【Python 笔记(3)】Python函数和函数式编程
详解 Python 函数和函数式编程
文章目录
- 1. 什么是函数?
- 1.1 函数 vs 过程
- 1.2 返回值与函数类型
- 2. 调用函数
- 2.1 函数操作符
- 2.2关键字参数
- 2.3 默认参数
- 2.4 参数组
- 3. 创建函数
- 3.1 def 语句
- 3.2 声明与定义比较
- 3.3 前向引用
- 3.4 函数属性
- 3.5 内部/内嵌函数
- 3.6 函数(与方法)装饰器
- 4. 传递函数
- 5. Formal Arguments
- 5.1 位置参数
- 5.2 默认参数
- 6. 可变长度的参数
- 6.1 非关键字可变长参数(元祖)
- 6.2 关键字变量参数(字典)
- 6.3 调用带有可变长参数对象函数
- 7. 函数式编程
- 7.1 匿名函数与 lambda
- 7.2 内建函数 apply()、filter()、map()、reduce()
- 7.3 偏函数应用
- 8. 变量作用域
- 9. 递归
1. 什么是函数?
函数是对程序逻辑进行结构化或过程化的一种编程方法。
函数定义的方法:
def foo():
print('bar')
1.1 函数 vs 过程
函数和过程两者都是可以被调用的实体。但是传统意义上的函数或者“黑盒”,可能不带任何输入参数,经过一定的处理,最后向调用者传回返回值。其中一些函数则是布尔类型的,返回一个“是”或者“否”的回答,更确切地说,一个非零或者零值。而过程是简单、特殊、没后返回的函数。
python 的过程就是函数,因为解释器会隐式地返回默认值 None。
1.2 返回值与函数类型
函数会向调用者返回一个值,而实际编程中大部分偏函数更接近过程,不显示地返回任何东西。在 python 中,无返回值的函数返回对象类型是 none。
下面 hello() 函数的行为就像一个过程,没有返回值。如果保存了返回值,该值为 None:
>>> def hello():
... print('hello world')
...
>>> res = hello()
hello world
>>> res
>>> print(res)
None
>>> type(res)
<class 'NoneType'>
另外,与其他大多数的语言一样,python 里的函数可以返回一个值或者对象。只是在返回一个容器对象的时候有点不同,看起来像是能返回多个对象。
def foo():
return ["xyz", 1000000, -98.6]
def bar():
return 'abc', [42, 'python'], "Guido"
>>> type(foo())
<class 'list'>
>>> type(bar())
<class 'tuple'>
foo() 函数返回一个列表,bar() 函数返回一个元祖。由于元祖语法上不需要一定带上圆括号,所以让人真的以为可以返回多个对象。如果我们要恰当地给这个元祖加上括号,bar() 的定义看起来会是这样:
def bar():
return ('abc', [42, 'python'], "Guido")
从返回值的角度来考虑,可以通过很多方式来存储元祖。接下来的3种保存返回值得方式是等价的:
>>> aTuple = bar()
>>> x, y, z = bar()
>>> (a, b, c) = bar()
>>>
>>> aTuple
('abc', [42, 'python'], 'Guido')
>>> x, y, z
('abc', [42, 'python'], 'Guido')
在对 x、y、z 和 a、b、c 的赋值中,根据值返回的顺序,每个变量会接收到与之对应的返回值。而 aTuple 直接获得函数隐式返回的整个元祖。
简而言之,当没有显式地返回元素或者如果返回 None 时,python 会返回一个 None。如果函数返回一个对象,那么调用者接收的就是 python 返回的那个对象,且对象的类型仍然相同。如果函数返回多个对象,python把他们聚集起来并以一个元祖返回。是的,尽管我们声称 Python 比诸如 C 那样只允许返回一个返回值得语言灵活得多,但老实说,Python 也是遵循了相同的传统,只是让程序员误以为可以返回多个对象。
| 返回的对象的数目 | Python 实际返回的对象 |
|---|---|
| 0 | None |
| 1 | object |
| >1 | tuple |
2. 调用函数
2.1 函数操作符
同大多数语言相同,我们用一对圆括号调用函数。实际上,有些人认为(())是一个双字符操作符。正如你可能意识到的,任何输入的参数都必须放置在括号中。作为函数声明的一部分,括号也会用来定义那些参数。在 Python 中,参数的操作符同样用于类的实例化。
2.2关键字参数
关键字参数的概念仅仅针对函数的调用。这种理念是让调用者通过函数调用中的参数名字来区分参数。这样规范允许参数缺失或者不按顺序,因为解释器能通过给出的关键字来匹配参数的值。
def foo(x):
print(x)
标准调用
>>> foo(42)
42
>>> foo('bar')
bar
>>> y = 44
>>> foo(44)
44
关键字调用
>>> foo(x=42)
42
>>> foo(x='bar')
bar
>>> y = 44
>>> foo(x=y)
44
另外一个例子,net_conn()函数,需要两个参数 host 和 port:
def net_conn(host, port):
print('connect to', str(host) + ':' + str(port))
只要按照函数声明中参数定义的顺序,输入恰当的参数,自然就可以调用这个函数:
>> net_conn('kappa', 8080)
connect to kappa:8080
host 参数得到字符串‘kappa’,port 参数得到整型 8080,当然也可以不按照函数声明中的参数顺序输入,如下:
>>> net_conn(port=8080, host='chino')
connect to chino:8080
当参数允许“缺失”的时候,也可以使用关键字参数。这取决于函数的默认参数。
2.3 默认参数
详见 5.2 小节。
2.4 参数组
Python 同样允许程序员执行一个没有显式定义参数的函数,相应的方法是通过一个把元祖(非关键字参数)或字典(关键字参数)作为参数组传递给函数。详见 6. 节。
基本上,你可以将所有参数放进一个元祖或者字典中,仅仅用这些装有参数的容器来调用一个函数,而不必显式地将它们放在函数调用中:
func(*tuple_grp_nonkw_args, **dict_grp_ke_args)
其中的 tuple_grp_nonkw_args 是以元祖形式体现的非关键字参数组,dict_grp_kw_args 是装有关键字参数的字典。python 允许我们把变量放在元祖或字典里,并在没有显式地对参数进行逐个声明的情况下,调用函数。
实际上,我们也可以给出形参!这些参数包括标准的位置参数和关键字参数,所以在 Python 中允许的函数调用的完整语法为:
func(positional_grgs, keyword_args, *tuple_grp_nonkw_args, **dict_grp_ke_args)
例子 easyMath.py 是一个儿童算数游戏,可以随机选择算数加减法。我们通过函数 add(),sub()等价“+”“-”操作符,这两者都可以在 operator 模块中找到。接着我们生成一个参数列表(该列表只有2个参数,因为这些是二元操作符/运算)。接着选择任意的数字作为算子。因为我们没打算在这个程序的基础版本中支持负数,所以我们将两个数字的列表按从大到小的顺序排序,然后用这个参数列表和随机选择的算术操作符去调用相应的函数,最后获得问题的正确答案。
随机选择数字以及一个算术函数,显式问题,以及验证结果。在3次错误的尝试以后给出结果,等到用户输入一个正确的答案后便会继续运行。
easyMath.py
#!/usr/bin/env python
from operator import add, sub
from random import randint, choice
ops = {'+': add, '-': sub}
MAXTRIES = 2
def doprob():
op = choice('+-')
nums = [randint(1, 10) for i in range(2)]
nums.sort(reverse=True)
ans = ops[op](*nums) # ans = add(*nums) 或者 ans = sub(*nums) ,元祖非关键字参数组
pr = '%d %s %d=' % (nums[0], op, nums[1])
oops = 0
while True:
try:
if int(input(pr)) == ans:
print('correct')
break
if oops == MAXTRIES:
print('answer\n%s%d' % (pr, ans))
else:
print('incorrect... try again')
oops += 1
except (KeyboardInterrupt, EOFError, ValueError):
print('invalid input... try again')
def main():
while True:
doprob()
try:
opt = input('Again? [y]').lower()
if opt and opt[0] == 'n':
break
except (KeyboardInterrupt, EOFError):
break
if __name__ == '__main__':
main()
运行结果:
1 + 1=>? 2
correct
Again? [y]>? y
7 + 4=>? 11
correct
Again? [y]>? y
8 + 8=>? 16
correct
Again? [y]>? y
7 + 5=>? 9
incorrect... try again
7 + 5=>? 9
incorrect... try again
7 + 5=>? 9
answer
7 + 5=12
7 + 5=>? 19
answer
7 + 5=12
7 + 5=>? 12
correct
Again? [y]>? y
8 - 4=>? 4
correct
Again? [y]>? n
3. 创建函数
3.1 def 语句
函数是用 def 语句来创建的,语法如下:
def function_name(arguments):
"function_documentation_string"
function_body_suite
标题行由 def 关键字,函数的名字,以及参数的集合(如果有的话)组成。def 子句的剩余部分包括了一个虽然可选但是强烈推荐的文档子串和必须的函数体。
def function_name(who):
"returns a salutory string customized with the input"
return "Hello" + str(who)
3.2 声明与定义比较
在某些编程语言里,函数声明和函数定义区分开的。一个函数声明包括提供对函数名,参数的名字(传统上还有参数的类型),但不必给出函数的任何代码,具体的代码通常属于函数定义的范畴。
在声明和定义有区别的语言中,往往是因为函数的定义可能和其声明放在不同的文件中。Python 将这两者视为一体,函数的子句由声明的标题行以及随后的定义体组成。
3.3 前向引用
和其他高级语言类似,Python 也不允许在函数未声明之前,对其进行引用或者调用。我们下面给出几个例子看一下:
>>> def foo():
... print('in foo()')
... bar()
...
如果我们调用函数 foo(),肯定会失败,因为函数 bar() 还没有声明:
>>> foo()
in foo()
Traceback (most recent call last):
File "", line 1, in <module>
File "", line 3, in foo
NameError: name 'bar' is not defined
我们现在定义函数 bar(),在函数 foo() 前给出 bar() 的声明:
>>> def bar():
... print("in bar()")
...
>>> def foo():
... print("in foo()")
... bar()
...
现在我们可以安全的调用 foo(),而不会出现任何问题:
>>> foo()
in foo()
in bar()
事实上,我们甚至可以在函数 bar() 前定义函数 foo():
>>> def foo():
... print('in foo()')
... bar()
...
>>> def bar():
... print('in bar()')
...
太神奇了,这段代码可以非常好的运行,不会有前向引用的问题:
>>> foo()
in foo()
in bar()
这段代码是正确的,因为即使(在 foo()中)对 bar() 进行的调用出现在 bar() 的定义之前,但 foo() 本身不是在 bar() 声明之前被调用的。换句话说,我们声明 foo(),然后再声明 bar(),接着调用 foo(),但是到那时,bar() 已经存在了,所以调用成功。
注意 foo() 在没有错误的情况下成功输出了 foo()。名字错误是当访问没有初始化的标识符时才产生的异常。
3.4 函数属性
你可以获得每个 Python 模块、类和函数中任意的名称空间。你可以在模块 foo 和 bar 里都有名为 x 的一个变量,但是在将这两个模块导入你的程序后,仍然可以使用这两个变量。所以,即使在两个模块中使用了相同的变量名字,这也是安全的,因为句点属性标识对于两个模块意味了不同的命名空间,比如说,在这段代码中没有名字冲突:
import foo, bar
print(foo.x + bar.x)
函数属性是 Python 另外一个使用了句点属性标识并拥有名称空间的领域。
def foo():
'foo() -- properly created doc string'
def bar():
pass
bar.__doc__ = 'Oops, forgot the doc str above'
bar.version = 0.1
上面的 foo() 中,我们以常规的方式创建了我们的文档子串,比如,在函数声明后第一个没有复制的字串。当声明 bar() 时,我们什么都没做,仅用了句点属性标识类增加文档字串以及其他属性。我们可以接着任意地访问属性。下面是一个使用了交互解释器的例子(你可能已经发现,用内建函数 help() 显式会比用 __doc__ 属性更漂亮,但是你可以选择你喜欢的方式)。
>>> help(foo)
Help on function foo in module __main__:
foo()
foo() -- properly created doc string
>>> print(bar.version)
0.1
>>> print(foo.__doc__)
foo() -- properly created doc string
>>> print(bar.__doc__)
Oops, forgot the doc str above
注意我们是如何在函数声明外定义一个文档字串。然而我们仍然可以就像平常一样,在运行时刻访问它。然而你不能在函数的声明中访问属性。换句话说,在函数声明中没有 “self” 这样的东西让你可以进行诸如 __dict__[‘version’]=0.1的赋值。这是因为函数体还没有被创建,但之后你有了函数对象,就可以按我们在上面描述的那样方法来访问它的字典。另外一个自由的名称空间!
函数属性实在 2.1 中添加到Python 中的,你可以在 PEP232 中阅读到更多相关信息。
3.5 内部/内嵌函数
在函数体内创建另外一个函数(对象)是完全合法的。这种函数叫做内部/内嵌函数。因为现在 Python 支持静态地嵌套域(在2.1中引入但是到2.2时才时标准),内部函数实际上很有用的。内嵌函数对于较老的 Python 版本没有什么意义,那些版本中只支持全局和一个局部域。那么如何去创造一个内嵌函数呢?
最明显的创造内部函数的方法是在外部函数的定义体内定义函数(用 def 关键字),如:
def foo():
def bar():
print('bar() called')
print('foo() called')
bar()
foo()
bar()
我们将以上代码置入一个模块中,如 inner.py,然后运行,会得到如下输出:
foo() called
bar() called
Traceback (most recent call last):
File "inner.py", line 8, in <module>
bar()
NameError: name 'bar' is not defined
内部函数一个有趣的方面在于整个函数体都在外部函数的作用域(既是你可以访问一个对象的区域)之内。如果没有任何对 bar() 的外部引用,那么除了在函数体内,任何地方都不能对其进行调用,这就是在上述代码执行到最后看到异常的原因。
另外一个函数体内创建函数对象的方式是使用 lambda 语句。详见 7.1 小节。
如果内部函数的定义包含了在外部函数里定义的对象的引用(这个对象甚至可以是在外部函数之外),内部函数会变成被称为闭包(closure)的特别之物。详见 8.4 小节。
3.6 函数(与方法)装饰器
装饰器背后的主要动机源自Python面向对象编程。装饰器是在函数调用之上的装饰。这些装饰仅是当声明一个函数或者方法的时候,才会应用的额外调用。
装饰器的语法以@开头,接着是装饰器函数的名字和可选的参数。紧跟着装饰器声明的是被修饰的函数和装饰函数的可选参数。装饰器看起来会是这样:
@decorator(dec_opt_arga)
def func2Bdecorated(func_opt_args):
...
...
下面介绍装饰器背后的灵感!
当静态方法和类方法在2.2时被加入到Python中的时候,实现方法很笨拙:
class MyClass(object):
def staticFoo():
...
...
staticFoo = staticmethod(staticFoo)
(澄清一下,在那个发行版本,这不是最终地语法)
在这个类的声明中,我们定义了叫staticFoo()的方法。现在因为打算让它成为静态方法,省去了 self 参数。接着用staticmethod()内建函数来将这个函数转化为静态方法,但是在def staticFoo()后跟着staticFoo = staticmethod(staticFoo)显得多么的臃肿。使用装饰器可以用如下代码替换掉上面的:
class MyClass(object):
@staticmethod
def staticFoo():
...
...
此外,装饰器可以如函数一样“堆叠”起来,这里有一个更加普遍的例子,使用了多个装饰器:
@deco2
@deco1
def func(arg1, arg2, ...);
pass
这和创建一个组合函数是等价的。
def func(arg1, arg2, ...):
pass
func = deco2(deco1(func))
函数组合用数学来定义就像这样: ( g ⋅ f ) ( x ) = g ( f ( x ) ) (g \cdot f)(x) =g(f(x)) (g⋅f)(x)=g(f(x))。对于在Python中的一致性:
@g
@f
def foo():
...
...
与
foo = g(f(foo))
相同
- 有参数和无参数的装饰器
装饰器语法让人困扰的地方在于,什么时候使用带参数或不带参数的装饰器。
没有参数的情况:
@deco
def foo();
pass
非常地直接
foo = deco(foo)
跟着是无参数函数(如上面所见)组成。
然而,带参数的装饰器 decomaker():
@decomaker(deco_args)
def foo():
pass
需要自己返回以函数作为参数的装饰器。换句话说,decomaker() 用 deco_args 做了些事并返回函数对象,而该函数对象正是以 foo 作为其参数的装饰器。简单地说:
foo = decomaker(deco_args)(foo)
列出一个含有多个装饰器的例子,其中的一个装饰器带有一个参数:
@deco1(deco_arg)
@deco2
def func():
pass
这等价于:
func = deco1(deco_arg)(deco2(func))
-
什么是装饰器
现在我们知道装饰器实际就是函数。我们也知道它们接受函数对象。
但它们是怎么样处理那些函数的呢? -
装饰器举例
下面给出一个例子。这个例子通过显示函数执行的时间“装饰”了一个(没有用的)函数。这是一个“时戳装饰”。
这个装饰器(以及闭包)示范表明装饰器仅仅是用来“装饰”函数的包装,返回一个修改后的函数对象,将其重新赋值原来的标识符,并永久失去对原始函数对象的访问。
from time import ctime, sleep
def tsfunc(func):
def wrappedFunc():
print('[%s] %s() called' % (ctime(), func.__name__))
return func()
return wrappedFunc
@tsfunc
def foo():
pass
foo()
sleep(4)
for i in range(2):
sleep(1)
foo()
运行脚本,得到输出结果;
[Wed Jan 16 16:59:17 2019] foo() called
[Wed Jan 16 16:59:22 2019] foo() called
[Wed Jan 16 16:59:23 2019] foo() called
逐行解释
- 5 ~ 10行
在启动和模块导入代码之后,tsfunc()函数式一个显示何时调用函数的时戳的装饰器。它定义了一个内部的函数wrappedFunc(),该函数增加了时戳以及调用了目标函数。装饰器的返回值是一个包装了的函数。 - 12 ~ 21行
用空函数题(什么都不做)来定义了foo()函数并用tsfunc()来装饰。为证明我们的设想,立刻调用它,然后等待4秒,然后在调用两次,并在每次调用前暂停1每秒。
- 无参数装饰器对比试验
print('------ flag: 0 ------\n')
def decofunc1(func):
"""
:param func: a function object
:return: a function object
"""
print('%s() called' % func.__name__)
return func
print('\n------ flag: 1 ------\n')
def decofunc2(func):
"""
:param func: a function object
:return: a function object
"""
def wrappedFunc():
print('%s() called' % func.__name__)
return func()
return wrappedFunc
print('\n------ flag: 2 ------\n')
@decofunc1
def foo1():
print('foo1')
pass
print('\n------ flag: 3 ------\n')
@decofunc2
def foo2():
print('foo2')
pass
print('\n------ flag: 4 ------\n')
foo1()
print('\n------ flag: 5 ------\n')
foo2()
print('\n------ flag: 6 ------\n')
foo1_ = decofunc1(foo1)
print('\n------ flag: 7 ------\n')
foo2_ = decofunc2(foo2)
print('\n------ flag: 8 ------\n')
foo1_()
print('\n------ flag: 9 ------\n')
foo2_()
print('\n------ flag:10 ------\n')
print('foo1 = foo1_?: %s' % str(foo1 == foo1_))
print('foo2 = foo2_?: %s' % str(foo2 == foo2_))
print('\n------ flag:11 ------\n')
输出结果如下:
------ flag: 0 ------
------ flag: 1 ------
------ flag: 2 ------
foo1() called
------ flag: 3 ------
------ flag: 4 ------
foo1
------ flag: 5 ------
foo2() called
foo2
------ flag: 6 ------
foo1() called
------ flag: 7 ------
------ flag: 8 ------
foo1
------ flag: 9 ------
wrappedFunc() called
foo2() called
foo2
------ flag:10 ------
foo1 = foo1_?: True
foo2 = foo2_?: False
------ flag:11 ------
4. 传递函数
在 Python 中可以用其他的变量来作为函数的别名。
因为所有的对象都是通过引用来传递的,函数也不例外。当对一个变量赋值时,实际是将相同对象的引用赋值给这个变量。如果对象时函数的话,这个对象所有的别名都是可调用的。
>>> def foo():
... print('in foo()')
...
>>> bar = foo
>>> bar()
in foo()
当我们把 foo 赋值给 bar 时,bar 和 foo 引用了同一个函数对象,所以能以和调用 foo() 相同的方式来调用 bar()。区分 “foo”(函数对象的引用)和 “foo()”(函数对象的调用)的区别。
我们甚至恶意把函数作为参数传入其他函数来进行调用。
>>> def bar(argfunc):
... argfunc()
...
>>> bar(foo)
in foo()
注意到函数对象 foo 被传入到 bar() 中。 bar() 调用了 foo() (用局部变量 argfunc 来作为其别名就如同在前面的例子中我们把 foo 赋给 bar 一样)。
研究 numConv.py。一个函数作为参数传递,并在函数体内调用这些函数。这个脚本用传入的转换函数简单将一个序列的数转化为相同的类型。特别地,test() 函数传入一个内建函数 int() 或 float()来执行转换。
numConv.py
#!/usr/bin/env python
def convert(func, seq):
"""conv. sequence of numbers to same type"""
return [func(eachNum) for eachNum in seq]
myseq = (123, 45.67, -6.2e8, 999999999)
print(convert(int, myseq))
print(convert(float, myseq))
[123, 45, -620000000, 999999999]
[123.0, 45.67, -620000000.0, 999999999.0]
5. Formal Arguments
Python 函数的形参集合由在调用时传入函数的所有参数组成,这参数与函数声明中的参数列表精确地配对。这些参数包括了所有必要参数(以正确的定位顺序来传入函数的)、关键字参数(以顺序或者不按顺序传入,但是带有参数列表中曾定义过的关键字)和所有含有默认值,函数调用时不必要指定的参数。(声明函数时创建)局部命名空间为各个参数值,创建了一个名字。一旦函数开始执行,就能访问这个名字。
5.1 位置参数
位置参数必须以在被调用函数体中定义的准确顺序来传递。另外,没有任何默认参数的话,传入函数(调用)的参数的精确地数目必须和声明的数字一致。
>>> def foo(who):
... print('Hello', who)
...
>>> foo()
Traceback (most recent call last):
File "", line 1, in <module>
TypeError: foo() missing 1 required positional argument: 'who'
>>>
>>> foo('World!')
Hello World!
>>>
>>> foo('Mr.', 'World!')
Traceback (most recent call last):
File "", line 1, in <module>
TypeError: foo() takes 1 positional argument but 2 were given
foo() 函数由一个位置参数。这意味着任何对 foo() 的调用必须有唯一的一个参数,不多,不少。否则你会频频看到 TypeError。Python 的错误具有强的信息性。作为一个普遍的规则,无论何时调用函数,都必须提供函数的所有位置参数。可以不按位置地将关键字参数传入函数,给出关键字来匹配其在参数列表中的何时的位置是被允许的。
由于默认参数的特性,他们是函数调用的可选部分。
5.2 默认参数
对于默认参数如果在函数调用时没有为参数提供值则使用预先定义的默认值。这些定义在函数声明的标题行中给出。C++ 也支持默认参数,和 Python 有同样的语法:参数名等号默认值。这个从语法上来表明如果没有值传递给那个参数,那么这个参数将取默认值。
Python 中默认值声明变量的语法是所有的位置参数必须出现在任何一个默认参数之前。
def func(posargs, defarg1=dval1, defarg2=dval2, ...):
"""function_documentation_string"""
function_body_suite
每个默认参数都紧跟着一个用默认值得赋值语句。如果在函数调用时没有给出值,那么这个赋值就会实现。
1. 为什么用默认参数
默认参数让程序的健壮性上升到极高的程度,因为它们补充了标准位置参数没有提供的一些灵活性。这种简洁极大的帮助了程序员。当少几个需要操心的参数时候,生活不再那么复杂。这在一个程序员刚接触到一个 API 接口时,没有足够的知识来给参数提供更对口的值时显得尤为有帮助。
使用默认参数的概念与在你的电脑上安装软件的过程类似。一个人会有多少次选择默认安装而不是自定义安装?我可以说可能几乎都是默认安装。这既方便、易于操作,又能节省时间。总是选择自定义安装的只是少数人。
另外一个让开发者受益的地方在于,开发者能更好地控制为顾客开发的软件。当提供了默认值得时候,他们可以精心选择“最佳”的默认值,所以用户不需要马上面对繁琐的选项。随着时间流逝,当用户对系统或者API越来越熟悉的时候,他们最终能自行给出参数。
举例:
>>> def taxMe(cost, rate=0.0825):
... return cost + (cost * rate)
...
>>> taxMe(100)
108.25
>>> taxMe(100, 0.05)
105.0
所有必需的参数都要在默认参数之前。因为它们是强制性的,但默认参数不是。从语法构成上看,对于解释器来说,如果允许混合模式,确定什么值来匹配什么参数是不可能的。如果没有按正确的顺序给出参数,将会报语法错误。
>>> def taxMe2(rate=0.0825, cost):
... return cost * (1.0 + rate)
...
File "" , line 1
SyntaxError: non-default argument follows default argument
再来看看 net_conn()。
def net_conn(host, port):
net_conn_suite
读者应该还记得,如果命名了参数,这里可以不按顺序给出参数。由于有了上述声明,我们可以做出如下(规则的)位置或者关键字参数调用:
net_conn('kappa', 8000)
net_conn(port=8080, host='chino')
然而,如果我们将默认参数引入这个等式,情况就会不同,虽然上面的调用仍然有效。让我们修改下 net_conn() 的声明以使端口参数有默认值80,在增加另外的名为 stype(服务器类型)默认值为 ‘tcp’ 的参数:
def net_conn(host, port=80, stype='tcp'):
net_conn_suite
我们已经扩展了调用 net_conn()的方式。以下就是所有对 net_conn()有效的调用:
net_conn('phaze', 8000, 'udp') # no def args used
net_conn('kappa') # both def args used
net_conn('chino', stype='icmp') # use port def arg
net_conn(stype='udp', host='solo') # use port def arg
net_conn('deli', 8080) # use stype def arg
net_conn(port=81, host='chino') # use stype def arg
在上面所有的例子中,一直不变的是:需要提供唯一的必须参数,host。host 没有默认值,所以他必须出现在所有对 net_conn()的调用中。关键字参数已经被证实能给不按顺序的位置参数提供参数,结合默认参数,它们同样也能被用于跳过缺失的参数。
2. 默认函数对象参数举例
grapWeb.py 脚本主要目的是从互联网上抓取一个 Web 页面并暂时储存到一个本地文件中用于分析的简单脚本。由于 download 函数的双默认参数允许用不同的 urls 或者指定不同的处理函数来进行覆盖,灵活性得到了提高。
#!/usr/bin/env python
from urllib.request import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage, encoding='gb18030', errors='ignore')
lines = f.readlines()
f.close()
print(firstNonBlank(lines), lines.reverse())
print(firstNonBlank(lines))
def download(url='https://cn.bing.com', process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download('https://cn.bing.com')
输出
<!DOCTYPE html><html lang="zh"><script type="text/javascript" >//<![CDATA[
None
//]]></script></html>
6. 可变长度的参数
可能会有需要用函数处理可变数量参数的情况。这时可使用可变长度的参数列表。变长的参数再函数声明中不是显示命名的,因为参数的数目在运行时之前都是未知的(甚至在运行的期间,每次函数调用的参数的数目也肯能是不同的),这和常规参数(位置和默认)明显不同,常规参数都是在函数声明中命名的。由于函数调用提供了关键字以及非关键字两种参数类型,Python 用两种方法来支持变长参数。
Python 在函数调用中使用 * 和 ** 来指定元祖和字典的元素作为非关键字以及关键字参数的方法。
6.1 非关键字可变长参数(元祖)
当函数被调用的时候,所有的形参(必须的未知参数和默认参数)都将值赋给了函数声明中相对应的局部变量。剩下的非关键字参数按顺序插入到一个元祖中便于访问。
可变长的参数元祖必须在位置和默认参数之后,带元祖(或者非关键字可变长参数)的函数普遍的语法如下:
def function_name([formal_args,] *vargs_tuple):
"function_documentation_string"
function_body_suite
* 号操作符之后的形参将作为元祖传递给函数,元祖保存了所有传递给函数的“额外”的参数(匹配了所有位置和具名参数后剩余的)。如果没有给出额外的参数,元祖为空。
正如我们先前看见的,只要在函数调用时给出不正确的函数参数数目,就会产生一个 TypeError 异常。通过末尾增加一个可变的参数列表变量,我们就能处理当超出数目的参数被传入函数的情形,因为所有的额外(非关键字)参数会被添加到参数元祖。由于和位置参数必须放在关键字参数之前一样的原因,所有的形式参数必须先于非正式的参数之前出现。
def tupleVarArgs(arg1, arg2='defaultB', *theRest):
'display regular args and non-keyword variable args'
print('formal arg 1:', arg1)
print('formal arg 2:', arg2)
for eachXtrArg in theRest:
print('anther arg:', eachXtrArg)
>>> tupleVarArgs('abc')
formal arg 1: abc
formal arg 2: defaultB
>>> tupleVarArgs(23, 4.56)
formal arg 1: 23
formal arg 2: 4.56
>>> tupleVarArgs('abc', 123, 'xyz', 456.789)
formal arg 1: abc
formal arg 2: 123
anther arg: xyz
anther arg: 456.789
6.2 关键字变量参数(字典)
在我们有不定数目的或者额外集合的关键字的情况中,参数被放入一个字典中,字典中键为参数名,值为相应的参数值。为什么一定要是字典呢?因为每个参数——参数的名字和参数值——都是成对给出,用字典来保存这些参数自然就是最合适不过了。
这里给出使用了变量参数字典来应对额外关键字参数的函数定义的语法:
def function_name([formal_args,][*vargst,][**vargsd]):
function_documentation_string
function_body_suite
为了区分关键字参数和非关键字参数,使用了双星号(**)。**是被重载了的以便不于幂运算发生混淆。关键字变量参数应该为函数定义的最后一个参数,带**。我们现在展示一个如何使用字典的例子:
def dictVarArgs(arg1, arg2='defaultB', **theRest):
"display 2 regular args and keyword variable args"
print('formal arg1:', arg1)
print('formal arg2:', arg2)
for eachXtrArg in theRest.keys():
print('Xtra arg %s: %s' % (eachXtrArg, str(theRest[eachXtrArg])))
>>> dictVarArgs(1220, 740.0, c='grail')
formal arg1: 1220
formal arg2: 740.0
Xtra arg c: grail
>>> dictVarArgs(arg2='tales', c=123, d='poe', arg1='mystery')
formal arg1: mystery
formal arg2: tales
Xtra arg c: 123
Xtra arg d: poe
>>> dictVarArgs('one', d=10, e='zoo', men=('freud', 'gaudi'))
formal arg1: one
formal arg2: defaultB
Xtra arg d: 10
Xtra arg e: zoo
Xtra arg men: ('freud', 'gaudi')
关键字和非关键字可变长参数都有可能用在同一个函数中,只要关键字字典是最后一个参数并且非关键字元祖先于它之前出现,正如在如下例子中的一样:
def newfoo(arg1, arg2, *nkw, **kw):
"display regular args and all variable args"
print('arg1 is:', arg1)
print('arg2 is:', arg2)
for eachNKW in nkw:
print('additional non-keyword arg:', eachNKW)
for eachKW in kw.keys():
print('additional keyword arg \'%s\': %s' % (eachKW, kw[eachKW]))
>>> newfoo('wolf', 3, 'projects', freud=90, gamble=96)
arg1 is: wolf
arg2 is: 3
additional non-keyword arg: projects
additional keyword arg 'freud': 90
additional keyword arg 'gamble': 96
6.3 调用带有可变长参数对象函数
我们介绍了在函数调用中使用 * 和 ** 来指定参数集合。接下来带着对函数介绍变长参数的些许偏见,我们会展示更多那种语法的例子。
我们现在将用在前面部分定义的,newfoo(),来测试新的调用语法。我们第一个对 newfoo() 的调用将会使用旧风格的方式来分别列出所有的参数,甚至跟在所有形式参数之后的变长参数:
>>> newfoo(10, 20, 30, 40, foo=50, bar=60)
arg1 is: 10
arg2 is: 20
additional non-keyword arg: 30
additional non-keyword arg: 40
additional keyword arg 'foo': 50
additional keyword arg 'bar': 60
我们现在进行相似的调用;然而,我们将非关键字参数放在元祖中将关键字参数放在字典中,而不是逐个列出变量参数:
>>> newfoo(2, 4, *(6, 8), **{'foo': 10, 'bar':12})
arg1 is: 2
arg2 is: 4
additional non-keyword arg: 6
additional non-keyword arg: 8
additional keyword arg 'foo': 10
additional keyword arg 'bar': 12
最终,我们将再另外进行一次调用,但是是在函数调用之外来创建我们的元祖和字典。
>>> aTuple = (6, 7, 8)
>>> aDict = {'z': 9}
>>> newfoo(1, 2, 3, x=4, y=5, *aTuple, **aDict)
arg1 is: 1
arg2 is: 2
additional non-keyword arg: 3
additional non-keyword arg: 6
additional non-keyword arg: 7
additional non-keyword arg: 8
additional keyword arg 'x': 4
additional keyword arg 'y': 5
additional keyword arg 'z': 9
注意到我们的元祖和字典参数仅仅是被调用函数中最终接收的元祖和字典的子集。额外的非关键字值 ‘3’ 以及 ‘x’ 和 ‘y’ 关键字对也被包含在最终地参数列表中,而它们不是 * 和 ** 的可变参数中的元素。
- 函数式编程举例
研究 testit() 函数。该模块给函数提供了一个执行测试的环境。testit() 函数使用了一个函数和一些参数,然后在异常处理的监控下,用给定的参数调用了那个函数。如果函数成功的完成,会返回 True 和函数的返回值给调用者。任何的失败都会导致 False 和异常的原因一同被返回。
#!/usr/bin/env python
def testit(func, *nkwargs, **kwargs):
try :
retval = func(*nkwargs, **kwargs)
result = (True, retval)
except Exception as diag:
result = (False, str(diag))
return result
def test():
funcs = (int, float)
vals = (1234, 12.34, '1234', '12.34')
for eachFunc in funcs:
print('_'*20)
for eachVal in vals:
retval = testit(eachFunc, eachVal)
if retval[0]:
print('%s(%s)= ' % (eachFunc.__name__, 'eachVal'), retval[1])
else:
print('%s(%s)= FAILED:' % (eachFunc.__name__, 'eachVal'), retval[1])
if __name__ == "__main__":
test()
单元测试函数 test() 在一个为4个数字的输入集合运行了一个数字转换函数的集合。为了确定这样的功能性,在测试中有两个失败的案例。这里是运行脚本的输出:
____________________
int(eachVal)= 1234
int(eachVal)= 12
int(eachVal)= 1234
int(eachVal)= FAILED: invalid literal for int() with base 10: '12.34'
____________________
float(eachVal)= 1234.0
float(eachVal)= 12.34
float(eachVal)= 1234.0
float(eachVal)= 12.34
7. 函数式编程
Python 不是也不大可能会成为一种函数式编程语言,但是它支持许多有价值的函数式编程语言的构建。也有些表现得像函数式编程机制但是从传统上也不能被认为是函数式编程语言的构建。
Python 提供以 lambda 表达式和四种内建函数的形式支持函数式编程。
7.1 匿名函数与 lambda
Python 允许用 lambda 关键字创造匿名函数。匿名是因为不需要以标准的方式来声明,比如说,使用 def 语句(除非赋值给一个局部变量,这样的对象也不会在任何的名称空间内创建名字)。然而,作为函数,它们也能有参数。一个完整的 lambda “语句”代表了一个表达式,这个表达式的定义体必须和声明放在同一行。我们现在来演示下匿名函数的语法:
lambda [arg2[, arg2, ... argN]]: expression
参数是可选的,如果使用参数的话,参数通常也是表达式的一部分。
核心笔记:lambda 表达式返回可调用的函数对象。
用合适的表达式调用一个lambda 生成一个可以像其他函数一样使用的函数对象。它们可被传入给其他函数,用额外的引用别名化,作为容器对象以及作为可调用的对象被调用(如果需要的话,可以带参数)。当被调用的时候,如过给定相同的参数的话,这些对象会生成一个和相同表达式等价的结果。它们和那些返回等价表达式计算值相同的函数是不能区分的。
在我们看任何一个使用lambda 的例子之前,我们意欲复习下单行语句,然后展示下lambda 表
达式的相似之处。
def true():
return True
上面的函数没有带任何的参数并且总是返回True。python 中单行函数可以和标题写在同一行。如果那样的话,我们重写下我们的true()函数以使其看其来像如下的东西:
def true(): return True
在整这个章节,我们将以这样的方式呈现命名函数,因为这有助于形象化与它们等价的 lamdba 表达式。至于我们的true()函数,使用lambda 的等价表达式(没有参数,返回一个True)为:
lambda :True
命名的 true() 函数的用法相当的明显,但lambda 就不是这样。我们仅仅是这样用,或者我们需要在某些地方用它进行赋值吗?一个lambda 函数自己就是无目地服务,正如在这里看到的:
>>> lambda :True
<function <lambda> at 0x000000E6A142D048>
在上面的例子中,我们简单地用lambda 创建了一个函数(对象),但是既没有在任何地方保存它,也没有调用它。这个函数对象的引用计数在函数创建时被设置为True,但是因为没有引用保存下来,计数又回到零,然后被垃圾回收掉。为了保留住这个对象,我们将它保存到一个变量中,以后可以随时调用。现在可能就是一个好机会。
>>> true = lambda :True
>>> true()
True
这里用它赋值看起来非常有用。相似地,我们可以把lambda 表达式赋值给一个如列表和元组的数据结构,其中,基于一些输入标准,我们可以选择哪些函数可以执行,以及参数应该是什么。(在下个部分中,我们将展示如何去使用带函数式编程构建的lambda 表达式。
def add(x, y): return x + y <==> lambda x, y: x + y
我们现在来设计一个带2 个数字或者字符串参数,返回数字之和或者已拼接的字符串的函数。我们先将展示一个标准的函数,然后再是其未命名的等价物。
默认以及可变的参数也是允许的,如下例所示:
def usuallyAdd2(x, y=2): return x + y <==> lambda x, y=2: x + y
def showAllAsTuple(*z): return z <==> lambda *z: z
看上去是一回事,所以我们现在将通过演示如何能在解释器中尝试这种做法,来努力着让你相信:
>>> a = lambda x, y=2: x + y
>>> a(3)
5
>>> a(3, 5)
8
>>> a(0)
2
>>> a(0, 9)
9
>>> b = lambda *z: z
>>> b(23, 'zyx')
(23, 'zyx')
>>> b(42)
(42,)
关于lambda 最后补充一点:虽然看起来lambdda 是一个函数的单行版本,但是它不等同于c++的内联语句,这种语句的目的是由于性能的原因,在调用时绕过函数的栈分配。lambda 表达式运作起来就像一个函数,当被调用时,创建一个框架对象。
7.2 内建函数 apply()、filter()、map()、reduce()
在这个部分中,我们将看看apply(),filter(), map(), 以及reduce()内建函数并给出一些如何使用它们的例子。这些函数提供了在python 中可以找到的函数式编程的特征。正如你想像的一样,lambda 函数可以很好的和使用了这些函数的应用程序结合起来,因为它们都带了一个可执行的函数对象,lambda 表达式提供了迅速创造这些函数的机制。
| 内建函数 | 描述 |
|---|---|
| apply(func[, nkw][, kw]) | 用可选的参数来调用func,nkw 为非关键字参数,kw 关键字参数;返回值是函数调用的返回值。 |
| filter(func, seq) | 调用一个布尔函数func 来迭代遍历每个seq 中的元素; 返回一个使func 返回值为ture 的元素的序列。 |
| map(func, seq1[,seq2…]) | 将函数func 作用于给定序列(s)的每个元素,并用一个列表来提供返回值;如果func None, func 表现为一个身份函数,返回一个含有每个序列中元素集合的n 个元组的列表。 |
| reduce(func, seq[, init]) | 将二元函数作用于seq 序列的元素,每次携带一对(先前的结果以及下一个序列元素),连续的将现有的结果和下雨给值作用在获得的随后的结果上,最后减少我们的序列为一个单一的返回值;如果初始值init 给定,第一个比较会是init 和第一个序列元素而不是序列的头两个元素。 |
1. *apply()
正如前面提到的, 函数调用的语法, 现在允许变量参数的元组以及关键字可变参数的字典, 在python1.6 中有效的摈弃了apply()。 这个函数将来会逐步淘汰,在未来版本中最终会消失。 我们在这里提及这个函数既是为了介绍下历史,也是出于维护具有applay()函数的代码的目的。
2. filter()
我们研究的第二个内建函数是filter()。想像下,去一个果园,走的时候带着一包你从树上采下的苹果。 如果你能通过一个过滤器,将包裹中好的苹果留下,不是一件很令人开心的事吗?这就是filter()函数的主要前提。给定一个对象的序列和一个“过滤”函数,每个序列元素都通过这个过滤器进行筛选, 保留函数返回为真的的对象。filter 函数为已知的序列的每个元素调用给定布尔函数。每个filter 返回的非零(true)值元素添加到一个列表中。返回的对象是一个从原始队列中“过滤后”的队列。
如果我们想要用纯python 编写filter(),它或许就像这样:
def filter(bool_func, seq):
filterred_seq = []
for eachItem in seq:
if bool_func(eachItem):
filtered_seq.append(eachItem)
return filtered_seq
一种更好地理解filter()的方法就是形象化其行为。
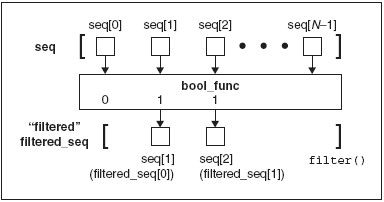
在图11-1 中,我们观察到我们原始队列在顶端, 一个大小为n 的队列,元素从eq[0], seq[1], . . . seq[N-1]。每一次对bool_func()的调用,举例来说,bool_func(seq[1]), bool_func(seq[0])等等,每个为True 或False 的的返回值都会回现。(因为Boolean 函数的每个定义–确保你的函数确实返回一个真或假)。如果bool_func()给每个序列的元返回一个真,那个元素将会被插入到返回的序列中。当迭代整个序列已经完成, filter()返回一个新创建的序列。我们下面展示在一个使用了filer()来获得任意奇数的简短列表的脚本。该脚本产生一个较大的随机数集合,然后过滤出所有的的偶数,留给我们一个需要的数据集。当一开始编写这个例子的时候,oddnogen.py 如下所示:
from random import randint
def odd(n):
return n % 2
allNums = []
for eachNum in range(9):
allNums.append(randint(1, 99))
print(list(filter(odd, allNums)))
代码包括两个函数:odd(), 确定一个整数是奇数(真) 或者 偶数(假)Boolean 函数,以及main(), 主要的驱动部件。main()的目的是来产生10 个在1 到100 之间的随机数:然后调用filter()来移除掉所有的偶数。最后,先显示出我们过滤列表的大小,然后是奇数的集合。
导入和运行这个模块几次后,我们能得到如下输出:
$ python oddnogen.py
[9, 33, 55, 65]
$ python oddnogen.py
[39, 77, 39, 71, 1]
$ python oddnogen.py
[23, 39, 9, 1, 63, 91]
$ python oddnogen.py
[41, 85, 93, 53, 3]
第一次重构
在第二次浏览时,我们注意到odd()是非常的简单的以致能用一个lambda 表达式替换:
from random import randint
allNums = []
for eachNum in range(9):
allNums.append(randint(1, 99))
print(list(filter(lambda n: n % 2, allNums)))
第二次重构
我们已经提到list 综合使用如何能成为filter()合适的替代者,如下便是:
from random import randint
allNums = []
for eachNum in range(9):
allNums.append(randint(1, 99))
print([n for n in allNums if n % 2])
第三次重构
我们通过整合另外的列表解析将我们最后的列表放在一起,来进一步简化我们的代码。正如你如下看到的一样, 由于列表解析灵活的语法,就不再需要一个暂时的变量了。(为了简单,我们用一个较短的名字将randint()导入到我们的代码中)。
from random import randint as ri
print([n for n in [ri(1, 99) for i in range(9)] if n % 2])
虽然比原来的长些, 但是这行扮演了该例子中核心部分的代码不再如其他人想的那么模糊不清。
3. map()
map()内建函数与filter()相似,因为它也能通过函数来处理序列。然而,不像filter(), map()将函数调用“映射”到每个序列的元素上,并返回一个含有所有返回值的列表。
在最简单的形式中,map()带一个函数和队列, 将函数作用在序列的每个元素上, 然后创建由每次函数应用组成的返回值列表。所以如果你的映射函数是给每个进入的数字加2,并且你将这个函数和一个数字的列表传给map(),返回的结果列表是和原始集合相同的数字集合,但是每个数字都加了2.
如果我们要用python 编写这个简单形式的map()如何运作的, 它可能像在图11-2 中阐释的如下代码:
def map(func, seq):
mapped_seq = []
for eachItem in seq:
mapped_seq.append(func(eachItem))
return mapped_seq
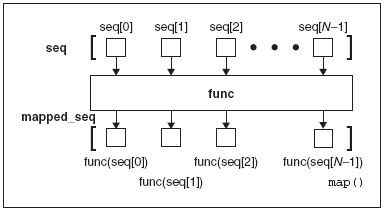
我们可以列举一些简短的lambda 函数来展示如何用map()处理实际数据:
>>> list(map((lambda x: x+2), [0,1,2,3,4,5]))
[2, 3, 4, 5, 6, 7]
>>> list(map((lambda x: x**2), range(6)))
[0, 1, 4, 9, 16, 25]
>>>
>>> [x+2 for x in range(6)]
[2, 3, 4, 5, 6, 7]
>>> [x**2 for x in range(6)]
[0, 1, 4, 9, 16, 25]
我们已经讨论了有时map()如何被列表解析取代, 所以这里我们再分析下上面的两个例子。形式更一般的map()能以多个序列作为其输入。如果是这种情况, 那么map()会并行地迭代每个序列。在第一次调用时, map()会将每个序列的第一个元素捆绑到一个元组中, 将func 函数作用到map()上, 当map()已经完成执行的时候,并将元组的结果返回到mapped_seq 映射的,最终以整体返回的序列上。图11-2 阐释了一个map()如何和单一的序列一起运行。如果我们用带有每个序列有N 个对象的M 个序列来的map(),我们前面的图表会转变成如图11-3 中展示的图表那样。
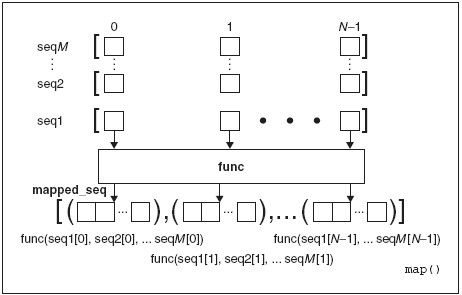
这里有些使用带多个序列的map()的例子。
>>> list(map(lambda x, y: x + y, [1, 3, 5], [2, 4, 6]))
[3, 7, 11]
>>> list(map(lambda x, y: (x + y, x-y), [1, 3, 5], [2, 4, 6]))
[(3, -1), (7, -1), (11, -1)]
在 Python2 中,使用map()和一个为None 的函数对象来将不相关的序列归并在一起。这种思
想在一个新的内建函数,zip,被加进来之前的 python2.0 是很普遍的。而zip 是这样做的:
>>> map(None, [1, 3, 5], [2, 4, 6])
[(1, 2), (3, 4), (5, 6)]
>>> zip([1, 3, 5], [2, 4, 6])
[(1, 2), (3, 4), (5, 6)]
4. reduce
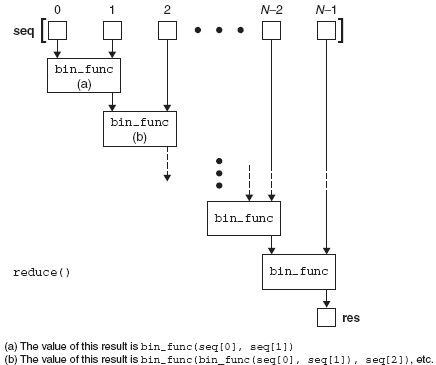
函数式编程的最后的一部分是reduce(),reduce 使用了一个二元函数(一个接收带带两个值作为输入,进行了一些计算然后返回一个值作为输出),一个序列,和一个可选的初始化器,卓有成效地将那个列表的内容“减少”为一个单一的值,如同它的名字一样。在其他的语言中,这种概念也被称作为折叠。
它通过取出序列的头两个元素,将他们传入二元函数来获得一个单一的值来实现。然后又用这个值和序列的下一个元素来获得又一个值,然后继续直到整个序列的内容都遍历完毕以及最后的值会被计算出来为止。
你可以尝试去形象化reduce 如下面的等同的例子:
reduce(func, [1, 2, 3]) = func(func(1, 2), 3)
有些人认为reduce()合适的函数式使用每次只需要仅需要一个元素。在上面一开始的迭代中,我们拿了两个元素因为我们没有从先前的值(因为我们没有任何先前的值)中获得的一个“结果”。这就是可选初始化器出现的地方(参见下面的init 变量)。如果给定初始化器, 那么一开始的迭代会用初始化器和一个序列的元素来进行,接着和正常的一样进行。
如果我们想要试着用纯python 实现reduce(), 它可能会是这样:
def reduce(bin_func, seq, init=None):
lseq = list(seq) # convert to list
if init is None: # initializer?
res = lseq.pop(0) # no
else:
res = init # yes
for item in lseq: # reduce sequence
res = bin_fun(res, item) # apply function
return res # return result
从概念上说这可能4 个中最难的一个, 所以我们应该再次向你演示一个例子以及一个函数式
图表(见图11-4)。reduce()的“hello world”是其一个简单加法函数的应用或在这章前面看到的
与之等价的lamda:
- def mySum(x,y): return x+y
- lambda x,y: x+y
给定一个列表, 我们可以简单地创建一个循环, 迭代地遍历这个列表,再将现在元素加到前
面元素的累加和上,最后当循环结束就能获得所有值的总和。
>>> def mySum(x, y): return x + y
...
>>> allNums = range(5) # [0, 1, 2, 3, 4]
>>>
>>> total = 0
>>> for eachNum in allNums:
... total = mySum(total, eachNum)
...
>>> print('the total is:', total)
the total is: 10
>>>
使用lambda 和reduce(),我们可以以一行代码做出相同的事情。Python3 将 reduce() 收进 functools 包里。
>>> from functools import reduce
>>> print('the total is:', reduce((lambda x, y: x + y), range(5)))
the total is: 10
给出了上面的输入,reduce()函数运行了如下的算术操作。
((((0 + 1) + 2) + 3) + 4) => 10
用list 的头两个元素(0,1),调用mySum()来得到1,然后用现在的结果和下一个元素2 来再次调用mySum(),再从这次调用中获得结果,与下面的元素3 配对然后调用mySum(),最终拿整个前面的求和和4 来调用mySum()得到10,10 即为最终的返回值。
7.3 偏函数应用
currying 的概念将函数式编程的概念和默认参数以及可变参数结合在一起。一个带 n 个参数,curried 的函数固化第一个参数为固定参数,并返回另一个带 n-1 个参数函数对象,分别类似于 LISP的原始函数 car 和 cdr 的行为。Currying 能泛化成为偏函数应用(PFA), 这种函数将任意数量(顺序)的参数的函数转化成另一个带剩余参数的函数对象。
在某种程度上,这似乎和不提供参数,就会使用默认参数情形相似。 在 PFA 的例子中, 参数不需要调用函数的默认值,只需明确的调用集合。你可以有很多的偏函数调用,每个都能用不同的参数传给函数,这便是不能使用默认参数的原因。
这个特征是在 python2.5 的时候被引入的,通过 functools 模块能很好的给用户调用。
简单的函数式例子
如何创建一个简单小巧的例子呢?我们来使用下两个简单的函数 add()和 mul(), 两者都来自operator 模块。这两个函数仅仅是我们熟悉的+和*操作符的函数式接口,举例来说,add(x,y)与 x+y一样。在我们的程序中,我们经常想要给和数字加一或者乘以 100
除了大量的,如 add(1,foo),add(1,bar),mul(100, foo), mul(100, bar)般的调用,拥有已存在的并使函数调用简化的函数不是一件很美妙的事吗?举例来说,add1(foo), add1(bar),mul100,但是却不用去实现函数 add1()和 mul100()?哦,现在用 PFAs 你就可以这样做。你可以通过使用 functional 模块中的 partial()函数来创建 PFA:
>>> from operator import add, mul
>>> from functools import partial
>>> add1 = partial(add, 1) # add1(x) == add(1, x)
>>> mul100 = partial(mul, 100) # mul100(x) == mul(100, x)
>>>
>>> add1(10)
11
>>> add1(1)
2
>>> mul100(10)
1000
>>> mul100(500)
50000
这个例子或许不能让你看到 PFAs 的威力,但是我们不得不从从某个地方开始。当调用带许多参数的函数的时候,PFAs 是最好的方法。使用带关键字参数的 PFAs 也是较简单的, 因为能显示给出特定的参数,要么作为 curried 参数,要么作为那些更多在运行时刻传入的变量, 并且我们不需担心顺序。下面的一个例子来自 python 文档中关于在应用程序中使用,在这些程序中需要经常将二进制(作为字符串)转换成为整数。
>>> baseTwo = partial(int, base=2)
>>> baseTwo.__doc__ = 'Convert base 2 string to an int.'
>>> baseTwo('10010')
18
这个例子使用了 int()内建函数并将 base 固定为 2 来指定二进制字符串转化。现在我们没有多次用相同的第二参数(2)来调用 int(),比如(‘10010’, 2),相反,可以只用带一个参数的新 baseTwo()函数。接着给新的(部分)函数加入了新的文档并又一次很好地使用了“函数属性”(见上面的11.3.4 部分),这是很好的风格。要注意的是这里需要关键字参数 base.
警惕关键字
如果你创建了不带 base 关键字的偏函数,比如, baseTwo- BAD = partial(int, 2),这可能会让参数以错误的顺序传入 int(),因为固定参数的总是放在运行时刻参数的左边, 比如baseTwoBAD(x) == int(2, x)。如果你调用它, 它会将 2 作为需要转化的数字,base 作为’10010’来传入,接着产生一个异常:
>>> baseTwoBAD = partial(int, 2)
>>> baseTwoBAD('10010')
Traceback (most recent call last): File "" , line 1, in <module>
TypeError: an integer is required
由于关键字放置在恰当的位置, 顺序就得固定下来,因为,如你所知,关键字参数总是出现在形参之后, 所以 baseTwo(x) == int(x, base=2).