k8s部署和基本使用
一个简单的互联网应用
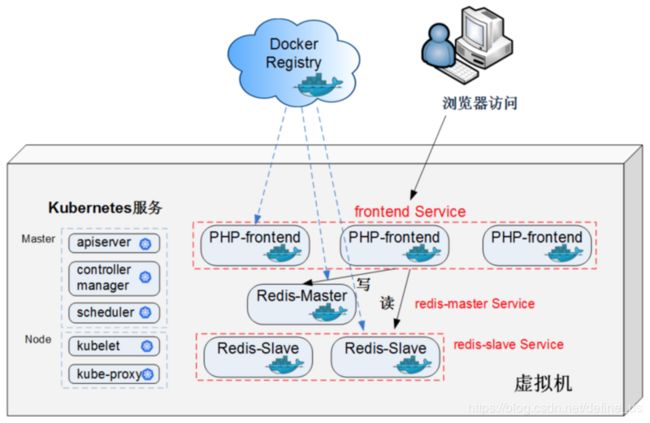
K8S集群的基本构造
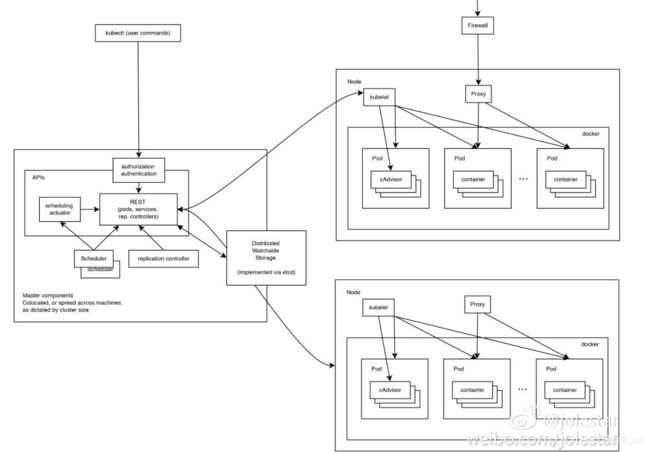
master:负责管理整个集群,例如,对应用进行调度(扩缩)、维护应用期望的状态、对应用进行发布等。
node:集群中的宿主机(可以是物理机也可以是虚拟机),每个node上都有一个agent,名为kubelet,用于跟master通信。同时一个node需要有管理容器的工具包,用于管理在node上运行的容器(如docker)。一个k8s集群至少要有3个节点
master节点
master节点上有如下进程(一个apiserver,一个controller-manager,一个scheduler)
$ ps -elf|grep -i Kubernetes
0 R umelog 11077 5416 0 80 0 - 28166 - 14:51 pts/2 00:00:00 grep --color=auto -i Kubernetes
4 S root 63481 1 1 80 0 - 65218 futex_ 10:48 ? 00:02:52 /usr/bin/kube-apiserver --storage-backend=etcd2 --insecure-bind-address=0.0.0.0 --insecure-port=1180 --etcd-servers=http://10.237.65.192:2379,http://10.237.65.193:2379,http://10.237.65.194:2379 --service-cluster-ip-range=169.169.0.0/16 --admission_control=NamespaceLifecycle,LimitRanger,ResourceQuota,ServiceAccount --service-node-port-range=10-65535 --client_ca_file=/etc/kubernetes/ssl/ca.crt --tls-private-key-file=/etc/kubernetes/ssl/apiserver.key --tls-cert-file=/etc/kubernetes/ssl/apiserver.crt --logtostderr=false --log-dir=/opt/log/kubernetes --v=0 --allow_privileged=true
4 S root 63560 1 1 80 0 - 27582 futex_ 10:50 ? 00:02:35 /usr/bin/kube-controller-manager --node-sync-period=10s --service_account_private_key_file=/etc/kubernetes/ssl/apiserver.key --root-ca-file=/etc/kubernetes/ssl/ca.crt --v=0 --logtostderr=false --log-dir=/var/log/kubernetes --master=http://10.237.65.192:1180
4 S root 63603 1 0 80 0 - 15208 futex_ 10:51 ? 00:01:09 /usr/bin/kube-scheduler --logtostderr=false --log-dir=/var/log/kubernetes --v=0 --master=http://10.237.65.192:1180
API server作为集群的核心,负责各个功能模块之间的通信。集群中各个模块通过API server将信息存入etcd,当需要获取和操作这些数据时,则通过API server提供的REST接口来实现,从而实现各模块之间的信息交互。
Kube-scheduler作为组件运行在master节点,主要任务是把从kube-apiserver中获取的未被调度的pod通过一系列调度算法找到最适合的node,最终通过向kube-apiserver中写入Binding对象(其中指定了pod名字和调度后的node名字)来完成调度。Kube-scheduler以插件形式运行,用户如果觉得官方的不满足需求还可以自己实现调度插件。目前Kubernetes同时支持多个kube-scheduler同时运行,以调度器名字区分,每个pod的spec文件中可以指定调度自己的kube-scheduler的schedulerName。
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
Node节点
Node节点下如有日下进程(一个proxy,一个kublet)
ps -elf|grep -i kubernetes
4 S root 2672 1 0 80 0 - 14101 futex_ 13:08 ? 00:00:13 /usr/bin/kube-proxy --proxy-mode=iptables --logtostderr=false --log-dir=/var/log/kubernetes --v=0 --master=http://10.237.65.192:1180
0 S umelog 20568 20447 0 80 0 - 28167 pipe_w 15:28 pts/0 00:00:00 grep --color=auto -i kubernetes
4 S root 62199 1 0 80 0 - 319964 futex_ 11:02 ? 00:02:13 /usr/bin/kubelet --root_dir=/var/kubernetes --v=0 --pod_infra_container_image=10.237.65.192:1179/google_containers/pause:3.0 --cluster_dns=169.169.0.100 --cluster_domain=cluster.local --address=0.0.0.0 --port=10250 --api_servers=http://10.237.65.192:1180 --logtostderr=false --allow_privileged=true --log-dir=/var/log/kubernetes
基本概念
Pod
在K8S中,Pod是创建或部署的最小/最简单的基本单位,一个Pod是由多个Docker容器组成的容器组。
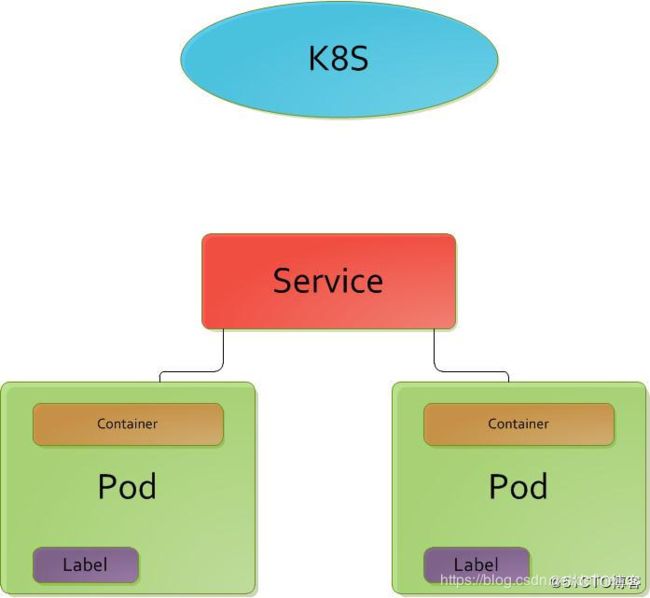
Kubernetes中的Pod使用可分两种主要方式:
- Pod中运行一个容器。“one-container-per-Pod”模式是Kubernetes最常见的用法; 在这种情况下,你可以将Pod视为单个封装的容器,但是Kubernetes是直接管理Pod而不是容器。
- Pod中运行多个需要一起工作的容器。Pod可以封装紧密耦合的应用,它们需要由多个容器组成,它们之间能够共享资源,这些容器可以形成一个单一的内部service单位 - 一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
Service
是真实应用服务的抽象。Service通常用来将浮动的资源与后端真实提供服务的容器进行关联。Service对外表现为一个单一的访问接口,外部不需要了解后端的规模与机制。Service是定义在集群中一组运行Pod集合的抽象资源,它提供了所有相同的功能。当一个Service资源被创建后,将会分配一个唯一的IP(也叫做集群IP),这个IP地址将存在于Service的整个生命资源,Service一旦被创建,整个IP无法进行修改。Pod可以通过Service进行通信,并且所有的通信将会通过Service自动负载均很到所有的Pod中的容器。
Service主要存在的目的是POD的不稳定。而Service和集群IP是绑定的。Service实际上对应的就是微服务。
Pod IP/Cluster IP/外部IP
-
Pod IP
Kubernetes的最小部署单元是Pod。利用Flannel作为不同HOST之间容器互通技术时,由Flannel和etcd维护了一张节点间的路由表。Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。每个Pod启动时,会自动创建一个镜像为gcr.io/google_containers/pause:0.8.0的容器,pod内部与外部的通信经由此容器代理,该容器的IP也可以称为Pod IP。 -
Cluster IP
Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,但Service Cluster IP就不一样了,没有网络设备为这个地址负责。它是由kube-proxy使用Iptables规则重新定向到其本地端口,再均衡到后端Pod的。 -
外部IP
Service对象在Cluster IP range池中分配到的IP只能在内部访问,如果服务作为一个应用程序内部的层次,还是很合适的。如果这个Service作为前端服务,准备为集群外的客户提供业务,我们就需要给这个服务提供公共IP了。
Replication Controller
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个,和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
流程和原理
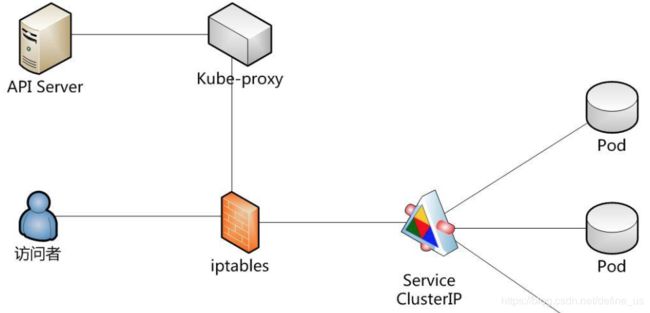
Service启动流程
- 当我们的Service被创建时,Kubernetes给它分配一个地址10.0.0.1(Cluster IP)。这个地址从我们启动API的service-cluster-ip-range参数(旧版本为portal_net参数)指定的地址池中分配,比如–service-cluster-ip-range=10.0.0.0/16。
- 集群内的所有kube-proxy都会注意到这个Service。当proxy发现一个新的service后,它会在本地节点打开一个任意端口,建相应的iptables规则,重定向服务的IP和port到这个新建的端口,开始接受到达这个服务的连接。
kube-proxy转发的两种模式
由kube-proxy转发,效率不是很高
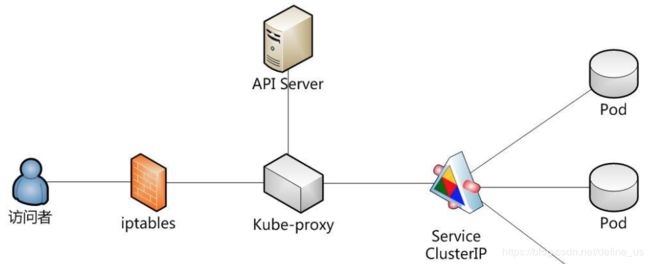
kube-proxy只负责更改iptable的设置。内核转发。效率高。
相关组件介绍
Etcd
etcd的官网介绍是一个分布式的K/V存储,而Zookeeper的官网介绍是一个高度可用的分布式协调者。看起来他们做的事情完全不同啊,那我们来比较一下功能介绍。但是实际上二者非常类似。
| 功能 | etcd | Zookeeper |
|---|---|---|
| 分布式锁 | 有 | 有 |
| watcher | 有 | 有 |
| 一致性算法 | raft | zab(paxos算法的改进) |
| 选举 | 有 | 有 |
| 元数据(metadata)存储 | 有 | 有 |
二者的使用场景的对比如下
| 应用场景 | etcd | Zookeeper |
|---|---|---|
| 发布与订阅(配置中心) | 有 | 有 |
| 软负载均衡 | 有 | 有 |
| 命名服务(Naming Service) | 有 | 有 |
| 服务发现 | 有 | 有 |
| 分布式通知/协调 | 有 | 有 |
| 集群管理与Master选举 | 有 | 有 |
| 分布式锁 | 有 | 有 |
| 分布式队列 | 有 | 有 |
ETCD存储着docker集群的一些基本配置。
$ etcdctl ls /registry
/registry/minions
/registry/deployments
/registry/ranges
/registry/services
/registry/apiregistration.k8s.io
/registry/configmaps
/registry/events
/registry/secrets
/registry/replicasets
/registry/pods
/registry/controllers
/registry/namespaces
/registry/serviceaccounts
TLS
SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL协议可分为两层: SSL记录协议(SSL Record Protocol):它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。
安全传输层协议(TLS)用于在两个通信应用程序之间提供保密性和数据完整性。该协议由两层组成: TLS 记录协议(TLS Record)和 TLS 握手协议(TLS Handshake)。较低的层为 TLS 记录协议,位于某个可靠的传输协议(例如 TCP)上面,与具体的应用无关,所以,一般把TLS协议归为传输层安全协议。
flannel
根据官网的描述,flannel是一个专为kubernetes定制的三层网络解决方案,主要用于解决容器的跨主机通信问题。
组件选择
Kubernetes 1.9 <–Docker 1.11.2 to 1.13.1 and 17.03.x
Kubernetes 1.8 <–Docker 1.11.2 to 1.13.1 and 17.03.x
Kubernetes 1.7 <–Docker 1.10.3, 1.11.2, 1.12.6
Kubernetes 1.6 <–Docker 1.10.3, 1.11.2, 1.12.6
Kubernetes 1.5 <–Docker 1.10.3, 1.11.2, 1.12.3
常见解决方案
日志收集
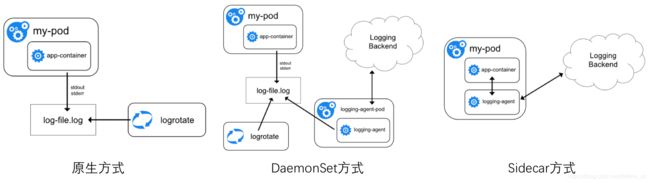
有三种方案
- 原生方式:使用 kubectl logs 直接在查看本地保留的日志,或者通过docker engine的 log driver 把日志重定向到文件、syslog、fluentd等系统中。
- DaemonSet方式:在K8S的每个node上部署日志agent,由agent采集所有容器的日志到服务端。(agent本身是一个pod)
- Sidecar方式:一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。(agent部署在每一个pod中)
服务发现和负载均衡
一般,我们采取基于客户端的负载均衡,而不采用反向代理的方式。这主要是考虑到服务注册代码和业务代码的松耦合问题。k8s下的服务往往是通过DNS进行负载均衡。