(2020.04) Review: YOLOv4: Optimal Speed and Accuracy of Object Detection

很久没写长博文了, 试着找回青春的感觉, 跟以前懵懂时光相比自我感觉有了很大的进步,现在码字的时候会提前安排好思路跟布局,会更加关注系统性,追本溯源;面对一些新鲜的知识也懂得了引用, 方便以后再次复习阅读。回想最初只是翻译题目+粘贴代码, 现在更佳珍惜每一次写作的机会,每写一篇就是对自我的总结。
当所有人以为Joseph Redmon会带着YOLO一起退出AI界的时候, 历史的车轮似乎并不愿意停下,,只是换了一位大佬而已,,这不YOLO v4作为单阶段的集大成模型传来喜讯。 大家再也不用到处去找调参模型了, “我”把所有最优的模型都调过了,你们都来参照我的实验。
YOLO V41是2020年4月份新挂在Arxiv上的论文, 目前还未得知投稿了什么会议,但是非常值得学习,也很佩服作者的实践能力。 向大佬学习。
那么讲到目标检测, 我也想顺着paper的思路, 先复习一下目标检测的背景和经典模型。
背景介绍
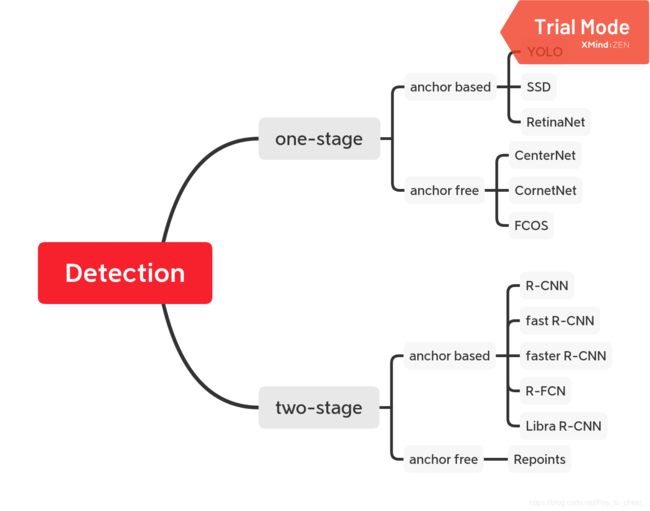
提到目标检测, 大家都知道分为one-stage和two-stage(anchor free也可以划分到这两个分类)。
在two-stage中, 主要有R-CNN系列,最近的R-FCN, Libra R-CNN, 不过19年的TridenNet, Cascade R-CNN这些最新的文章中没有提及,应该是取了比较有代表性的工作。
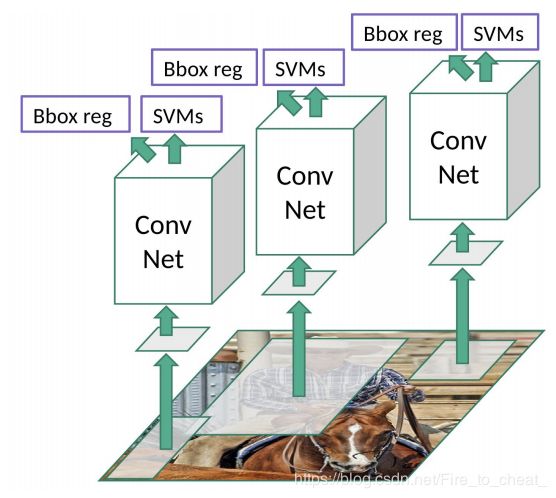
R-CNN的思路是通过Selective Search提取2000个proposals,然后将2000个proposal patch原图输入到CNN提取特征,再对每一张patch都做box regression和SVM分类。

Fast RCNN的思路是将原图首先提取feature后, 再针对feature去proposals, 得到的proposals再通过ROI Pooling reshape到一定的size,最后把ROI Pooling后的feature用于classification和regression。

-
R-FCN
-
Libra R-CNN
-
EfficientDet
-
TridenNet
-
Repoints
在one-stage中, 主要有YOLO系列,SSD,以及RetinaNet, 从anchor-free角度来讲, 19年还新出了cornerNet, centerNet, 以及FCOS。
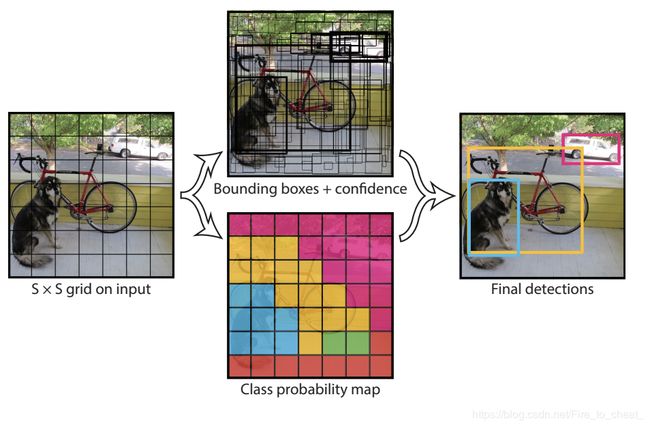
YOLO的思想是one-stage, 不需要提前生成proposal, 而是将图片划分为S*S的网格, 然后每一个网格取bounding box, 最后将取到的bounding box用于网络最后的classification和regression。
SSD
YOLO V2
YOLO V3
RetinaNet
-
CenterNet
-
RepPoints
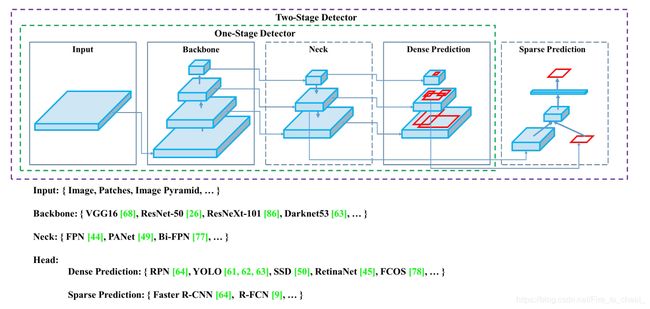
按照paper的思路, 如Figure2中,作者把Detection模型分为了四个sub-model: Input, Backbone, Neck, Head。 下面就根据这四个子模型来展开。
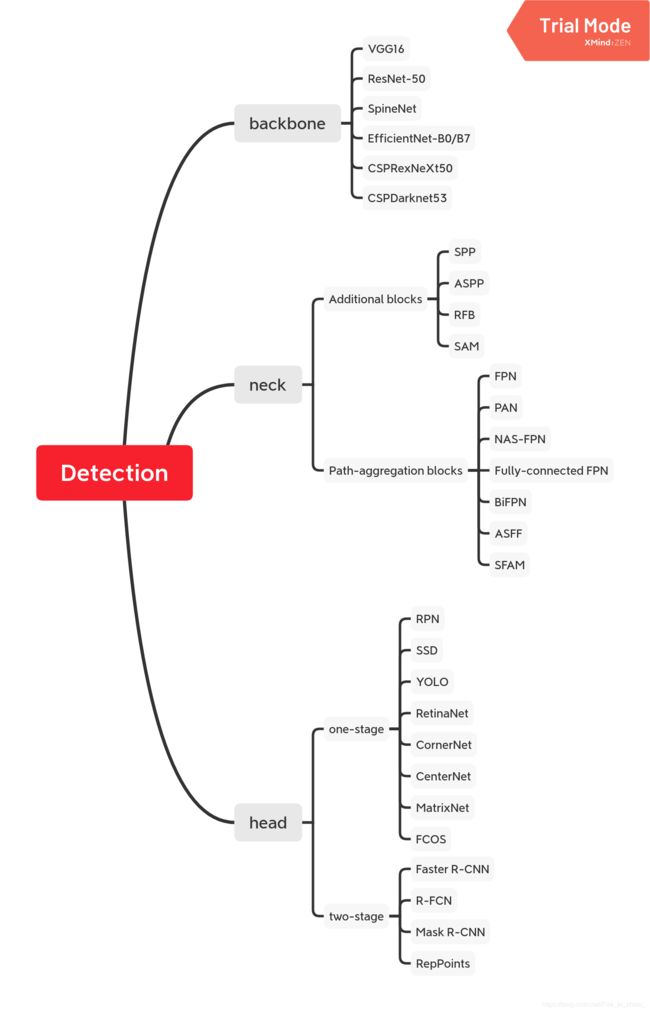
在backbone的选择上, 目前很多时候都是根据classification任务的结果来选择当前最优的模型,paper中主要列举了VGG,Resnet,EfficientNet,CSPRenext,CSPDarknet等,下面简单回溯一下最近的几个backbone,也是paper中用作比较的3个backbone。
-
EfficientNet
-
CSPRenext
-
CSPDarknet
-
HRNet
[EfficientNet/ SpineNet / CSPNet ref]
连接backbone和head的部分,paper中称之为Neck。neck的选择上分为Additional blocks和Path-aggregation block。如字面所言, Additional blocks的主要有SPP, ASPP,FRB,SAM; Path-aggregation block主要有FPN,PAN,NAS-FPN,Fully-connected FPN,Bi-FPN ,ASFF,SFAM。
这里我也针对最近的几个结构做简单展开:FRB,SAM;Bi-FPN,ASFF,SFAM。
-
RFB
-
SAM
-
FPN
-
PAN
-
NAS-FPN
-
BiFPN
-
ASFF
-
SFAM
Skills
Detection发展这么多年以来,各种skill和skill层出不穷,paper中将这些skill分为Bag of freebies和 Bag of specials; 前者表示在训练阶段增加额外的消耗,后者表示在测试阶段增加额外的参数。我个人观点这应该是来源于Bag of Freebies for Training Object Detection Neural Networks 2。
Bag of freebies

data augmentation
- random erase
- CutOut
- hide-and-seek
- grid-mask
- dropout/dropblock/dropconnect
- mixup
- cutmix
- style transfer GAN
- fmix(paper中未提)
data imbalance
- hard negative example mining
- online hard example mining
- focal loss
- label smoothing
- knowledge distillation
bounding box regression
- MSE
- IOU loss
- GIOU loss
- DIOU loss
- CIOU loss
Bag of specials

enhance receptive field
- SPP
- ASPP
- RFB
attention module
- SE
- SAM
feature integration
skip connection or hyper-column
- SFAM
- ASFF
- BiFPN
good activation function
- ReLU
- LReLU
- PReLU
- ReLU6
- SELU
- Swish
- hard-Swish
- Mish
post-processing
- NMS
- greedy NMS
- soft NMS
- DIoU NMS
YOLO V4 Network

怎么选择网路结构?
Finally, we choose CSPDarknet53 backbone, SPP additional module, PANet path-aggregation neck, and YOLOv3
(anchor based) head as the architecture of YOLOv4.
怎么选择BoF和BoS?
还能做的提升工作?
YOLO V4 最终版本

总结
Ref
YOLOv4: Optimal Speed and Accuracy of Object Detection [paper] ↩︎
Bag of Freebies for Training Object Detection Neural Networks [paper] ↩︎