TensorFlow.js课程笔记(一)
前言
在Coursera上学习了一下课程《Browser-based Models with TensorFlow.js》,感觉TensorFlow.js还是十分有趣的,可以让网页能够调用终端的运算资源,这样一来可以大大缓解云端的计算压力。
Coursera上这门课还是比较推荐初学者去听一下的,基本上对各个部分的应用都有很详细的讲解。不过总体不算很深入,主要是老师讲解了一遍整个TensorFlow.js的应用过程吧。这边也是算做一下笔记加深一下理解吧。
课前准备
- 注册课程(奖学金的话要15天审核,有钱就直接买吧)
- 编程环境(具体其实可以跟着上课后下载)
- 谷歌浏览器
- python3 + Tensorflow 2.0(后面两章会用)
- 一架稳定的小飞机(个人认为还是很需要的,国内视频流很慢,而且要从谷歌商店下载插件,之后一些文件也是在国外的服务器上)
- 一些HTML、JavaScript基础(能帮助理解)
第一周
第一周主要就是讲了一些TensorFlow.js的基础应用,怎么样搭建一个模型并进行训练的。
引入TensorFlow.js很简单,直接一个script标签就好了。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest">script>
拟合直线
这个是最简单的一个直线的拟合 y = w ∗ x + b y=w*x + b y=w∗x+b,输入是一个数 x x x,输出一个数 y y y,中间的神经元仅需要一个。
因此构建模型结构,只有一个输出层,这个网络只有一层,一个节点。
构建顺序如下:
- 构建网络结构
- 确定损失函数为均方误差,使用sgd方法进行优化
- 喂入训练数据
- 进行拟合训练
- 预测输入的测试数据
代码如下:
async function doTraining(model){
const history =
await model.fit(xs, ys,
{ epochs: 500,
callbacks:{
onEpochEnd: async(epoch, logs) =>{
console.log("Epoch:"
+ epoch
+ " Loss:"
+ logs.loss);
}
}
});
}
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [1]}));
model.compile({loss:'meanSquaredError',
optimizer:'sgd'});
model.summary();
const xs = tf.tensor2d([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], [6, 1]);
const ys = tf.tensor2d([-3.0, -1.0, 2.0, 3.0, 5.0, 7.0], [6, 1]);
doTraining(model).then(() => {
alert(model.predict(tf.tensor2d([10], [1,1])));
});
异步函数
这边需要注意的是async,即异步函数,函数中一般都有await这个关键词,该指令会暂停异步函数的执行,并等待model.fit完成执行,然后继续执行异步函数,并返回结果。这个写法后面也会经常用到。
构建模型
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [1]}));
这两句话就是构建的网络,一个layer要写明输入层输入参数的特征数,然后后面的units为1就是表示只有一个神经元。
预测
doTraining(model).then(() => {
alert(model.predict(tf.tensor2d([10], [1,1])));
});
预测的话直接输入一个数10,后面[1,1]表示的是输入向量的形状。完成训练之后,网页就会跳出结果。

summary
代码中的summary能帮助我们在控制台中观察网络结构
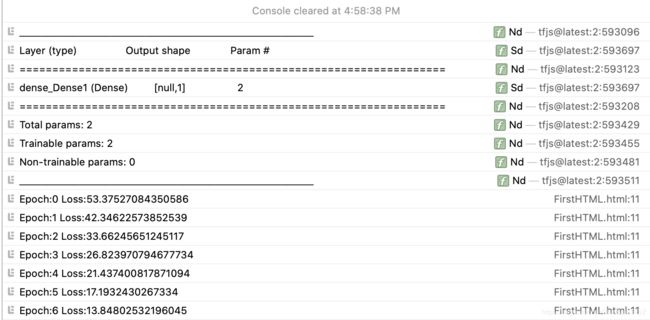
可以看到只有一层,输出是1个数,然后有两个参数,个人理解就是w和b。
后面就是Loss的数值了,500轮后损失就会变得很小。
鸢尾花
也是很经典的一个数据集了,多特征多分类问题,作为练手的话不错。
代码如下:
async function run(){
const csvUrl = 'iris.csv';
const trainingData = tf.data.csv(csvUrl, {
columnConfigs: {
species: {
isLabel: true
}
}
});
const numOfFeatures = (await trainingData.columnNames()).length - 1;
const numOfSamples = 150;
const convertedData =
trainingData.map(({xs, ys}) => {
const labels = [
ys.species == "setosa" ? 1 : 0,
ys.species == "virginica" ? 1 : 0,
ys.species == "versicolor" ? 1 : 0
]
return{ xs: Object.values(xs), ys: Object.values(labels)};
}).batch(10);
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [numOfFeatures], activation: "sigmoid", units: 5}))
model.add(tf.layers.dense({activation: "softmax", units: 3}));
model.compile({loss: "categoricalCrossentropy", optimizer: tf.train.adam(0.06)});
await model.fitDataset(convertedData,
{epochs:100,
callbacks:{
onEpochEnd: async(epoch, logs) =>{
console.log("Epoch: " + epoch + " Loss: " + logs.loss);
}
}});
// Test Cases:
// Setosa
const testVal = tf.tensor2d([4.4, 2.9, 1.4, 0.2], [1, 4]);
// Versicolor
// const testVal = tf.tensor2d([6.4, 3.2, 4.5, 1.5], [1, 4]);
// Virginica
// const testVal = tf.tensor2d([5.8,2.7,5.1,1.9], [1, 4]);
const prediction = model.predict(testVal);
const pIndex = tf.argMax(prediction, axis=1).dataSync();
const classNames = ["Setosa", "Virginica", "Versicolor"];
// alert(prediction)
alert(classNames[pIndex])
}
run();
一块块分析一下。
读取文件
const csvUrl = 'iris.csv';
const trainingData = tf.data.csv(csvUrl, {
columnConfigs: {
species: {
isLabel: true
}
}
});
TensorFlow.js提供了很方便的读取csv文件功能。
csv文件有sepal_length、sepal_width、petal_length、petal_width、species五列。前四个都是花的属性,为浮点数;最后一个是表示品种,有Setosa、Virginica、Versicolor三种品种。
因此,这里将species这一列设置为标签,就完成了训练数据的读取。
标签转成one-hot码
one-hot码是分类问题在训练时替代标签用的方案,这样做的原因在于可以更好地表示不同的分类。
如果用0、1、2表示三个不同的品种,0和2之间的欧氏距离2与0和1之间的欧氏距离1是不相等的,但实际上三个品种是完全不同的,0和1与0和2之间的不同程度应该是相等的才对。因此,引入one-hot编码,引入三个二进制位,100、010、001表示不同的分类,而这三个类各自之间的欧氏距离都是 2 \sqrt{2} 2,这就解决了类与类之间的表示问题。
const numOfFeatures = (await trainingData.columnNames()).length - 1;
const numOfSamples = 150;
const convertedData =
trainingData.map(({xs, ys}) => {
const labels = [
ys.species == "setosa" ? 1 : 0,
ys.species == "virginica" ? 1 : 0,
ys.species == "versicolor" ? 1 : 0
]
return{ xs: Object.values(xs), ys: Object.values(labels)};
}).batch(10);
特征数就是去除标签后的列数,然后将标签转成one-hot码,这里就用了一个条件表达式巧妙地完成了这个任务。
batch是在将训练数据分块,这里设置是10个一块。
构建网络并训练
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [numOfFeatures], activation: "sigmoid", units: 5}))
model.add(tf.layers.dense({activation: "softmax", units: 3}));
model.compile({loss: "categoricalCrossentropy", optimizer: tf.train.adam(0.06)});
await model.fitDataset(convertedData,
{epochs:100,
callbacks:{
onEpochEnd: async(epoch, logs) =>{
console.log("Epoch: " + epoch + " Loss: " + logs.loss);
}
}});
这个网络稍微复杂一点,2层深度,输入层当然就是按照特征数进行输入;隐藏层中有5个神经元;最后输出层是3个神经元,因为花是分3类的,所以softmax会计算三类各自的概率。
这边损失函数用的是交叉熵,优化器则选取了Adam优化器。
进行了100轮训练。
预测
// Setosa
const testVal = tf.tensor2d([4.4, 2.9, 1.4, 0.2], [1, 4]);
// Versicolor
// const testVal = tf.tensor2d([6.4, 3.2, 4.5, 1.5], [1, 4]);
// Virginica
// const testVal = tf.tensor2d([5.8,2.7,5.1,1.9], [1, 4]);
const prediction = model.predict(testVal);
const pIndex = tf.argMax(prediction, axis=1).dataSync();
const classNames = ["Setosa", "Virginica", "Versicolor"];
// alert(prediction)
alert(classNames[pIndex])
这里就将一行四列的数据作为输入,然后预测结果将是三个种类分别的概率,取其中的最大值作为输出即可。
参考链接
- https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Statements/async_function