IBM MessageBroker笔记系列







数据库操作
配置MB的用户数据库
前面已经讲了在创建MB运行时实例时,配置数据库的基本过程了,但那里所指的数据库是MB自己运行时需要的数据库,用来存放诸如broker、执行组、消息流等的信息,而现在开发的企业应用程序,几乎没有不用到数据库来存放业务数据的,所以这里主要讲述如何配置“用户数据库”,也即你的应用程序使用的数据库。
下面以MB 6.1 + Oracle 10g 为例,介绍配置过程
一、 ODBC数据源
MB是通过ODBC来操作数据库的,因此首先要配置好操作系统本身的ODBC数据源。Windows中配置ODBC很容易,在此不赘述细节。需要注意的是,选择Oracle数据源驱动时,一定要选择下图所示的MB自带的Oracle驱动

我在创建ODBC时,一开始没有在本机安装Oracle,结果ODBC无法使用,报告“由于系统错误126,驱动程序无法加载”,问了IBM的技术支持也没有答案,后来干脆在本机安装了一个Oracle(不必运行),问题就解决了,估计MB自带的Oracle驱动还是要调用Oracle本身的一些库的。我对Oracle本身基本不懂,具体用到了哪些库也不清楚,就先这么用着了。
二、 数据库设置
这里顺手提一下Oracle本身的设置。当你新建了Oracle的ODBC数据源后,会发现数据源设置里面,没有IP和端口设置。我在网上搜了一下,最简单的方法是直接修改Oracle的tnsnames.ora文件,这个文件位于: $oracle_root/product/ 10.1.0 /db_1/NETWORK/ADMIN/tnsnames.ora 路径下,可以用记事本打开编辑。里面本身已经有样例了,参照着改很容易
三、 消息流节点
MB中能和数据库打交道的节点有很多,包括filter、compute,和专门的数据库节点,如下图:

基本上,凡是属性里面可以设置“数据源”的节点,都可以操作数据库。使用方法很简单,直接在“数据源”属性中填入操作系统的相应ODBC数据源名称即可。
四、 代理broker的设置
这是最后一处要设置的地方。前面的tns文件解决了ip和端口的问题,但是数据源本身的用户名和密码在消息流中并没有提及,其实这是通过MB的一个命令来设置的,格式如下:
mqsisetdbparms brokerName -n dataSourceName [-u dataSourceUserId] -p dataSourcePassword
具体用法可以输入 mqsisetdbparms /h 获得参考
配置完以上内容后,运行消息流应该不会有数据库连接的异常了。假如配置不正确,会在运行到使用了“数据源”的节点处抛出ODBC的一些异常
在WMBT中创建数据库项目
以上做的工作可以确保消息流能够正确操作用户数据库,但是当你在WMBT中编写SQL语句时,会出现很多警告,内容一般是“无法解析数据库表引用:某字段”。虽然不影响运行,但看着总是不太爽。
出现警告的原因很简单,你没有告诉WMBT你需要用到的数据库表的结构是什么,所以WMBT很尽职地告诉你可能有问题,我们只需引入数据库的定义,即可消除这些警告。
首先,打开“数据库资源管理器”视图,新建一个JDBC连接,和其他EclipseIDE类似,配置好相关参数即可。

在WMBT中新建一个“数据库定义”,向导会让你顺便创建一个“数据库设计项目”,你可以通过刚刚创建的JDBC连接,选择一个数据库,即可。
这时你会发现ESQL代码中那些烦人的提示已经消失了。
在ESQL中编写SQL语句
ESQL中使用SQL和一般的SQL语句基本一致,除了在指定哪个数据表的时候,要用类似下面的语法:
SELECT FROM Database.SchemaName.TableName
其中的“Database”是关键字,一定要有的,表示从数据库中读取,这是因为ESQL中不单可以操作数据库,还可以对逻辑树、数组对象使用select、delete等SQL语法,“Database”起到标识的作用。
给出这样一条语句:
set LocalEnvironment.temp[] = select * from Database.TEST.example
假设example有id和info两个字段,共三条记录,那么执行后的结果是LocalEnvironment 树下面产生三个temp元素,每个元素都包含一个id和info子元素,对应数据库的记录。
select返回的都是数组类型,因此不能set LocalEnvironment.temp = select ….,那样会在打包时报错,一定要标明是数组
此外,像上面那样直接书写SQL语句并赋值给一个数组变量,MB会在编译和执行期间检查SQL语法是否合格,这个特性虽然很有用,但有时候也会适得其反,比如要在Oracle使用序列来实现主键自增时,insert语句要写成:
insert into example (id,info) VALUES ( SEQ_EXAMPLE.nextval , ‘xxxxx’)
这篇是针对WebService的一些使用技巧
入门
MB对WebService的支持其实不是它的强项,它的长处在于MQ,MB就是基于MQ的,所谓“消息代理”,感觉就是在消息中间件基础上增加了“代理”功能。MB的前身是MQ Integrator,所以从字面意思上来看,也是“message -> integrator -> broker”,越来越复杂的功能。据说,Websphere ESB对于java和webservice的支持更加完善,不过我也没有用过。
扯了那么多,回到主题。在MB V6.0中,对WebService的支持还是比较弱的,以单纯的http节点,加上程序员在compute节点中手工操作消息树,包括对SOAP包进行封包(envelop)和解包(extract)都要自力更生,难度比较大,且不够直观简练,给人感觉是MB对webservice支持不够,不得已而为之。到了V6.1,情况终于有了较大的改观,MB提供专门的webservice节点了。
所以,如果你还在看《精通WMB》,那么webservice那一章可以先放下了,去WMBT的“样本库”,看看webservice的教程,会发现不仅仅有专门的SOAP节点,还对IBM的WSRR也有专门的支持,甚至还提供异步的SOAP节点。因此在MB中使用webservice,第一步推荐先去学这些样例。特别留意使用http和soap节点时,前后的compute节点的ESQL代码的差异,体会SOAP节点的方便。
技巧
看完SOAP节点的样例之后,会发现里面的那个子流,其实也挺复杂的,好像不比http节点简单
http节点
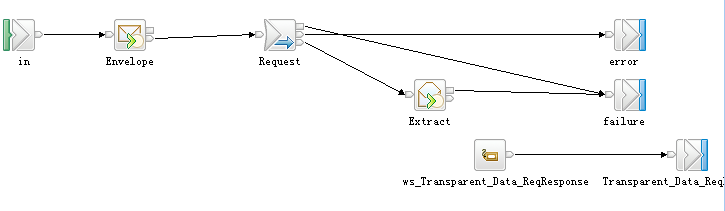
SOAP节点
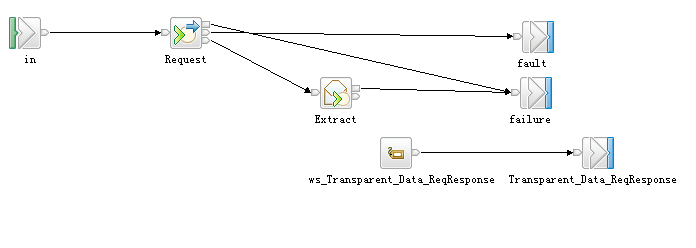
其实,Envelope和Extract节点是MB6.1才有的,没有他们,http节点构造webservcie会变得很啰嗦;另外,以上的流程图,是可以通过向导的方式生成的,这一点非常方便。
首先在消息集项目中,“从WSDL文件”新建一个消息定义;然后将这个WSDL文件拖到某个消息流的编辑界面中,自动弹出一个向导,简单地一步步走,就能生成以上的消息流。

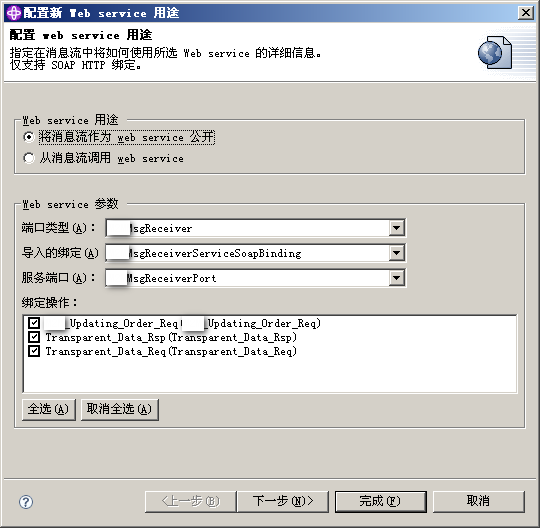
动态设置webservice地址
在以上生成的消息流中,HTTP节点和SOAP节点都有一个属性,用于指定webservice的请求地址,但这是写死在节点中的。如果要在运行过程中动态设置呢?比如根据消息内容,选择合适的URL地址进行webservice调用。
其实很简单,只需在SOAP或HTTP节点之前的某个compute节点中,在LocalEnvironment中设置一个相应的值即可
-
HTTP 节点:
SET OutputLocalEnvironment.Destination.HTTP.RequestURL = ‘webservice地址’
-
SOAP 节点:
set OutputLocalEnvironment.Destination.SOAP.Request.Transport.HTTP.WebServiceURL = ‘webservice地址’
注意,切记把compute节点的“计算方式”设置为“消息和LocalEnvironment”,总之至少要包括LocalEnvironment,否则设置了等于没设置,compute节点不会将LocalEnvironment往下传
当然,以上步骤也可以在 Filter 、 Database 这些节点做,那样就没有 Input 和 Output LocalEnvironment 之分了
本来这一篇要写ESQL的一些语法细节的,但是过几天就要去客户那里部署系统了,上周也花了一个礼拜时间,一边学linux,一边学怎么在linux上部署MB。所以这一篇先讨论如何在linux上安装、配置WMB
准备
先说一下硬件和操作系统环境:
机器:IBM的某型号刀片机, 4G 内存
操作系统:RED HAT LINUX 64bit企业版
业务数据库:Oracle 10g
WMB6.1,安装在WMQ6之上,使用DB2 9作为代理数据库
以上软件都是安装在同一台刀片机上
另外,WMBT6.1安装在我自己的windows机器上,用于开发MB程序,并远程部署到服务器上
参考资料
按理说参考资料应该是放在最后面的,只是我的这些安装心得都是来自这些参考资料,为防止我的个人经验误导读者的安装过程,所以先列出以下资料。有空慢慢看的话,还是应该以这些官方资料为准
《messagebroker_Configuration_Administration_and_Security》
这本是权威了,除了对应的版本有些旧(WMB 6.0),整体内容还是很详细的,几乎所有平台上的MB安装、配置都有详细的介绍。只是内容多得让人看起来眼晕。
MB info center
内容和上面那本书差不多,比较精炼,但如果配置出了问题,未必能找到详细的解答
最后,强烈建议,如果是linux菜鸟(像我这种),赶紧补习一些linux的基本知识,比如环境变量怎么设置
安装
其实安装过程还是比较简单的,先安装MQ,再安装MB。MQ比较麻烦一点,要用rpm,而MB则带有一个Eclipse的安装界面,和windows上和相似,跟着向导走就行了。安装好之后,会发现db2也随着MB一起装好了
默认安装路径(注意大小写):
MB:/opt/ibm/mqsi
DB2:/opt/ibm/db2
创建代理数据库
红皮书上已经有详细说明,我就偷个懒,copy并解释一下
1. Log on as root.
2. Create a database instance. Use the commands shown here for guidance for the different platforms.
a. On AIX:
/usr/lpp/db2_08_01/instance/db2icrt -u fence_userID username
b. On Linux, Solaris, or HP-UX:
/opt/IBM/db2/V8.1/instance/db2icrt -u fence_userID username
其实,fence_userID 和username我也不太清楚是什么,你可以参考红皮书,或者找个db2高手问问。反正我当时使用root创建是不行的,一定要选择其他帐号,比如你自己的用户名
3. Log on as username
4. Create a database (in this example called WBRKBKDB) using the following commands (on some platforms, an explicit path name is required). You must insert a space between the starting period and the tilde character in the first command shown here:
. ~/sqllib/db2profile
db2start
db2 create database WBRKBKDB
db2 connect to WBRKBKDB
db2 bind ~/sqllib/bnd/@db2cli.lst grant public CLIPKG 5
重点说明的是:. ~/sqllib/db2profile 这句命令,前面要有一个“.”和空格,否则没用。执行了这条命令后,如果你对db2命令不熟悉,可以直接敲入“db2cc”,启动db2的图形管理界面,在里面创建数据库,省去了敲命令的麻烦
最后一步,在某些平台上需要修改db2的DBHEAP属性,至少900,才能满足MB运行的需要,否则会造成性能低下。
配置ODBC连接
由于在64位机器上跑MB,所以ODBC DSN是要32位还是64位是很头疼的问题,因为不同硬件平台、操作系统的组合都有不同的要求。比如,在windows上是肯定没有64bit支持的,而在某些操作系统(貌似是AIX),即使你全部用64bit的产品,也要配置32bit的ODBC。具体的可以参考红皮书,里面有详细的列表,在这里我只针对我使用的平台介绍配置过程,在此特别声明,未必适用于读者的环境
总体思路:linux的ODBC是通过一个配置文件来描述的,在该配置文件中写入相应的信息,然后在环境变量中设置 ODBCINI=“配置文件的绝对路径”
编辑ODBC配置文件
1. 从你的MB安装目录下的ODBC64/V5.2 ,拷贝一份样例配置文件:odbc64.ini,到某个目录(比如mqm用户的根目录)
2. 修改该文件。在这里我只保留DB2和ORACLE的DSN,其他的统统删了
3. 修改你的odbc64.ini的权限:
Ensure that the odbc64.ini file has file ownership of mqm:mqbrkrs and has the same permissions as the supplied sample file.
4. 修改ODBCINI环境变量指向你的odbc64.ini
5. 修改linux的库路径:LD_LIBRARY_PATH,指向db2和oracle的32位和64位odbc链接库的路径,比如我的配置如下:
LD_LIBRARY_PATH=$ORACLE_BASE/lib32:$DB2_BASE/lib32:$DB2_BASE/lib64:${LD_LIBRARY_PATH}
6. 如前所述,我对使用32还是64bit的DSN也是有点混乱,干脆就把下面两个环境变量也加上,以防万一:
# for MB 64bit execution group
MQSI_LIBPATH64=/opt/ibm/db2/V9.1/lib64:${MQSI_LILPATH64}
# 32bit database lib may be needed
MQSI_LILPATH32=/opt/ibm/db2/V9.1/lib32:${MQSI_LILPATH32}
7. 最后是修改odbc64.ini文件的内容,具体的看书吧,下面是我的例子:
补充几点注意的地方:
1. DB2的driver是不用路径的,只写驱动名字即可
2. DB2的Database属性(即是数据库的名字),要和DSN的名字一样(即是方括号中的内容)
3. 没事不要打开trace,会很慢
创建MB的运行实例
准备工作
打开一个终端,运行命令之前,先输入:
. /opt/ibm/mqsi/6.1/bin/mqsiprofile
和前面的db2命令一样,开头要有“.”和“空格”
你可以把这句话加到linux用户根目录的“.bashrc”文件,那样每次打开终端都会自动执行这个脚本,以设置一些环境变量,否则你是无法使用MB命令的。
确保MQ和DB2都在运行
可以通过dspmq查看MQ组件的运行状态,如果队列管理器没有启动,则通过strmqm命令启动之。
按照前面介绍的方法,利用db2cc图形界面查看数据库是否运行,否则启动之;也可以用db2start命令,记得要切换用户到你创建db2时使用的帐号,比如:
su db2usr –c “db2start”
创建配置管理器
mqsicreateconfigmgr ConfigMgr -i root -a xxxxx -q QM
创建代理
mqsicreatebroker BRK1 -i root -a xxxxx -q QM -n BRK1_DB -u db2usr -p xxxxx
创建代理时,要指定代理数据库的DSN名称,同时指定连接ODBC的数据库用户名密码
如果一切ok,创建好代理后,在db2数据库中会看到多了很多表,那基本上就没问题了
如果出问题,通常都是数据库连接,对照红皮书检查你的ODBC配置(这个过程很痛苦),以及访问数据库的用户名、是否拥有足够权限。实在不行,找IBM的支持吧…..
以上是连接代理数据库,如果要连接用户的oracle数据库,请参考我之前写的第六篇笔记,利用这条命令:
mqsisetdbparms brokerName -n dataSourceName [-u dataSourceUserId] -p dataSourcePassword
最后用mqsistart启动一下,一切ok的话,就算完成万里长征第一步了。
WMBT远程开发、调试
单纯安装好MB还是不够的,你还要用WMBT开发、部署和调试消息流,有谁喜欢坐在风扇轰鸣、充满辐射的机房里coding呢?所以接下来讲述如何配置WMB和WMBT,使得开发者可以远程连接MB并进行调试
在此之前,可以参考这篇文章,实现远程管理你的MQ
http://blog.csdn.net/Justin4wd/archive/ 2008/07/16 /2661131.aspx
首先在MQ中建立监听器和服务器连接通道,具体请参考我的第三篇笔记
http://blog.csdn.net/wangchengsi/archive/2008/07/08/2625598.aspx
如果MB和WMBT是在同一台机器,这样做已经足够了,但如果是远程连接,直接连接会报告以下错误,则还需要在MB那里配置ACL(访问权限列表)
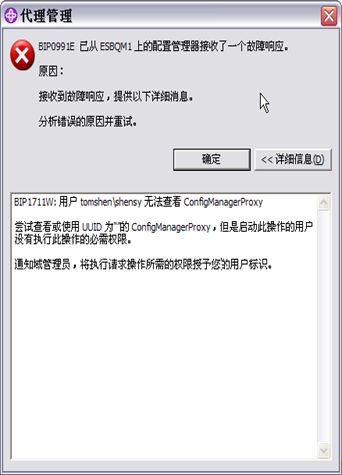
从上图可以获得你的机器名和用户名
在linux打开一个终端,输入以下命令
mqsicreateaclentry 配置管理器 -u 用户名 -m 机器名 -x F –p
-x F表示访问程度,F表示完全访问
-p表示访问Proxy,即ConfigManagerProxy,相当于可以访问所有资源,比如代理
再次从toolkit连接MB,就可以了
之后,开发、部署、调试的过程都和本地的机器一样,读者可以看我之前写的关于调试功能的配置
注意,6.0以前的MB需要安装RAC(Rational Agent Controller)才能远程调试,6.1开始已经不用了
IBM MessageBroker笔记系列(九)
这篇是纯粹的“coding心得”,撇开MB那些啰嗦的配置不谈,专门讲学习ESQL的痛苦经历,有些内容可能前面的笔记有介绍过,这里做一个全面的汇总。虽然有些编程的tips已经忘记了,以后如果想起来还会继续补充。
概述
ESQL的语法和数据库的存储过程语句很像,虽然我从未写过存储过程,但是平心而论,ESQL的基本语法和概念还是很好理解的,毕竟,ESQL没有类、对象、多态这些OOP的东西,也没有指针、位移操作这些C的概念;没有C的函数指针、指针的指针、内存分配这种让新手头晕的术语,也不像Java那样各类框架满天飞,开足马力都学不过来。所以,ESQL还是很好入门的。但是,切记,只是“入门”而已。你看懂那些示例的ESQL很容易,无非是逻辑树的增删改;消息流也是那么一目了然,消息从一个节点出来,进入另一个节点,不知不觉一个“业务流”就完成了,so simple,naïve!我一开始也是这么觉得的,但真正动手的时候,才发觉ESQL代码中,危机四伏!下面一一列举
基本类型
数字
ESQL的基本类型很少,无非是数字、字符串、逻辑、时间,还有引用。数字类型包括int、float和decimal(就是double,高精度小数),一般很少会考虑三者的差别,把它们与java的等同起来,其实不然,如果随便乱用,会冒出很多无聊而又浪费时间的bug
- 数据库查询
在使用oracle的时候,通常都会用Number类型作为主键id等数字类型字段,可是你知道用select语句取Number到ESQL中是什么吗?是decimal。由于ESQL里面,消息树中的字段类型是隐式的、可变的(类似PHP),也就是你可以随便赋任何值给某个消息节点。按理说这种脚本语言的特性可以方便编程,是好事。不过请先看完下面的描述。
- 数据库插入
这个问题是最近才发现的,在64位的linux上,MB使用64位数据源访问oracle,在一条insert语句上屡屡失败,而这条insert语句之前在32位windows平台上却很正常的执行。抛出的异常提示:“oracle:String data, right truncated”,在网上搜了一下大部分人都说是数据太长,只有dw论坛上有人说可能是64bit数据源的关系,但具体原因也不清楚。请了IBM的支持来搞了半天也没任何结果,绝望之际我干脆用排除法,每次修改一两个字段为很简单的常数(那样总不会出问题了),在排除到最后一个字段时,才发现把一个decimal的数据插进去会有问题,如果换成float就ok了!这个问题前后浪费了我两天,当时忍不住说了几句脏话,一个简单的问题搞得这么恶心,错误提示也纯粹误导用户。天知道以后换成其他平台会不会又这样呢?
- 函数调用
ESQL是弱类型的?是的,某种程度上是弱类型的,可是遇到函数调用的时候,它的类型强度简直胜过java——你不能把一个int作为参数传递给声明为double的参数,那样会抛出异常。问题是有时候你根本不知道某个消息树节点啥时变成了int或者是float或是double,就像上文说到的数据库查询结果。请打开debug,慢慢找吧,总会有柳暗花明的一刻
字符串类型
估计MB为了照顾比较“原始”的消息格式,即非XML、而是CWF或者TDS格式的消息,ESQL的字符串类型不仅仅有字符类型“char”,还有字节类型“BLOB”和比特类型“BIT”,的确是大大方便了比特流的处理。关于字符串,发现的问题不多,下面列出几点需要稍加注意之处。
- 字符串连接“||”
使用“||”连接字符串时,记得每个被连接的变量都不能为null,否则连接后的结果就变成null了,可以用“变量 is not null”来判断
- BLOB类型
BLOB类型在ESQL中的表示方式为 X'ABCD',实际上是一种BCD码,每个字符表示一个十六进制,即半个字节。注意这里要是偶数个长度,否则在打包或者部署时会报错
时间类型
和一般编程语言不同的是ESQL有时间类型的变量,这很大程度上是因为MB里面支持很多XML的特性,而时间类型也是标准XML中包含的,例如xsd:dateTime等等。我没学过高级的XML,自然对这些名目繁多的时间类型之间的差别不甚了解,所以简单地列出几点比较常用的特性:
- 消息定义中的时间类型
消息定义文件里头也可以声明某个节点类型为timestamp(消息定义文件本质上就是XML SCHEMA文件,自然支持xsd:命名空间),不过在实践中发现从MQ读入的一个XML字符串,解析为timestamp类型时,经常有一些格式上的问题而导致解析失败,后来干脆把timestamp全部替换为string了,IBM的技术支持也是这么“推荐”的,估计是他们也找不出原因所在
- 计算花费的时间
JAVA里面很常用的就是通过计算系统时间之差,来得到一段代码的运行时间毫秒数,然后用时间类可以进行格式转换,ESQL同样可以做到,而且更加简单。比如要计算一个消息流的运行时间,那么在消息流开头用 CURRENT_TIME得到起始时间,保存在环境树中的T1节点;然后在消息流结尾,再次用 CURRENT_TIME得到结束时间T2,两个时间值相减,再用下面这段代码将其转换成毫秒数
SET OutputRoot.MRM.process_time = CAST( (T2-Environment.Variables.T1) SECOND AS FLOAT) *1000;
很遗憾的,ESQL最小只支持“秒”的时间间隔(“时间间隔”INTERVAL也是一种时间类型),不过得到的float值通常是小数位很长的,包含了毫秒信息,譬如0.2352436,因此乘以1000也完全够用
全局变量
问过IBM的人好几次,自己也去查了不少资料,一直没有发现ESQL中有足够理想的全局变量或者全局常量。我们知道,ESQL的代码层次从高到低依次是:schema->module->function or procedure,越是局部的变量,优先级越高,这一点和普通编程语言一样。所以,没有变量的声明可以超越schema这一级,包括所谓的外部变量external,因此,在不同schema的消息流之间不能共享全局变量的,这个限制有时候很麻烦,比如所有消息流都要访问同一个数据源、或者Oracle的schema,或者是你自己定义的全局常量,那你就只能在每个schema中设置了,还好schema不会很多,或者你在消息流开始的时候,从文件、数据库等地方读取配置参数也是一种选择。
对于定义好的全局变量,可以用{ }进行变量值的替换,从而实现动态功能,比如 OutputBody.{myvar}.value,花括号的值会在运行期间指定。但是这样一来ESQL的编辑器就无法判断这个节点是否存在,会给出“无法解析该引用”的警告,这不影响使用。
全局函数
刚才说到的在schema作用域中定义的全局变量,在其他schema不能引用。但是在schema中定义的全局函数或者过程,则可以在其他schema中引用,只要在定义schema时使用PATH将其他schema导入即可,或者在调用函数时指定完整路径,如 CALL com.xxx.GLOBAL_FUNCTION。很多人一开始会对全局函数寄予厚望,因为可以减少代码的重复,增加复用度,实则符合圣人们的教诲。只可惜呢,全局函数中不能使用通常在节点中的Root、ExceptionList、Environment等逻辑树,所以我在定义全局函数时,第一个参数通常都是REFERENCE类型,用来把Environment等逻辑树传进去。
数组、ROW和LIST
ESQL里面有数组类型,但你不能DECLARE一个数组变量;有ROW类型,同时有个ROW函数专门用来产生一个ROW变量,还有个LIST函数用来产生数组。
先谈谈数组,数组是什么大家都知道了,在ESQL里面,由于不能声明一个数组,所以我习惯把数组保存在Environment或者LocalEnvironment中。因为消息树的每个节点都可以往下增加子结点,所以每个消息树的中间节点其实都是数组,我们说 set LocalEnvironment.Variables.temp = xxx ,实际上就是 set LocalEnvironment.Variables.temp[1] = xxx
至于ROW类型,《精通WMB》上说是个XML单行数据,执行这条ESQL语句:set LocalEnvironment.root = ROW('aa' AS a, 'bb' AS b),(注意root旁边没有方括号[ ])生成的XML片段如下:
bb
然而,ROW其实是对应与数据库的一行数据,仅此而已。上面的root节点相当于一行,a和b则是该行数据的字段,就这么简单。所以,执行select语句时,返回的就是一个ROW的数组
LIST函数是产生数组用的,例如:set LocalEnvironment.Var.root[ ] =LIST( 'aa', 'bb'),(root旁边这次有方括号[])产生如下XML:
aa bb
详细内容,请参考老陈的《精通WMB》后面的附录P321(我也是最近才无意中翻到ROW和LIST)
MB与MQ简介
今天听IBM的工程师介绍了MQ和MB的特性,以及他们的区别与联系,觉得很通俗易懂,特此记录,方便将来的初学者可以更快的把握这两者的特点。
首先从概念上来说,MQ是消息中间件,MB是ESB产品
MQ负责在两个系统之间传递消息,这两个系统可以是异构的,处于不同硬件、不同操作系统、用不同语言编写,只需要简单的调用几个MQ的API,就可以互相通讯,你不必考虑底层系统和网络的复杂性。MQ作为IBM的一个拳头产品,虽然功能看上去很简单,就是个消息队列,但他却是IBM中间件的核心,也是相比其他厂商(比如BEA)的一个优势。MQ不仅有很高的性能,而且对各种平台的支持非常好,几乎你能想到的硬件和操作系统平台以及编程语言,MQ都有专门的API支持。但MQ的功能仅限于消息队列,至于应用A发给应用B的消息格式是怎样的、能不能被应用B解析,MQ管不了,他只是尽力将消息发到目的地(MQ能够应付多种异常情况,例如网络阻塞、临时中断等等)。此外,如果应用的数目多了,那互相之间都要建立MQ连接,网络拓扑就成了蜘蛛网了(就好像是最初的电话系统)
因此,我们将网络的星型拓扑引入系统架构中,把一对一的MQ换成一个中心节点,即ESB,MB即是IBM的ESB产品。MB处于系统的中心,起到一个总线的作用,所有应用都直接连接到MB,而不是应用之间直接互联,这样的好处不言而喻,可以极大的降低应用之间的耦合性。由此引出MB的两大核心功能:消息路由和数据转换
因为各个应用都插入到MB上,所以应用A只管把消息丢给MB,MB自动根据消息字段、以及业务逻辑,判断要把消息交给谁,这就像路由器一样,根据数据包的头把包路由到相应地址。MB内部的业务逻辑由开发人员设定,当然利用MB的Toolkit,编写业务逻辑也非常简单:拖一些节点,用箭头把它们连起来,就像是画流程图一样,非常形象简单。再用MB的脚本语言(类似sql的脚本)实现逻辑判断,通俗地说就是判断要走哪个逻辑分支(if...else.....)。
不过各个应用是怎样与MB连接的呢?MB提供了三种方式:MQ、文件和web service
MQ方式即是利用MQ将MB与应用互联;文件方式则是指定某个目录,MB会自动监视那个文件目录,一旦文件有改变则认为是新的消息到来,MB自动读取指定文件的内容;而web service就不用解释了,直接利用web service进行通讯。MB支持这些互联方式也是为了最大化兼容性,特别是对于那些遗留系统或是不支持主流通讯方式的系统
最后说说一个比较偏门的ESB产品:websphere ESB。听过的人可能不多,因为IBM在中国推广的比较少,这个WESB很像是MB的精简版,只支持JMS、WS等少数几种J2EE的通讯方式,所以是为J2EE专门准备的。不像MB,支持数十种平台和通讯方式,例如FTP,甚至很多你根本没听说过的很古老的通信协议。这两者的性能相差不少,价格也有三四倍的差距。更要命的是,原先在WESB上开发的东西,是不能迁移到MB使用的,IBM似乎铁了心要狠狠宰我们,唯一的方法是再买一个MB,然后用MQ把WESB和MB连接起来,各跑各的
漏了一个DataPower,这东西我只是略有了解,它的卖点在于硬件支持XML,所以性能比较好,此外还支持一下web service安全方面的东东。因此,WESB是最小功能集,而MB与datapower功能上有一定重叠,如XML
摘自: http://blog.csdn.net/wangchengsi