提示:本文毫无可读性,完全是自己的读书笔记
叶子页的分裂
主键索引一次叶子页分裂将导致其余索引上大量的磁盘I/O;对主键索引列的更新操作,会引起索引行的异动,从而导致叶子页的分裂。
索引的选择性(与Cardinality有关)
选择性=cardinality/总行数
选择性越是接近于1越好,换言之,cardinality越大越好
以常见的反例“性别”来进行距离,cardinality=2,选择性无限趋近于0,这无疑是非常糟糕的
最差情况下的选择性比平均选择性更重要,因为如果照顾了平均选择性而忽略最差选择性的话,有可能造成某一个SQL查询特别慢
选择性的好坏,与后面提到的索引片有很大的关系;选择性越好,索引片越窄
cardinality是一个估算值(忽略同一字段建2个索引的睿智操作,不是我干的!)

相同字段下,不同时段创建的2个单一索引,Cardinality值不同
怀疑是统计没有更新,手动执行更新
(t表1500万行数据,在空闲库执行下面的语句时间338s,不要在忙时去执行这个语句)
alter table t engine=innodb;
执行后的索引信息如下

可以看到值与之前统计的值不同,而且同一字段对应的2个索引的cardinality值仍然不同
此外,在show index这里展现的cardinality估算得并不准确,甚至可能出现非常大的偏差
比如这个例子中的monthly_settlement,看起来在这个索引中,这一列的选择性是最好的,station_id的选择性看起来就没这么好
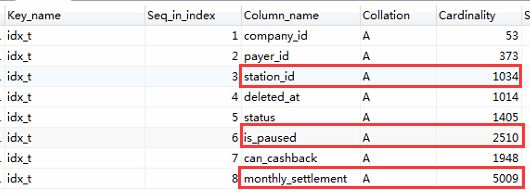
然而实际情况并非如此

所以cardinality只能当做一般性的参考,如果要严格的计算选择性,还是需要用 “distinct 列名/总行数” 这种方式去计算,值越趋近于1,说明该列选择性越好
组合谓词的选择性(谓词:前面提到的3要素中的索引列)
简言之就是2个单列索引的效果可能远不如这2个字段的联合索引
优化器在评估访问路径成本时,必须先评估索引的选择性。(其实选择性的好坏也是三星索引的第一颗星)
等价的索引
where a=:a and b=:b
如果创建索引(a,b)和索引(b,a),这2个索引是等价的,因为where语句后面跟的2个都是等值条件,如果其中一个是范围条件,那么这2个索引就不等价了
回表采用的是随机读
三星索引
第一颗星:索引片的宽窄;
第二颗星:索引是否能够处理排序;(避免排序)
第三颗星:查询列是否在索引中
一般来说,第一颗星要比第二颗星重要,一个尽量窄的索引片比避免排序要重要;但这只是一般来说
下列例子说明了第一颗星的重要性
#sql语句
SELECT MAX(id)
FROM t
WHERE '2019-01-07 23:59:59' >= create_time
GROUP BY user_id;
索引1:idx_ct_uid(create_time,user_id)
索引2:idx_ct(create_time),idx_uid(user_id)
user_id是一个varchar(30)的列
全表行数为270W行,使用索引1的情况下,执行时间为6s,使用索引2的情况下,执行时间为1.5s
归结原因,条件列是一个范围查询,索引1能用到的其实只有create_time这部分,但是user_id列的加入,使得这个联合索引的索引片宽度大增,因此花了更多的时间去扫描。
宽索引
一个索引如果(至少)包含了第3颗星,那么这个索引就是一个宽索引
困难谓词(索引失效问题)
简单来说就是参照下面的口诀:
全值匹配我最爱,最左前缀要遵守
带头大哥不能死,中间兄弟不能断
索引列上少计算,范围之后全失效
like百分写最右,覆盖索引不写星
不等空值还有or,索引失效要少用
表连接的索引
关于嵌套循环
本地谓词和连接谓词
只用于访问一张表的谓词被称为本地谓词
定义了表和表之间的连接关系的谓词被称为连接谓词
抛开比较复杂的嵌套查询
只有本地谓词的那张表,将会成为外表,而另一张表自然成为了内表
外表也就是驱动表,要求是尽量的小
外表的小并不是指外表的总行数小,而是指经过外表的过滤因子之后取得的索引片比较小,这样会获得更好的性能
在嵌套查询中,内表产生大量随机读取是影响性能的一个关键因素,因此内表需要有一个比较好的宽索引,并且以连接谓词作为前导列(也就是连接谓词作为最左)
eg
select .... from A,B
where A.a=:a
and B.b=A.b;
在上面这个查询中,A.a是A表的本地谓词,所以A表很明显的就是外表,而B表就是内表,其中B.b是B表的连接谓词,为了减少内表的随机读,内表上需要有一个合适的以B.b为前导列的宽索引。
(由于这里的连接条件里只有B.b=A.b,如果B.b的选择性很差,那么这个内表的查询效率有可能很低,这种情况下,可以通过补全一些谓词去提高连接谓词的选择性(冗余字段),可以使内表尽可能快的查出结果,毕竟一般来说外表都是小表,内表相对较大,对性能的影响是比较大的。该段参考《数据库索引设计与优化》第8章的那个例子(CCTRY),该案例中有一个补全FF缺陷的技巧; 这个技巧在P178页中被描述为向下反范式,也就是内表加列;与之对应的还有向上反范式,也就是外表加列,不过需要注意所加冗余列的易维护性)
对于or的优化
可以改写成union+order by的形式
但是否能优化好,取决于一些条件是否完全匹配
有一些语句即使索引优化的很好,但union + order by仍然造成性能问题
--2019.7.25验证2年前的笔记
使用索引进行排序:(避免排序)
order by也需要满足索引最左前缀要求,才能用索引排序
比如索引为idx(b,c)
select xxx from table_a where a='x' order by b,c;
除此之外,索引列是一个常量的情况下,即使order by的部分不满足最左,也可以使用
比如索引为idx(a,b,c);索引列为常量的情况,说的就是where a='x'(如果是a>'x',或者是a in('x','y')则属于范围,不属于常量)
所以下列索引列和order by组成了a,b,c的顺序,满足了idx(a,b,c)的顺序
select xxx from table_a where a='x' order by b,c;
但是如果索引列为a>'x',这是一个范围查询,那么上面的语句无法使用idx(a,b,c)进行索引排序(下面的语句可以,因为order by满足了最左)
select xxx from table_a where a>'x' order by a,b;
关于最左前缀之前的一个理解错误的地方
idx(a,b,c)
select xxx from table_a where c='t' and b='y' and a='x'这样仍然会走索引,虽然顺序不一样,但是a,b,c都在where条件里面,并不需要把where写成a,b,c的顺序才行。
一些无法使用索引排序的例子;(索引仍然为idx(a,b,c))
1.逆序导致的方向不对
select xxx from table_a where a='x' order by b desc,c desc;


上面2张图对比可以看出desc字段没有走索引,但是从key_len来看2者没有变化,key_len记录的应该只是where后面走索引的字段,而对于排序部分是不记录的,至少5.7版本是这样
2.order by有其他列
select xxx from table_a where a='x' order by b,d;
3.中间列(b)断了
select xxx from table_a where a='x' order by c;
4.索引列有一个是范围查询
select xxx from table_a where a='x' and b in ('x','y') order by c;
5.延迟关联,本表会被当成第二张表,因此也无法使用
eg.排序走索引测试

涉及的字段,type,status,create_time,update_time(重要:下文以a,b,c,d代替)
idx_0对上述4个(a,b,c,d)字段建有联合索引
idx_1对前面2个(a,b)字段建有联合索引
语句1
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time;
where a=,b= order by c类型,加上查询字段的d,覆盖索引,排序走索引
语句2
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time desc;
where a=,b= order by c desc类型,虽然排序是倒序,但仍然走了索引,并没有filesort
语句3
select update_time from tra_trade where type='POS_ONLINE_PAY' and status!='SUCCESS' order by create_time;
where a=,b!= order by c 类型,出现b列出现了不等于,相当于(a,b,c)中的b断了,a肯定能走索引的,从key_len来看,b也走了,后面的c走不了,c出现了排序
语句4
select update_time from tra_trade where type='POS_ONLINE_PAY' and status!='SUCCESS' order by type,status,create_time;
where a=,b!= order by a,b,c 类型,全都走了索引
语句5
select update_time from tra_trade where type='POS_ONLINE_PAY' and status!='SUCCESS' order by type,create_time;
where a=,b!= order by a,c 类型,排序中的(a,b,c)断了,c走不了索引,出现了排序
#前面5个类型属于必须要记住的分类,后面的十几个语句算是更细节的探索
语句6
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by status,update_time;
where a=,b= order by b,d 类型,排序中的(b,c,d)断了,d肯定走不了索引会出现排序;这个语句的疑问在于b不满足最左,同时也不像前面的where a,b order by c那样满足连贯,b是否能走索引?
语句6变种
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by status;
将语句6中排序的d列(update_time)去掉后,语句变成了where a,b order by b类型,没有产生排序
语句7
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by status,create_time;
where a=,b= order by b,c 类型,语句7是前面语句6变种的延伸,与6的变种一样,没有产生排序
语句8
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by status,create_time desc;
where a=,b= order by b,c desc 类型,与7一样,没有产生排序
语句9
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time desc,status,type;
语句10
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time,status,type;
语句11
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time,type;
语句12
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time,status;
语句13
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time,type,update_time;
语句14
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time,status,update_time;
9和10都看作是where a=,b= order by c,b,a 类型,区别只是c是否有带desc;11是where a=,b= order by c,a 类型;12是where a=,b= order by c,b 类型;13是where a=,b= order by c,a,d 类型;11是where a=,b= order by c,b,d 类型;全都没有产生排序
语句15
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by update_time;
where a=,b= order by d 类型,(a,b,d断裂),d肯定走不了索引,产生排序
语句16
select update_time from tra_trade where type='POS_ONLINE_PAY' and status='SUCCESS' order by status,payee_charge_amount;
where a=,b= order by b,e 类型,e都不在索引里,肯定产生排序,此外排序列不在索引列,using index都没了,把覆盖索引都给破坏了
语句17
select * from tra_trade force index (idx_0) where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time;
select * from where a=,b= order by c类型
语句18
select * from tra_trade force index (idx_0) where type='POS_ONLINE_PAY' and status='SUCCESS' order by create_time desc;
select * from where a=,b= order by c desc类型
17和18的排序一个正序一个倒序,但查询列从索引的d字段变成了*,首先排序肯定是没有产生的,但有意思的是执行计划里面的extra字段变了;正序走了icp,倒序就走了个using where
18个语句的测试结论:
1.order by中的倒序,不会产生排序(filesort);如果你的执行计划里面产生了filesort,起码不能简单归结于是排序中有desc
2.如果where部分是常量,且查询部分没有出现中间断裂的情况,那么order by可以不用遵循最左原则
3.如果where部分有范围(不等于相当于范围),那么order by必须遵循最左原则
4.where部分与order by部分必须避免出现中间断裂的情况,只要出现中间断裂,必然产生filesort;只要不出现中间断裂,无论order by部分字段的先后顺序如何都不会产生filesort
5.排序中的desc并不会产生filesort,但desc是否会影响数据的过滤,不得而知,至少从17和18这2句的执行计划可以发现extra有明显的不同
#第4点字面很难看明白,特别解释一下
首先说明一下怎样算断裂:断裂点通常有2个地方,一个是where和order by接壤的地方,比如where后面是ab,order by是d,中间的c没有,就断掉了;另一个地方就是order by自身,比如where是ab,order by是abd,也是漏掉了c;但如果where部分是ab,order by部分是ac,看起来order by部分好像断掉了,实际上把where和order by连起来看,abc都已经存在了,所以就不存在中间断掉的情况。 此外,前面都是在where条件为常量的情况下,如果where部分存在范围,那么order by必须满足最左,并且一旦order by中存在断裂则视为断裂
结论第4点前半句中标粗的“避免中间断裂”的意思是where部分是ab,索引部分可以是c,或者cd,或者abc,或者是ac,或者bc;总之确保where和order by连起来是一个ab,c或者ab,cd或者ab,abc或者ab,ac或者ab,bc之类的模式,但绝对不能出现ab,d这种模式(也就是说where或者order by中只有a,b,d但),一旦出现断裂,则必然出现filesort
第4点后半句中的“部分字段的先后顺序”的意思是无论是order by abc还是cba还是cab都无关紧要,都不会出现filesort