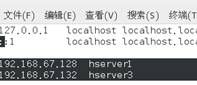
保存后退出。此时hserver1与hserver3应该能ping通。执行:
[root@hserver1 ~]# ping hserver3 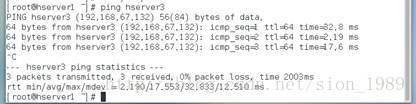
3. 实现ssh远程登录
3.1 每个机器生成秘钥文件
在hserver1上生成秘钥文件,执行:
[root@hserver1 ~]# ssh-keygen -t rsa -P ''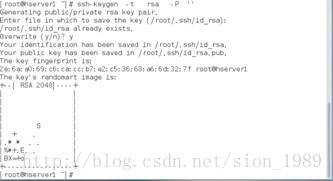
这里因为是在已有秘钥基础上重新演示,所以会提示overwrite,正常情况不会出现。执行后可以查看到秘钥文件存放在/root/.ssh/id_rsa.pub。
同样方法在hserver3生成秘钥文件。
3.2 组成公钥文件
首先查看hserver1上的密钥内容,执行:
[root@hserver1 ~]# vim /root/.ssh/id_rsa.pub
同样在hserver3执行后看到如下内容:
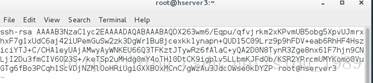
之后在herver1本地新建authorized_keys文件,将上面2份秘钥内容放进去。执行:
[root@hserver1 ~]# vim /root/.ssh/authorized_keys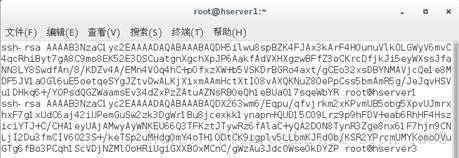
然后将authorized_keys复制到herver3同名目录位置。在VM虚拟机可以先将该文件复制出来到本地电脑,在从本地电脑复制到hserver3文件夹内。
3.3 测试ssh远程登录
在hserver1机器上执行:
[root@hserver1 ~]# ssh hserver3![]()
这里需要输入hserver3的root账号密码,之后就可以远程登录hserver3了。退出执行:exit。
同样在hserver3也可以远程登录hserver1:
![]()
4. 安装JDK
安装的centos7自带java组件,但功能不全,后续运行hadoop会出错。因此需要在herver1和hserver3分别重新安装JDK组件。
4.1 卸载系统自带JDK
首先查询系统自带的JDK,执行:
[root@hserver1 java]# rpm -qa|grep java可以看到有以下文件:
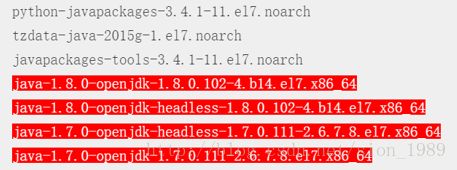
其中标红的文件需要卸载。
执行以下4条指令完成卸载:
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodepsjava-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodepsjava-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodepsjava-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64 4.2 下载JDK
下载支持linux64位的JDK,网址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
我下载的版本是jdk-8u151-linux-x64.tar.gz。
4.3 安装JDK
新建目录/opt/java,将下载好的安装包放进去。通过指令进入/opt/java文件夹,执行:
[root@hserver1~]# cd /opt/java之后在当前文件夹解压安装包,执行:
[root@hserver1java]# tar -xvf jdk-8u151-linux-x64.tar.gz解压成功后目标文件夹内会多出一个文件夹:
解压完成后原安装包就没用了,记得删除节省空间。
4.4 配置环境变量
打开配置文件,执行:
[root@hserver1java]# vim /etc/profile在文件最后添加以下变量:
exportJAVA_HOME=/opt/java/jdk1.8.0_151
exportJRE_HOME=$JRE_HOME/jre
exportCLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH注意:其中JAVA_HOME对应的是你安装的JDK版本及路径。
保存文件之后记得执行以下指令让其生效:
[root@hserver1java]#source /etc/profile现在可以检测下环境变量是否添加成功。执行:echo $ JAVA_HOME
![]()
环境变量添加成功后可以测试JDK是否可用了。执行javac后出现以下信息说明安装成功:

5. 安装hadoop
以下安装步骤在hserver1和hserver3都需要做一遍。
5.1 创建文件夹
/root/hadoop
/root/hadoop/tmp
/root/hadoop/var
/root/hadoop/dfs
/root/hadoop/dfs/name
/root/hadoop/dfs/data5.2 下载hadoop2.9.0及解压
下载hadoop-2.9.0.tar.gz,网址:
http://hadoop.apache.org/releases.html
将文件放在/root/hadoop文件夹内。
进入文件夹,执行:
[root@hserver1 java]#cd /root/hadoop解压文件到当前目录下,执行:
[root@hserver1 hadoop]# tar –xvf hadoop-2.9.0.tar.gz解压完成后删除原安装包。
5.3 修改配置文件
5.3.1 修改hadoop-env.sh
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}
修改为export JAVA_HOME=/opt/java/jdk1.8.0_151
将 export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
修改为export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.9.0/etc/hadoop
然后使环境变量生效,执行:
source /opt/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh5.3.2 修改slaves文件
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/slaves
将里面的localhost删除,添加hserver3。
注:hsever3机器配置时也是添加hserver3,这里是定义从机名称。
5.3.3 修改core-site.xml文件
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml
在
hadoop.tmp.dir
/root/hadoop/tmp
fs.default.name
hdfs://hserver1:9000
5.3.4 修改hdfs-site.xml文件
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
在
dfs.name.dir
/root/hadoop/dfs/name
dfs.data.dir
/root/hadoop/dfs/data
dfs.replication
1
5.3.5 新建及修改mapred-site.xml文件
在/opt/hadoop/hadoop-2.9.0/etc/hadoop/中没有mapred-site.xml文件,但可以通过复制mapred-site.xml. template文件重命名为mapred-site.xml,再进行修改。在
mapred.job.tracker
hserver1:49001
mapred.local.dir
/root/hadoop/var
mapreduce.framework.name
yarn
5.3.6 修改yarn-site.xml文件
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
在
yarn.resourcemanager.hostname
hserver1
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
1024
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.resource.memory-mb
1024
yarn.nodemanager.vmem-check-enabled
false
6. 启动hadoop
现在hserver1是namenode,hserver3是datanode,只需要在hserver1上进行初始化及启动操作。
6.1 格式化namenode
首先进入namenode格式化命令所在目录:
[root@hserver1 hadoop]#cd /opt/hadoop/hadoop-2.9.0/bin然后执行namenode格式化命令:
[root@hserver1bin]# ./hadoop namenode –format跳出如下信息说明初始化成功:


6.2 启动hfs和yarn
进入到启动命令文件夹:
[root@hserver1bin]# cd /opt/hadoop/hadoop-2.9.0/sbin启动dfs和yarn:
[root@hserver1bin]#./start-all.sh启动成功后会看到以下信息:
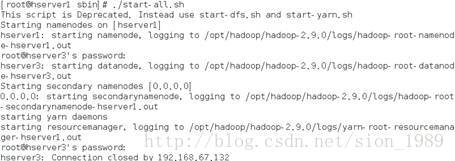
输入jps可以看到如下信息:

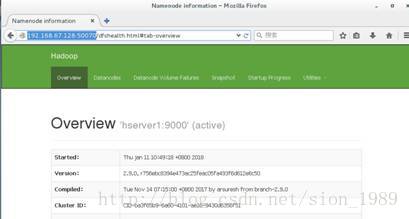
6.3 访问网页
首先关闭防火墙:
[root@hserver1sbin]# systemctl stop firewalld接下来访问hadoop管理首页,hserver1的IP是192.168.67.128,因此访问:
http://192.168.67.128:50070
参考文献
http://blog.csdn.net/pucao_cug/article/details/71698903#reply