第10-11周Python学习周记
&关于计划:
利用课余时间,对python进行三个并发进程式的学习:
1.阅读西瓜书(《机器学习》);
2.对于python相关库的学习(参考简书文档);
3.时间允许的话,尽可能了解一些身为程序员必要掌握的知识(例如json,参考于网络资源)。
&小结时间:第10~11周
&学习内容:
1.阅读了《机器学习》中第一章的《基本术语》部分;
2.关于切片(简化指定索引范围的索引操作):
a.
代码:
>>> eg=['apple','banana','pear']
>>> eg[:3]
['apple', 'banana', 'pear']
eg[:3]表示从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
b.从索引1开始,取出2个元素出来:
>>> eg[1:3]
['banana', 'pear']
c.从倒数第二个元素开始取值:
>>> eg[-2:]
['banana', 'pear']
d.可以通过切片轻松取出某一段数列:
首先创建一个0-99的数列:
>>> L = list(range(100))
>>> L
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
取前十个数:
>>> L[:10]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
取后十个数:
>>> L[-10:]
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
前十个数,每两个取一个:
>>> L[:10:2]
[0, 2, 4, 6, 8]
所有数,每五个取一个:
>>> L[::5]
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95]
3.关于Numpy(摘要):
a.关于随机生成数列:
>>> import numpy as np
>>> np.arange(60,80,5)
#以5为步从60到80(不包括80)间取 数,返回一个数组
array([60, 65, 70, 75])
>>> np.linspace(0,2,9)
#从0到2取9个数,返回一个数组
array([ 0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ])
b.关于矩阵乘积:
>>> a = np.array([[1,1],
... [0,1]])
>>> b = np.array([[2,0],
... [3,4]])
>>> a*b #元素级别乘积
array([[2, 0],
[0, 4]])
>>> a.dot(b) #矩阵乘积1
array([[5, 4],
[3, 4]])
>>> np.dot(a,b) #矩阵乘积2
array([[5, 4],
[3, 4]])
c.矩阵的转置:
>>> x = np.arange(16).reshape((4,4))
>>> x
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> np.transpose(x)
array([[ 0, 4, 8, 12],
[ 1, 5, 9, 13],
[ 2, 6, 10, 14],
[ 3, 7, 11, 15]])
d.数组的堆叠:
>>> x = np.arange(4).reshape((2,2))
>>> y = np.arange(4).reshape((2,2))
>>> x
array([[0, 1],[2, 3]])
>>> y
array([[0, 1],
[2, 3]])
>>> np.vstack((x,y)) #垂直堆叠
array([[0, 1],
[2, 3],
[0, 1],
[2, 3]])
>>> np.hstack((x,y)) #水平堆叠
array([[0, 1, 0, 1],
[2, 3, 2, 3]])
>>> x = np.arange(8)
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7])
>>> x[:,newaxis]
#利用newaxis将1D数组作为 列堆叠到2D数组中
array([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7]])
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7])
>>> y = x
>>> y
array([0, 1, 2, 3, 4, 5, 6, 7])
>>> np.column_stack((x,y))
#利用column_stack(将1D数组作 为列堆叠到2D数组中
array([[0, 0],
[1, 1],
[2, 2],
[3, 3],
[4, 4],
[5, 5],
[6, 6],
[7, 7]])
3.用requests模块从Web下载文件(参考网络资源进行学习)
A.用requests.get()函数下载一个网页:
>>> import requests
#requests.get()函数接收 一个要下载的URL字符串
>>> res = requests.get('http://www.gutenberg.org/cache/epub/1112/pg1112.txt')
>>> type(res)
#requests.get()函数返回 的是一个Response对象
>>> res.status_code == requests.codes.ok
#判断对这个网页的请求是否成功
True
>>> len(res.text) #下载的页面作为一个字 符串保存在Response 对象的text变量中
178981 #调用len函数查看其长度
该URL指向一个文本页面,其中包含整部罗密欧与朱丽叶,它是由古登堡计划提供的。
B.结合for循环和Response对象的iter_content()方法将下载的文件保存到硬盘
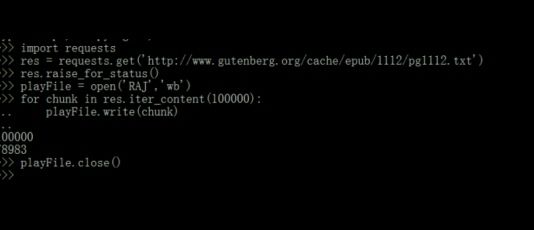

4.json模块:
a.用loads()函数读取JSON:
>>> sojd = '{"name":"Jack","isCat":true,"miceVaught":0}'
>>> import json
>>> jdapd = json.loads(sojd)
>>> jdapd
{'isCat': True, 'miceVaught': 0, 'name': 'Jack'}
b.用dumps函数写出JSON
>>> pd = jdapd
>>> pd
{'isCat': True, 'miceVaught': 0, 'name': 'Jack'}
>>> sojd1 = json.dumps(pd)
>>> sojd1
'{"isCat": true, "miceVaught": 0, "name": "Jack"}'