命名空间:tf.nn
| 函数 | 作用 | 说明 |
|---|---|---|
| sigmoid_cross_entropy_with_logits | 计算 给定 logits 的S函数 交叉熵。 | 测量每个类别独立且不相互排斥的离散分类任务中的概率。(可以执行多标签分类,其中图片可以同时包含大象和狗。) |
| weighted_cross_entropy_with_logits | 计算加权交叉熵。 | |
| softmax_cross_entropy_with_logits | 计算 logits 和 labels 之间的 softmax 交叉熵。 | 测量类别相互排斥的离散分类任务中的概率(每个条目恰好在一个类别中)。(有一个且只有一个标签:图像可以是狗或卡车,但不能同时为两个。)注意: 每行labels[i]必须是有效的概率分布。如果不是,梯度的计算将是不正确的。警告:此操作期望未缩放的logits,因为它softmax 在logits内部执行效率。不要用这个输出来调用这个op softmax,因为它会产生不正确的结果。lables的数据必须经过One-Hot Encoding(tf.one_hot) |
| sparse_softmax_cross_entropy_with_logits | 计算 logits 和 labels 之间的 稀疏softmax 交叉熵。 | 测量类别相互排斥的离散分类任务中的概率(每个条目恰好在一个类别中)。(有一个且只有一个标签:图像可以是狗或卡车,但不能同时为两个。)注意: 对于此操作,给定标签的概率被认为是独占的。也就是说,不允许使用软类,并且labels向量必须为每个logits(每个minibatch条目)的每一行的真类提供单个特定索引 。对于每个条目的概率分布的软softmax分类,请参阅 softmax_cross_entropy_with_logits。警告:此操作期望未缩放的logits,因为它softmax 在logits内部执行效率。不要用这个输出来调用这个op softmax,因为它会产生不正确的结果。 |
| softmax | 计算 softmax 激活。 | 相当于 softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), dim) |
| log_softmax | 计算 对数 softmax 激活。 | logsoftmax = logits - log(reduce_sum(exp(logits), dim)) |
tf.nn.sigmoid_cross_entropy_with_logits
该函数计算的是 logits 与 lables 的每一个对应维度上对应元素的损失值。数值越小,表示损失值越小。
import tensorflow as tf
_logits = [[0.5, 0.7, 0.3], [0.8, 0.2, 0.9]]
_one_labels = tf.ones_like(_logits)
_zero_labels = tf.zeros_like(_logits)
with tf.Session() as sess:
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=_logits, labels=_one_labels)
# [[0.47407699 0.40318602 0.5543552]
# [0.37110069 0.59813887 0.34115386]]
print(sess.run(loss))
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=_logits, labels=_zero_labels)
# [[0.97407699 1.10318601 0.85435522]
# [1.17110074 0.79813886 1.24115384]]
print(sess.run(loss))weighted_cross_entropy_with_logits
weighted_cross_entropy_with_logits 是 sigmoid_cross_entropy_with_logits 的拓展版,输入参数和实现和后者差不多,可以多支持一个 pos_weight 参数,目的是可以增加或者减小正样本在算 Cross Entropy 时的 Loss 。
通常的交叉熵成本定义为:targets * -log(sigmoid(logits)) + (1 - targets) * -log(1 - sigmoid(logits))
这个 pos_weight 被用作积极目标的乘数:targets * -log(sigmoid(logits)) * pos_weight + (1 - targets) * -log(1 - sigmoid(logits))
tf.nn.softmax_cross_entropy_with_logits
该函数与 sigmoid_cross_entropy_with_logits 的区别在于,sigmoid_cross_entropy_with_logits 中的labels 中每一维可以包含多个 1 ,而 softmax_cross_entropy_with_logits ,只能包含一个 1。
用 mnist 数据举例,如果是目标值是3,那么 label 就是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0。(数据必须经过 One-Hot Encoding 编码)
该函数把一个维度上的 labels 作为一个整体判断,结果给出整个维度的损失值。(而 sigmoid_cross_entropy_with_logits 是每一个元素都有一个损失值)
如果是多目标问题,经过softmax就不会得到多个和为1的概率,而且label有多个1也无法计算交叉熵,因此这个函数只适合单目标的二分类或者多分类问题。
这个函数传入的 logits 是 unscaled 的,既不做 sigmoid 也不做 softmax ,因为函数实现会在内部更高效得使用 softmax 。
import tensorflow as tf
_logits = [[0.3, 0.2, 0.2], [0.5, 0.7, 0.3], [0.1, 0.2, 0.3]]
_labels = [0, 1, 2]
with tf.Session() as sess:
# Softmax本身的算法很简单,就是把所有值用e的n次方计算出来,求和后算每个值占的比率,保证总和为1,一般我们可以认为Softmax出来的就是confidence也就是概率
# [[0.35591307 0.32204348 0.32204348]
# [0.32893291 0.40175956 0.26930749]
# [0.30060959 0.33222499 0.36716539]]
print(sess.run(tf.nn.softmax(_logits)))
# 对 _logits 进行降维处理,返回每一维的合计
# [1. 1. 0.99999994]
print(sess.run(tf.reduce_sum(tf.nn.softmax(_logits), 1)))
# 传入的 lables 需要先进行 独热编码 处理。
loss = tf.nn.softmax_cross_entropy_with_logits(logits=_logits, labels=tf.one_hot(_labels,depth=len(_labels)))
# [ 1.03306878 0.91190147 1.00194287]
print(sess.run(loss))tf.one_hot
独热编码
import tensorflow as tf
with tf.Session() as sess:
_v = tuple(range(0, 5))
# [[ 1. 0. 0. 0. 0.]
# [ 0. 1. 0. 0. 0.]
# [ 0. 0. 1. 0. 0.]
# [ 0. 0. 0. 1. 0.]
# [ 0. 0. 0. 0. 1.]]
print(sess.run(tf.one_hot(_v, len(_v))))sparse_softmax_cross_entropy_with_logits
sparse_softmax_cross_entropy_with_logits 是 softmax_cross_entropy_with_logits 的易用版本,除了输入参数不同,作用和算法实现都是一样的。
区别是:softmax_cross_entropy_with_logits 要求传入的 labels 是经过 one_hot encoding 的数据,而 sparse_softmax_cross_entropy_with_logits 不需要。
import tensorflow as tf
_logits = [[0.3, 0.2, 0.2], [0.5, 0.7, 0.3], [0.1, 0.2, 0.3]]
_labels = [0, 1, 2]
with tf.Session() as sess:
#
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=_logits, labels=_labels)
# 结果与 softmax_cross_entropy_with_logits 相同,区别就是 labels 传入参数时不需要做 one_hot encoding。
# [ 1.03306878 0.91190147 1.00194287]
print(sess.run(loss))softmax
softmax 公式: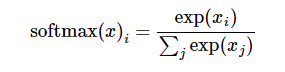
Softmax本身的算法很简单,就是把所有值用e的n次方计算出来,求和后算每个值占的比率,保证总和为1,一般我们可以认为Softmax出来的就是confidence也就是概率
该功能执行相当于 softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), dim)
import tensorflow as tf
with tf.Session() as sess:
_v = tf.Variable(tf.random_normal([1, 5], seed=1.0))
sess.run(tf.global_variables_initializer())
# [[-0.81131822 1.48459876 0.06532937 -2.4427042 0.0992484]]
print(sess.run(_v))
# [[0.06243069 0.6201579 0.15001042 0.01221508 0.15518591]]
print(sess.run(tf.nn.softmax(_v)))
# 1.0
print(sess.run(tf.reduce_sum(tf.nn.softmax(_v))))log_softmax
该功能执行相当于 logsoftmax = logits - log(reduce_sum(exp(logits), dim))
内容来源:
TensorFlow
TensorFlow四种Cross Entropy算法实现和应用
数据预处理:独热编码(One-Hot Encoding)
[Tensorflow]1.交叉熵(Cross Entropy)算法实现及应用