MySQL优化二(索引、缓存、分区分表、慢查询日志)
索引
1.什么是索引?
正常查询数据表操作,需要遍历扫描整个表数据。
索引是一种结构,里面有相对应的算法。可以保证速度更快的查询出来。就是把建立索引的字段,单独存储起来,对应存储字段和对应的真实数据文件存储的物理地址。
比如:
公交站牌的上的站点数据,就是一个索引,可以帮助找到对应的站点信息
办公大楼的门牌索引,可以更快找到对应的公司办公地点
书的目录所记录的页数,也是一个索引,可以直接定位要找的内容
2 是否使用索引的差别
创造了一个1300000多万条数据的表
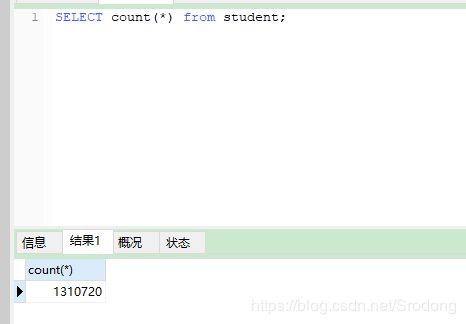
查询数据表里的信息,进行查看速度提示 此时无索引0.355s

然后给name字段加上索引 此时有索引0.041s 快了很多,效果明显
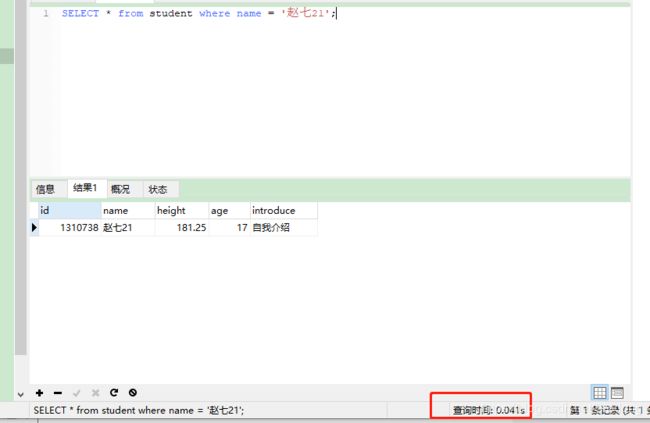
3 索引为什么速度快
索引会单独存储建立索引的字段,对应还存储一个字段信息所对应的真实数据的物理文件的地址记录位置。
通过建立字段索引的,字段进行查询,可以找到对应的数据的物理存储地址,然后直接通过物理地址进行找到需要找的数据,从而提高了查询速度。
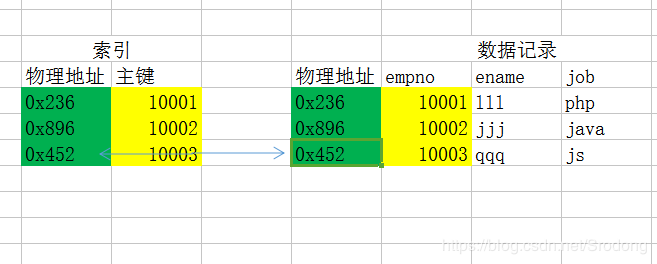
创建索引
索引类型:
主键索引 唯一性 配合自增 字段不允许为null 主键可以配合其他表建立外键操作
primary key
唯一索引 唯一性 字段可以为null
unique key
普通索引 key
全文索引 文本类型使用 char varchar text等 myisam支持 innodb引擎在5.6.4版本提供了对全文索引的支持(5.7支持中文)
fulltext key
复合索引(联合索引) 多个字段共同组合成为的索引
单一索引语法加上多个字段
前缀索引 前缀索引就是通过数据的字段的值的前几位,就可以单独区别出来这个值。可以把字段的前几位,进行索引的建立,而不需要把值的全部建立索引。节省空间,查询速度加快。
建立索引index和key的语法是等价的。索引方法有BTREE和HASH 默认为BTREE
给表建立索引一般有两种方式:
①在建立表结构的同时,进行索引的创建
create table 表名(
字段~~~~~~~~~
primary key (id),
unique index 名字(字段),
index 名字(字段),
index 名字(字段,字段), --复合索引
fulltext index 名字(字段);
)
②表结构已经创建,并且使用,通过表结构修改语句,进行索引的创建
alter table 表名
add primary key (id),
add unique index 名字(字段),
add index 名字(字段),
add index 名字(字段,字段), --复合索引
add fulltext index 名字(字段);
建立索引的时候,可以给索引一个名称,默认不给的话,就取字段名称为索引名称,复合索引取第一个字段。
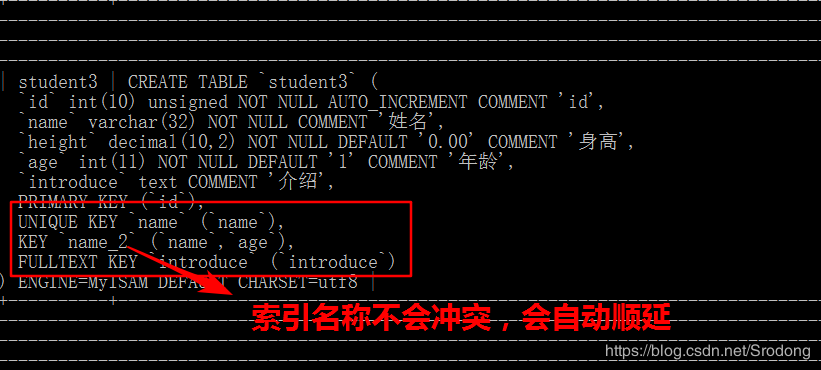
前缀索引的创建 假如给epassword创建前缀索引
第一步:通过过滤重复的epassword字段,进行查看需要建立索引的条数
mysql > select count(distinct epassword) from emp;
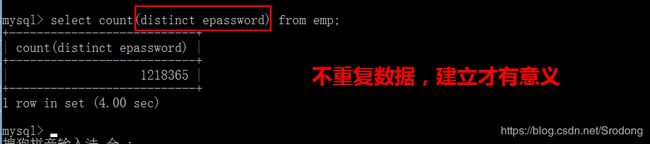
第二步:查看epassword前多少位,可以确定字段值的唯一性
mysql有可以截取字符串的函数,substring(str,start[1],位数),下标从1开始。
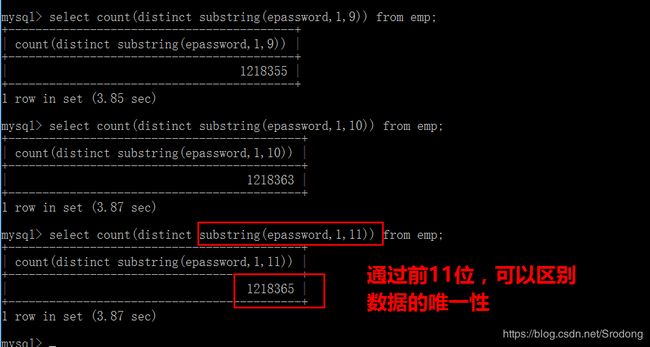
第三步:给前11位建立前缀索引
删除之前epassword建立的普通索引
mysql > alter table emp drop key epassword;
mysql > alter table emp add key pwd(epassword(11));
删除索引
删除索引的语法:
1)主键索引的删除
alter table 表名 drop primary key;
注意:删除主键索引需要先修改字段的自增属性
alter table 表名 modify id int unsigned not null comment 'id属性';
mysql > alter table student3 modify id int unsigned not null comment'id属性';
 2)非主键索引删除
2)非主键索引删除
alter table 表名 drop key名字, --唯一、普通、全文
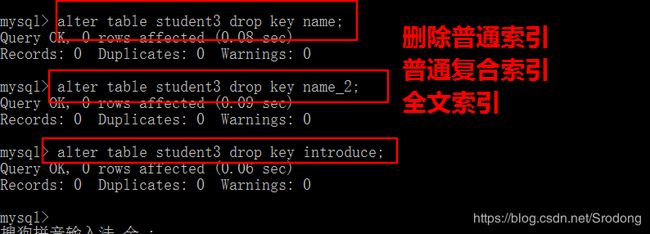
通过以上操作,student3表的字段的索引,就全部被删除掉了。
唯一删除区别就是主键索引,如果字段存在自增属性,需要先处理自增属性,再删除主键索引。
执行计划explain
增加索引可以提高数据查询的速度,很多时候虽然增加了索引,但是速度并什么提升。就有可能是索引没有被使用到。
mysql里有一个语法结构,explain预执行计划,实际没有执行,只是一个测试。
可以通过explain配置\G,来查看是否能够使用到索引,或者就是sql语句的执行情况,如果key为空就说明没有用到索引
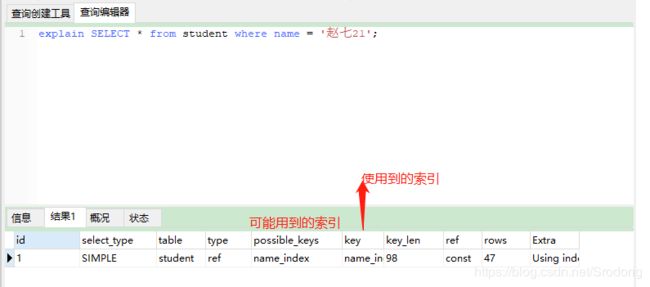
通过explain预执行计划,可以查看sql语句是否能够正常使用到索引,如果使用不到,说明索引建立的不合适,需要重新选择进行建立。
索引适合场合
1.通过where设置条件语句
2.order by时用到的字段
3.索引覆盖 (就是需要查询到的信息字段,正好是索引的字段,所以就可以直接把索引字段进行返回操作。不需要访问原始数据了。也被为“黄金索引”)
4.连表查询字段 连表条件关联的字段,增加索引也可以提高查询数据速度。
5.in条件查询 in查询条件,查询需要扫描整个表,所以可以增加索引提高查询效率。
索引原则
1.字段独立原则
字段不能够进行运算操作,是一个单独独立的字段名称,如果不是,就没有索引可用。
2.左原则
like查询 模糊查询 like “%00%” 左右模糊 like “1%” 左固定右模糊 like “%00” 右固定左模糊
左边固定才会使用到索引 like “1%”
3.最左前缀原则
复合索引使用,需要两个字段同时出现,或者第一个字段出现的时候,才有索引可以用。
非第一个字段单独出现,没有索引可用。
4.or原则
or的所有条件都有索引才会用上索引,如果只有一个条件建立了索引,索引不可用
索引结构
索引结构,可以保证数据更加快速的查询出来。
索引结构类型的分类:
聚集(聚合)型索引类型
非聚集(聚合)型索引类型
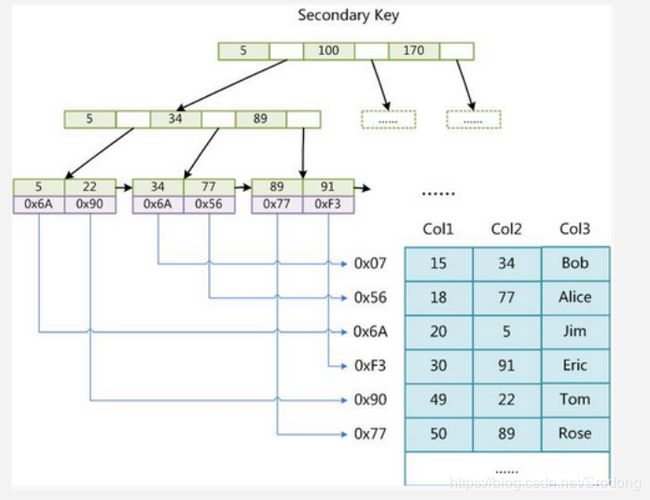
Myisam索引数据结构
Myisam 数据物理文件,存储结构 结构文件frm 数据文件 MYD 索引文件MYI
数据文件和索引文件,是分开独立的,这种结构模式,被称为非聚合索引。
1.主键索引的查询
查找顺序:主键索引=》物理存储地址=》真实数据

2.非主键索引的查询
非主键索引和主键索引,查找数据的顺序是类似的。
索引=》物理地址=》真实数据
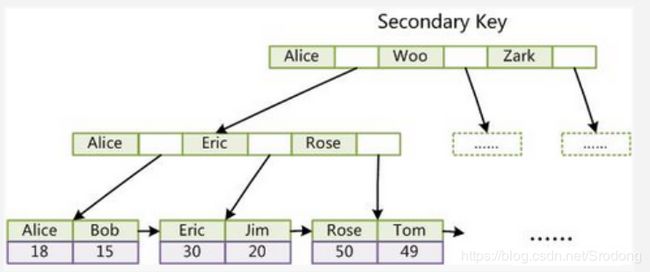
Innodb索引数据结构
innodb物理数据存储文件 结构文件frm ibd 数据和索引文件
innodb里的数据和索引在同一个文件,所以这种索引结构被称为:”聚合型索引”。
1.主键索引查询
非聚合索引,没有记录真实数据的物理地址,存储方式主键直接对应的是真实的数据得存储,所以可以查询到返回数据。

2.非主键索引查询
非聚合索引的非主键查询,需要先找到对应的主键,然后通过主键再查询到对应的真实数据
缓存
在优化mysql查询中,有很多时候,增加了索引效果也有可能是不明显,也有用不到索引情况。通过sql所查询的数据结果,每次数据不变化,但是查询很慢。每次都要查询一次,对于返回时间和系统性能都是一种压力和浪费。
可以使用mysql的缓存机制,把不经常变动的数据,但是执行起来又慢的sql查询到的数据结果进行缓存。
1.语法结构:
mysql > show variables like 'query_cache%'; //查看缓存状态
mysql > set global query_cache_size=64*1024*1024; //设置开启缓存,并设置缓存空间大小
windows下是修改my.ini linux下是修改my.cnf


2.缓存失效
如果数据表的数据和结构发生的了变化,那么之前生成的缓存数据结果,就失效了。会重新生成缓存。
写入、删除都算做表数据和结构发生了变化。
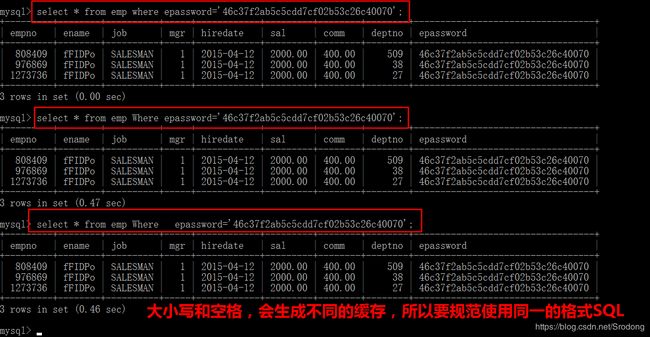
3.使用不到缓存的情况
sql语句大小写不同,中间有空格,随机条件等等,缓存会使用不到,因为生成的是不同的缓存内容,所以要用同一格式的sql



4.不使用缓存
还有特殊情况,就是主动要求,不使用缓存。使用语法结构 sql_no_cache
select sql_no_cache* from emp where epassword='46c3';
5.缓存按需使用
将参数 query_cache_type 设置成 DEMAND
这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定
select sql_cache * from emp where epassword='46c3';
6.缓存的其他使用
mysql>reset query cache 清空缓存
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
需要注意的是,MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说 8.0 开始彻底没有这个功能了。
分区分表
百万级别和千万级别的数据,一般增加索引使用缓存就可以有很多的速度提升,可以满足正常的使用需求。亿级别的数据,再进行查询的时候,因为数据实在太多,造成整个数据库表的活性降低。采取分区分表的操作,可以解决一部分的问题。
分区分表方法:1.逻辑分区分表 2.物理分表
四种格式的逻辑分表
逻辑分区表,有四种类型
key hash 取余算法 业务联系不紧密
range list 范围取值 业务联系紧密
逻辑分区表,需要在创建表的同时,进行表的分割。是逻辑上一个分割,并不是实际物理表的分割,所以在使用sql语句中和原来的单表使用是一样的。
逻辑分表操作,必须是主键或者是主键的一部分(复合主键)。
1 key分表
语法:
key求余:
create(
字段 类型
……
)
partition by key (字段) partitions 分区数目; 对于使用key partition 的方法,官方文档说是使用了一种password的方法.
CREATE TABLE goods (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT 'id' ,
`name` varchar(32) NOT NULL COMMENT '名称' ,
`price` decimal(10,2) NOT NULL DEFAULT 0.00 COMMENT '价格' ,
`create_time` datetime NOT NULL COMMENT '出厂时间' ,
PRIMARY KEY (`id`)
)ENGINE=InnoDB CHARACTER SET=utf8
PARTITION BY key(id) PARTITIONS 5;

插入数据
INSERT INTO goods VALUES(12,'huawei',5999.00,'2019-2-21 12:30:00');
INSERT INTO goods VALUES(13,'apple',6999.00,'2019-1-21 8:30:00');
INSERT INTO goods VALUES(14,'xiaomi',2999.00,'2019-3-21 12:00:00');
FLUSH table;
2 hash分表
hash求余:
create(
字段 类型
……
)
partition by hash(表达式) partitions 分区数目;
注意,再次提醒!!!!逻辑分表操作,必须是主键或者是主键的一部分(复合主键)
CREATE TABLE goods_HH (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT 'id' ,
`name` varchar(32) NOT NULL COMMENT '名称' ,
`price` decimal(10,2) NOT NULL DEFAULT 0.00 COMMENT '价格' ,
`create_time` datetime NOT NULL COMMENT '出厂时间' ,
PRIMARY KEY (`id`,create_time)
)ENGINE=InnoDB CHARACTER SET=utf8
PARTITION BY HASH (month(create_time)) PARTITIONS 12;3 range分表
Range条件:
create(
字段 类型
……
)
partition by range(字段/表达式) (
partition 名称1 values less than (常量),
partition 名称2 values less than (常量),
partition 名称3 values less than (常量),
);
CREATE TABLE goods_RR (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT 'id' ,
`name` varchar(32) NOT NULL COMMENT '名称' ,
`price` decimal(10,2) NOT NULL DEFAULT 0.00 COMMENT '价格' ,
`create_time` datetime NOT NULL COMMENT '出厂时间' ,
PRIMARY KEY (`id`,create_time)
)ENGINE=InnoDB CHARACTER SET=utf8
PARTITION BY range (year(create_time)) (
PARTITION hou00 values less than (2000),
PARTITION hou10 values less than (2010),
PARTITION hou20 values less than (2020)
);插入数据
INSERT INTO goods_RR VALUES(12,'huawei',5999.00,'1993-2-21 12:30:00');
INSERT INTO goods_RR VALUES(13,'apple',6999.00,'2009-1-21 8:30:00');
INSERT INTO goods_RR VALUES(14,'xiaomi',2999.00,'2019-3-21 12:00:00');
INSERT INTO goods_RR VALUES(14,'xiaomi',2999.00,'2029-3-21 12:00:00');
FLUSH table;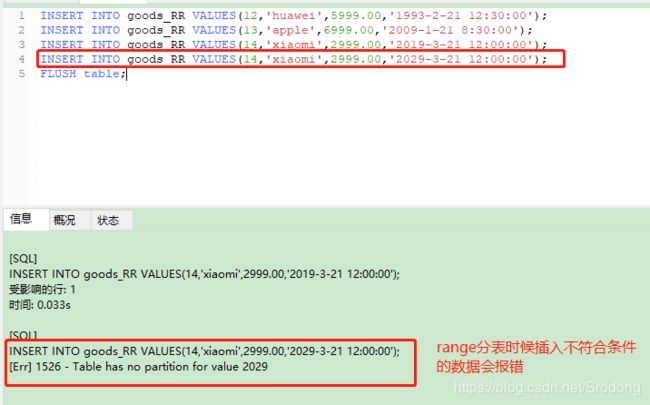
4 list分表
List条件:
create(
字段 类型
……
)
partition by list(字段/表达式) (
partition 名称1 values in (列表1),
partition 名称2 values in (列表2),
partition 名称3 values in (列表3),
);
CREATE TABLE goods_LL (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT 'id' ,
`name` varchar(32) NOT NULL COMMENT '名称' ,
`price` decimal(10,2) NOT NULL DEFAULT 0.00 COMMENT '价格' ,
`create_time` datetime NOT NULL COMMENT '出厂时间' ,
PRIMARY KEY (`id`,create_time)
)ENGINE=InnoDB CHARACTER SET=utf8
PARTITION BY list (month(create_time)) (
PARTITION spring values in (3,4,5),
PARTITION summer values in (6,7,8),
PARTITION autumn values in (9,10,11),
PARTITION winter values in (12,1,2)
);分表管理
求余(key/hash)分区:
增加:alter table 表名 add partition partitions 5;
减少:alter table 表名 coalesce partition 12;
以上情况不会影响原有数据,数据需要根据新的分区重新分配。不能删除最后一个分区
条件分区:
增加:
alter table 表名 add partition(
partition 名称 values less than (常量)
或
partition 名称 in (n,n,n)
);
减少:
alter table 表名 drop partition 分区名称;
业务联系紧密 删除分区,分区内部数据要丢失
物理分表设计
真实存在物理分表文件的,把数据分配到各个已经创建好的数据表。
物理分表方式:水平分割 垂直分割
1水平分表
把多条数据进行横向切割。
比如:
把id为1-800w条数据放在第一个表里,把id为800w-1000w数据放在第二个表里。
这个,单条数据是独立完整的。这个方式分表方式,被称作水平分表。
水平分表之后,需要代码程序觉得需要写哪个表,读哪个表。
2垂直分表
把数据表,进行竖向切割,把不太常用到的字段,分割到其他表(副表)。
比如:
用户表
id username password sex email qq hoppy ·········
问:登录功能,需要用到那些字段?
答:username id password字段,所以把常用字段,就放在一个表里,其他字段放在另外一个表里。
慢查询日志设置
当项目上线之后,会存在查询缓慢的情况,检测查询的sql语句,是否可以在规定时间返回数据。
如果sql语句执行时间,超过允许值,就被记录为慢查询,写到慢查询日志文件里。
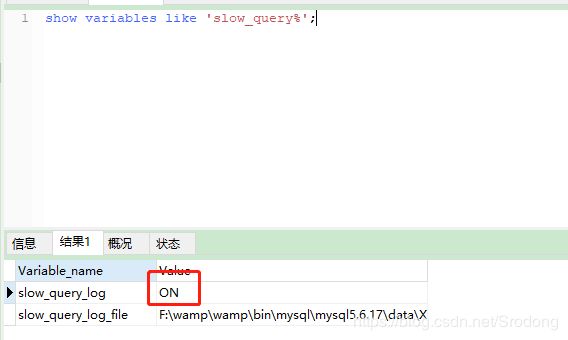
慢查询日志的开启、日志位置
mysql > show variables like 'slow_query%';
开启慢查询
mysql >set global slow_query_log = 1; 1为开启 0为关闭
slow_query_log_file 记录日志的文件名。
log_queries_not_using_indexes
这个参数设置为ON,可以捕获到所有未使用索引的SQL语句,尽管这个SQL语句有可能执行得挺快。
快慢时间临界点
mysql > show variables like 'long_query_time';
设置慢查询的时间阀值
mysql > set long_query_time = 1; sql执行超过1秒的就会被记录下来

慢查询日志的意义就在于,要收集执行慢SQL语句,并进行优化