k8s(6)——— service详解
目录
一、service服务的类型及简介
- 1、简介
- 2、Service 资源
- 3、定义 Service
- 4、VIP 和 Service 代理
- 5、发布服务 —— 服务类型
二、实验准备
- 1.1、实验准备集起集群
- 1.2、验证实验环境是否可用
三、service的创建
- 1、查看帮助
- 2、创建一个简单的service
- 3、验证service服务能负载均衡
- 4、创建busyboxplus测试容器
四、开启kube-proxy的ipvs模式
- 1、在节点上查看相关的iptables命令、安装 ipvsadm软件
- 2、开启kube-proxy的ipvs模式
- 3、查看ipvs策略是否生效
- 4、多创建服务(来查看节点的ip)
- 5、kube-proxy会在service创建后在宿主机添加网卡(kube-ipvs0)
- 6、验证与外部链接的轮询机制
五、 Flannel vxlan模式跨主机通信原理(跨物理节点)
- 1、工作原理:
- 2、查看网桥的工作原理
- 3、各个节点的ip_forward 一定要打开
- 4、查看各个节点的pod ip对应的mac地址、以及mac和flannel.1
六、NodePort
- 1、创建 NodePort
- 2、测试
七、LoadBalancer
- 1、LoadBalancer讲述
八、ExternalName
- 1、创建ExternalName
- 2、测试
九、创建一个对外暴露的自定义IP
- 1、创建service
- 2、测试
- 3、查看系统自动分配的ip
一、service服务的类型及简介
1、简介
- Service可以看作是一组提供想替服务的Pod对外访问端口。借助Service 应用可以方便地实现服务发现和均衡负载
- Service默认只支持4层负载均衡能力,没有7层功能(可以通过Ingress实现)、
- Service类型
- ClusterIP:默认值,k8s系统给service自动分配的虚拟IP,只能在集群的内部访问
- NpdePort 将service通过指定的Node上的端口暴露给外部,访问任意一个
- NpdePort:nodePort都将路由到ClusterIP
- LoadBalancer 在Nodeport 的基础上,借助cloud provider 创建一个外部的负载均衡,并将请求转发
:Nodeport 此模式只能在云服务上使用 - ExtenlName:将服务通过DNS CNAME 记录方式转发到指定的域名 (通过spec.externlName设定)
Kubernetes Pods 是有生命周期的。他们可以被创建,而且销毁不会再启动。 如果您使用 Deployment 来运行您的应用程序,则它可以动态创建和销毁 Pod。
Endpoint 切片
FEATURE STATE: Kubernetes v1.16 alpha
Endpoint 切片是一种 API 资源,可以为 Endpoint 提供更可扩展的替代方案。 尽管从概念上讲与 Endpoint 非常相似,但 Endpoint 切片允许跨多个资源分布网络端点。 默认情况下,一旦到达100个 Endpoint,该 Endpoint 切片将被视为“已满”,届时将创建其他 Endpoint 切片来存储任何其他 Endpoint。
Endpoint 切片提供了附加的属性和功能,这些属性和功能在 Endpoint 切片中进行了详细描述。
每个 Pod 都有自己的 IP 地址,但是在 Deployment 中,在同一时刻运行的 Pod 集合可能与稍后运行该应用程序的 Pod 集合不同。
这导致了一个问题: 如果一组 Pod(称为“后端”)为群集内的其他 Pod(称为“前端”)提供功能,那么前端如何找出并跟踪要连接的 IP 地址,以便前端可以使用工作量的后端部分?
进入 _Services_。
2、Service 资源
Kubernetes Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 selector (查看下面了解,为什么你可能需要没有 selector 的 Service)实现的。
举个例子,考虑一个图片处理 backend,它运行了3个副本。这些副本是可互换的 —— frontend 不需要关心它们调用了哪个 backend 副本。 然而组成这一组 backend 程序的 Pod 实际上可能会发生变化,frontend 客户端不应该也没必要知道,而且也不需要跟踪这一组 backend 的状态。 Service 定义的抽象能够解耦这种关联。
多端口 Service
Services
将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
使用Kubernetes,您无需修改应用程序即可使用不熟悉的服务发现机制。 Kubernetes为Pods提供自己的IP地址和一组Pod的单个DNS名称,并且可以在它们之间进行负载平衡。
动机
Kubernetes Pods 是有生命周期的。他们可以被创建,而且销毁不会再启动。 如果您使用 Deployment 来运行您的应用程序,则它可以动态创建和销毁 Pod。
每个 Pod 都有自己的 IP 地址,但是在 Deployment 中,在同一时刻运行的 Pod 集合可能与稍后运行该应用程序的 Pod 集合不同。
这导致了一个问题: 如果一组 Pod(称为“后端”)为群集内的其他 Pod(称为“前端”)提供功能,那么前端如何找出并跟踪要连接的 IP 地址,以便前端可以使用工作量的后端部分?
进入 _Services_。
Service 资源
Kubernetes Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 selector (查看下面了解,为什么你可能需要没有 selector 的 Service)实现的。
举个例子,考虑一个图片处理 backend,它运行了3个副本。这些副本是可互换的 —— frontend 不需要关心它们调用了哪个 backend 副本。 然而组成这一组 backend 程序的 Pod 实际上可能会发生变化,frontend 客户端不应该也没必要知道,而且也不需要跟踪这一组 backend 的状态。 Service 定义的抽象能够解耦这种关联。
云原生服务发现
如果您想要在应用程序中使用 Kubernetes 接口进行服务发现,则可以查询 API server 的 endpoint 资源,只要服务中的Pod集合发生更改,端点就会更新。
对于非本机应用程序,Kubernetes提供了在应用程序和后端Pod之间放置网络端口或负载均衡器的方法。
3、定义 Service
一个 Service 在 Kubernetes 中是一个 REST 对象,和 Pod 类似。 像所有的 REST 对象一样, Service 定义可以基于 POST 方式,请求 API server 创建新的实例。
例如,假定有一组 Pod,它们对外暴露了 9376 端口,同时还被打上 app=MyApp 标签。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376上述配置创建一个名称为 “my-service” 的 Service 对象,它会将请求代理到使用 TCP 端口 9376,并且具有标签 "app=MyApp" 的 Pod 上。 Kubernetes 为该服务分配一个 IP 地址(有时称为 “集群IP” ),该 IP 地址由服务代理使用。 (请参见下面的 虚拟 IP 和服务代理). 服务选择器的控制器不断扫描与其选择器匹配的 Pod,然后将所有更新发布到也称为 “my-service” 的Endpoint对象。
注意:需要注意的是,
Service能够将一个接收port映射到任意的targetPort。 默认情况下,targetPort将被设置为与port字段相同的值。
Pod中的端口定义具有名称字段,您可以在服务的 targetTarget 属性中引用这些名称。 即使服务中使用单个配置的名称混合使用 Pod,并且通过不同的端口号提供相同的网络协议,此功能也可以使用。 这为部署和发展服务提供了很大的灵活性。 例如,您可以更改Pods在新版本的后端软件中公开的端口号,而不会破坏客户端。
- Service可以看作是一组提供想替服务的Pod对外访问端口。借助Service 应用可以方便地实现服务发现和均衡负载
- Service默认只支持4层负载均衡能力,没有7层功能(可以通过Ingress实现)、
- Service类型
- ClusterIP:默认值,k8s系统给service自动分配的虚拟IP,只能在集群的内部访问
- NpdePort 将service通过指定的Node上的端口暴露给外部,访问任意一个
- NpdePort:nodePort都将路由到ClusterIP
- LoadBalancer 在Nodeport 的基础上,借助cloud provider 创建一个外部的负载均衡,并将请求转发
:Nodeport 此模式只能在云服务上使用 - ExtenlName:将服务通过DNS CNAME 记录方式转发到指定的域名 (通过spec.externlName设定)
服务的默认协议是TCP。 您还可以使用任何其他 受支持的协议。
由于许多服务需要公开多个端口,因此 Kubernetes 在服务对象上支持多个端口定义。 每个端口定义可以具有相同的 protocol,也可以具有不同的协议。
没有 selector 的 Service
服务最常见的是抽象化对 Kubernetes Pod 的访问,但是它们也可以抽象化其他种类的后端。 实例:
- 希望在生产环境中使用外部的数据库集群,但测试环境使用自己的数据库。
- 希望服务指向另一个 命名空间 中或其它集群中的服务。
- 您正在将工作负载迁移到 Kubernetes。 在评估该方法时,您仅在 Kubernetes 中运行一部分后端。
在任何这些场景中,都能够定义没有 selector 的 Service。 实例:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376由于此服务没有选择器,因此 不会 自动创建相应的 Endpoint 对象。 您可以通过手动添加 Endpoint 对象,将服务手动映射到运行该服务的网络地址和端口:
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- ip: 192.0.2.42
ports:
- port: 9376注意:端点 IPs 必须不可以 : 环回( IPv4 的 127.0.0.0/8 , IPv6 的 ::1/128 )或本地链接(IPv4 的 169.254.0.0/16 和 224.0.0.0/24,IPv6 的 fe80::/64)。 端点 IP 地址不能是其他 Kubernetes Services 的群集 IP,因为 kube-proxy 不支持将虚拟 IP 作为目标。
- Service可以看作是一组提供想替服务的Pod对外访问端口。借助Service 应用可以方便地实现服务发现和均衡负载
- Service默认只支持4层负载均衡能力,没有7层功能(可以通过Ingress实现)、
- Service类型
- ClusterIP:默认值,k8s系统给service自动分配的虚拟IP,只能在集群的内部访问
- NpdePort 将service通过指定的Node上的端口暴露给外部,访问任意一个
- NpdePort:nodePort都将路由到ClusterIP
- LoadBalancer 在Nodeport 的基础上,借助cloud provider 创建一个外部的负载均衡,并将请求转发
:Nodeport 此模式只能在云服务上使用 - ExtenlName:将服务通过DNS CNAME 记录方式转发到指定的域名 (通过spec.externlName设定)
访问没有 selector 的 Service,与有 selector 的 Service 的原理相同。 请求将被路由到用户定义的 Endpoint, YAML中为: 192.0.2.42:9376 (TCP)。
ExternalName Service 是 Service 的特例,它没有 selector,也没有使用 DNS 名称代替。 有关更多信息,请参阅本文档后面的ExternalName。
4、VIP 和 Service 代理
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式
为什么不使用 DNS 轮询?
时不时会有人问道,就是为什么 Kubernetes 依赖代理将入站流量转发到后端。 那其他方法呢? 例如,是否可以配置具有多个A值(或IPv6为AAAA)的DNS记录,并依靠轮询名称解析?
使用服务代理有以下几个原因:
- DNS 实现的历史由来已久,它不遵守
发布服务 —— 服务类型
对一些应用(如 Frontend)的某些部分,可能希望通过外部Kubernetes 集群外部IP 地址暴露 Service。
Kubernetes
ServiceTypes允许指定一个需要的类型的 Service,默认是ClusterIP类型。Type的取值以及行为如下: *ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。 *NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort服务会路由到ClusterIP服务,这个ClusterIP服务会自动创建。通过请求: NodePort服务。 *LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到NodePort服务和ClusterIP服务。 *ExternalName:通过返回CNAME和它的值,可以将服务映射到externalName字段的内容(例如,foo.bar.example.com)。 没有任何类型代理被创建。
记录 TTL,并且在名称查找结果到期后对其进行缓存。 - 有些应用程序仅执行一次 DNS 查找,并无限期地缓存结果。
- 即使应用和库进行了适当的重新解析,DNS 记录上的 TTL 值低或为零也可能会给 DNS 带来高负载,从而使管理变得困难。
userspace 代理模式
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的backend Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个 backend Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
最后,它安装 iptables 规则,捕获到达该 Service 的 clusterIP(是虚拟 IP)和 Port 的请求,并重定向到代理端口,代理端口再代理请求到 backend Pod。
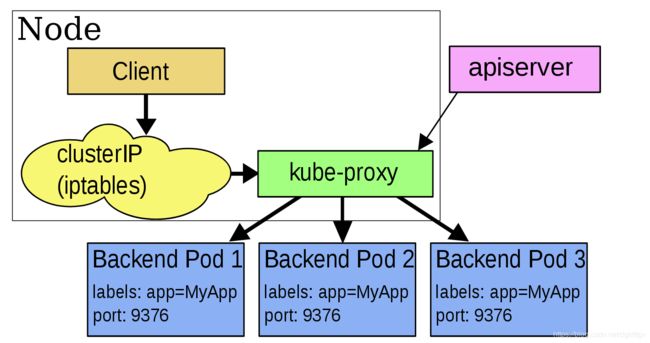
默认情况下,用户空间模式下的kube-proxy通过循环算法选择后端。
默认的策略是,通过 round-robin 算法来选择 backend Pod。
iptables 代理模式
这种模式,kube-proxy 会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会安装 iptables 规则,从而捕获到达该 Service 的 clusterIP 和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某个上面。 对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend 组合。
默认的策略是,kube-proxy 在 iptables 模式下随机选择一个 backend。
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理,而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptable s模式下运行,并且所选的第一个 Pod 没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败,并会自动使用其他后端 Pod 重试。
您可以使用 Pod readiness 探测器 验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着您避免将流量通过 kube-proxy 发送到已知已失败的Pod。
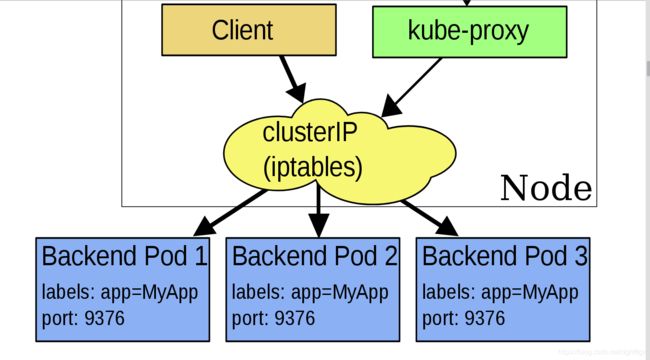
IPVS 代理模式
FEATURE STATE: Kubernetes v1.11 稳定
在 ipvs 模式下,kube-proxy监视Kubernetes服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。 该控制循环可确保 IPVS 状态与所需状态匹配。 访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS代理模式基于类似于 iptables 模式的 netfilter 挂钩函数,但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS提供了更多选项来平衡后端Pod的流量。 这些是:
rr: round-robinlc: least connection (smallest number of open connections)dh: destination hashingsh: source hashingsed: shortest expected delaynq: never queue
注意:要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前使 IPVS Linux 在节点上可用。
当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
发布服务 —— 服务类型
对一些应用(如 Frontend)的某些部分,可能希望通过外部Kubernetes 集群外部IP 地址暴露 Service。
Kubernetes ServiceTypes 允许指定一个需要的类型的 Service,默认是 ClusterIP 类型。
Type 的取值以及行为如下: * ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的 ServiceType。 * NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求 NodePort 服务。 * LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。 * ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。 没有任何类型代理被创建。
注意: 您需要 CoreDNS 1.7 或更高版本才能使用
ExternalName类型。
您也可以使用 Ingress 来暴露自己的服务。 Ingress 不是服务类型,但它充当集群的入口点。 它可以将路由规则整合到一个资源中,因为它可以在同一IP地址下公开多个服务。
NodePort 类型
如果将 type 字段设置为 NodePort,则 Kubernetes 控制平面将在 --service-node-port-range 标志指定的范围内分配端口(默认值:30000-32767)。 每个节点将那个端口(每个节点上的相同端口号)代理到您的服务中。 您的服务在其 .spec.ports[*].nodePort 字段中要求分配的端口。
如果您想指定特定的IP代理端口,则可以将 kube-proxy 中的 --nodeport-addresses 标志设置为特定的IP块。从Kubernetes v1.10开始支持此功能。
该标志采用逗号分隔的IP块列表(例如10.0.0.0/8、192.0.2.0/25)来指定 kube-proxy 应该认为是此节点本地的IP地址范围。
例如,如果您使用 --nodeport-addresses=127.0.0.0/8 标志启动 kube-proxy,则 kube-proxy 仅选择 NodePort Services 的环回接口。 --nodeport-addresses 的默认值是一个空列表。 这意味着 kube-proxy 应该考虑 NodePort 的所有可用网络接口。 (这也与早期的Kubernetes版本兼容)。
如果需要特定的端口号,则可以在 nodePort 字段中指定一个值。 控制平面将为您分配该端口或向API报告事务失败。 这意味着您需要自己注意可能发生的端口冲突。 您还必须使用有效的端口号,该端口号在配置用于NodePort的范围内。
使用 NodePort 可以让您自由设置自己的负载平衡解决方案,配置 Kubernetes 不完全支持的环境,甚至直接暴露一个或多个节点的IP
Service IP 地址
不像 Pod 的 IP 地址,它实际路由到一个固定的目的地,Service 的 IP 实际上不能通过单个主机来二、实验准备进行应答。 相反,我们使用 iptables(Linux 中的数据包处理逻辑)来定义一个虚拟IP地址(VIP),它可以根据需要透明地进行重定向。 当客户端连接到 VIP 时,它们的流量会自动地传输到一个合适的 Endpoint。 环境变量和 DNS,实际上会根据 Service 的 VIP 和端口来进行填充。
kube-proxy支持三种代理模式: 用户空间,iptables和IPVS;它们各自的操作略有不同。
Userspace
作为一个例子,考虑前面提到的图片处理应用程序。 当创建 backend Service 时,Kubernetes master 会给它指派一个虚拟 IP 地址,比如 10.0.0.1。 假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。 当代理看到一个新的 Service, 它会打开一个新的端口,建立一个从该 VIP 重定向到新端口的 iptables,并开始接收请求连接。
当一个客户端连接到一个 VIP,iptables 规则开始起作用,它会重定向该数据包到 Service代理 的端口。 Service代理 选择一个 backend,并将客户端的流量代理到 backend 上。
这意味着 Service 的所有者能够选择任何他们想使用的端口,而不存在冲突的风险。 客户端可以简单地连接到一个 IP 和端口,而不需要知道实际访问了哪些 Pod。
iptables
再次考虑前面提到的图片处理应用程序。 当创建 backend Service 时,Kubernetes 控制面板会给它指派一个虚拟 IP 地址,比如 10.0.0.1。 假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。 当代理看到一个新的 Service, 它会安装一系列的 iptables 规则,从 VIP 重定向到 per-Service 规则。 该 per-Service 规则连接到 per-Endpoint 规则,该 per-Endpoint 规则会重定向(目标 NAT)到 backend。
当一个客户端连接到一个 VIP,iptables 规则开始起作用。一个 backend 会被选择(或者根据会话亲和性,或者随机),数据包被重定向到这个 backend。 不像 userspace 代理,数据包从来不拷贝到用户空间,kube-proxy 不是必须为该 VIP 工作而运行,并且客户端 IP 是不可更改的。 当流量打到 Node 的端口上,或通过负载均衡器,会执行相同的基本流程,但是在那些案例中客户端 IP 是可以更改的。
IPVS
在大规模集群(例如10,000个服务)中,iptables 操作会显着降低速度。 IPVS 专为负载平衡而设计,并基于内核内哈希表。 因此,您可以通过基于 IPVS 的 kube-proxy 在大量服务中实现性能一致性。 同时,基于 IPVS 的 kube-proxy 具有更复杂的负载平衡算法(最小连接,局部性,加权,持久性)。
官网连接地址:https://kubernetes.io/zh/docs/concepts/services-networking/service/
二、实验准备
- 1.1、实验准备集起集群
- 1.2、验证实验环境是否可用
1.1、实验准备集起集群
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get node ##查看集群节点的情况
NAME STATUS ROLES AGE VERSION
server1 Ready master 7d21h v1.17.3
server3 Ready 7d21h v1.17.3
server4 Ready 7d21h v1.17.3
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get pod -n kube-system ##查看集群的环境信息
NAME READY STATUS RESTARTS AGE
coredns-9d85f5447-9p6b8 1/1 Running 102 6d6h
coredns-9d85f5447-nxwch 1/1 Running 104 6d1h
etcd-server1 1/1 Running 14 7d21h
kube-apiserver-server1 1/1 Running 23 7d21h
kube-controller-manager-server1 1/1 Running 52 7d21h
kube-flannel-ds-amd64-h6mpc 1/1 Running 7 7d16h
kube-flannel-ds-amd64-h8k92 1/1 Running 10 7d16h
kube-flannel-ds-amd64-w4ws4 1/1 Running 7 7d16h
kube-proxy-8hc7t 1/1 Running 7 7d21h
kube-proxy-ktxlp 1/1 Running 6 7d21h
kube-proxy-w9jxm 1/1 Running 5 7d21h
kube-scheduler-server1 1/1 Running 48 7d21h (保证所的服务都是Running)
1.2、验证实验环境是否可用
[kubeadm@server1 ~]$ vim deployment-example.yaml
apiVersion: apps/v1 ##控制器的版本
kind: Deployment ##控制器的类型
metadata:
name: nginx-deployment ##控制器的名称
spec:
replicas: 3 ##副本数为3这些pod由集群自动取分配给哪个节点
selector:
matchLabels:
app: nginx ##标签
template: ##模板
metadata: ##pod数据类型
labels:
app: nginx ##标签
spec:
containers: ##pod容器
- name: myapp ##名称
image: myapp ##v2镜像(名称要和仓库里的镜像名称相同)
ports: ##端口
- containerPort: 80 ##监听的端口名称
[kubeadm@server1 ~]$ kubectl create -f deployment-example.yaml
deployment.apps/nginx-deployment created
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-74748dcf96-b5qjg 1/1 Running 0 17s
nginx-deployment-74748dcf96-bf4ff 1/1 Running 0 17s
nginx-deployment-74748dcf96-qmfjs 1/1 Running 0 17s
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-74748dcf96-b5qjg 1/1 Running 0 17s
nginx-deployment-74748dcf96-bf4ff 1/1 Running 0 17s
nginx-deployment-74748dcf96-qmfjs 1/1 Running 0 17s
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74748dcf96-b5qjg 1/1 Running 0 54s 10.244.1.51 server4
nginx-deployment-74748dcf96-bf4ff 1/1 Running 0 54s 10.244.0.86 server1
nginx-deployment-74748dcf96-qmfjs 1/1 Running 0 54s 10.244.2.36 server3
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ curl 10.244.1.51
Hello MyApp | Version: v1 | Pod Name
[kubeadm@server1 ~]$
三、service的创建
- 1、查看帮助
- 2、创建一个简单的service
- 3、验证service服务能负载均衡
- 4、创建busyboxplus测试容器
1、查看帮助
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl explain service
KIND: Service
2、创建一个简单的service
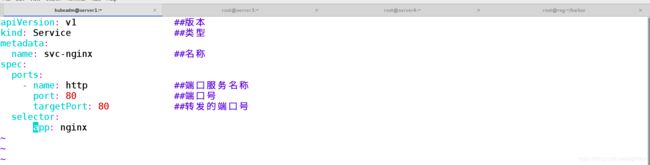
[kubeadm@server1 ~]$ vim svc.nginx.yaml
apiVersion: v1 ##版本
kind: Service ##类型
metadata:
name: svc-nginx ##名称
spec:
ports:
- name: http ##端口服务名称
port: 80 ##端口号
targetPort: 80 ##转发的端口号
selector:
app: nginx
~
![]()
2.2、测试:
[kubeadm@server1 ~]$ kubectl create -f svc.nginx.yaml ##创建
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get svc ##查看集群的鄂svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 7d22h
svc-nginx ClusterIP 10.97.167.21 80/TCP 115s
[kubeadm@server1 ~]$
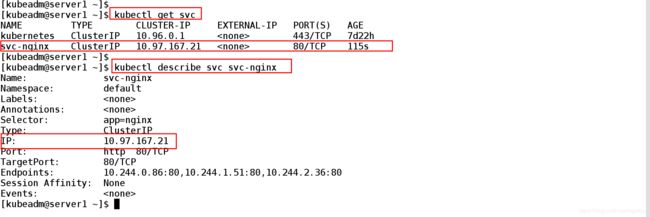
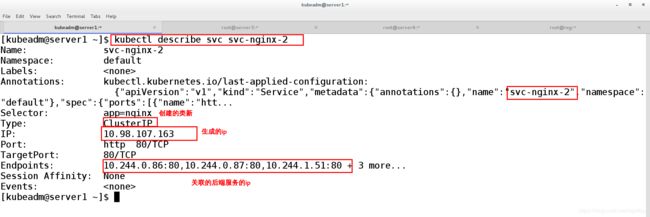
[kubeadm@server1 ~]$ kubectl describe svc svc-nginx ##查看svc日志
Name: svc-nginx
Namespace: default
Labels:
Annotations:
Selector: app=nginx
Type: ClusterIP
IP: 10.97.167.21 ##集群自动分配的服务IP地址
Port: http 80/TCP
TargetPort: 80/TCP ##目标端口
Endpoints: 10.244.0.86:80,10.244.1.51:80,10.244.2.36:80 ##后端ip对应的端口
Session Affinity: None
Events:
[kubeadm@server1 ~]$ 
2.3、生成10.97.167.21 ip
2.4、查看各个pod的标签
[kubeadm@server1 ~]$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-74748dcf96-b5qjg 1/1 Running 0 36m app=nginx,pod-template-hash=74748dcf96
nginx-deployment-74748dcf96-bf4ff 1/1 Running 0 36m app=nginx,pod-template-hash=74748dcf96
nginx-deployment-74748dcf96-qmfjs 1/1 Running 0 36m app=nginx,pod-template-hash=74748dcf96
2.5、测试外部端口ip的访问情况:
[kubeadm@server1 ~]$ kubectl get svc svc-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-nginx ClusterIP 10.97.167.21 80/TCP 8m54s
[kubeadm@server1 ~]$ curl 10.97.167.21 ##通过对外暴露的ip来访问后端的pod】
Hello MyApp | Version: v1 | Pod Name
[kubeadm@server1 ~]$ 
3、验证service服务能负载均衡
3.1、实验准备
拉取busyboxplus镜像
在私有镜像仓库的 管理节点上:
3.2、搜索镜像
[root@reg harbor]# docker search busyboxplus
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
radial/busyboxplus Full-chain, Internet enabled, busybox made f… 26 
3.3、拉取busyboxplus镜像
[root@reg harbor]# docker pull radial/busyboxplus
Using default tag: latest
latest: Pulling from radial/busyboxplus
a3ed95caeb02: Pull complete
c468b9f92624: Pull complete
1dc11860ba87: Pull complete
Digest: sha256:f26b8738e52cd1dba801eb1978804e663c48e1e9cff128ac9423218be83c55b8
Status: Downloaded newer image for radial/busyboxplus:latest
3.4、上传镜像
[root@reg ~]# docker tag radial/busyboxplus:latest reg.westos.org/library/busyboxplus
[root@reg ~]#
[root@reg ~]# docker push reg.westos.org/library/busyboxplus
The push refers to repository [reg.westos.org/library/busyboxplus]
5f70bf18a086: Mounted from library/ubuntu
774600fa57ae: Pushed
075a34aac01b: Pushed
latest: digest: sha256:9d1c242c1fd588a1b8ec4461d33a9ba08071f0cc5bb2d50d4ca49e430014ab06 size: 1353
[root@reg ~]#

4、创建busyboxplus测试容器
在busyboxplus上均衡的访问查看外部通过生成的ip访问后端的情况 实现了负载均衡
[kubeadm@server1 ~]$ kubectl run test --image=busyboxplus -it ##创建一个测试容器
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
If you don't see a command prompt, try pressing enter.
/ #
/ # curl 10.97.167.21
Hello MyApp | Version: v1 | Pod Name
/ #
/ # curl 10.97.167.21
Hello MyApp | Version: v1 | Pod Name
/ #
/ #
/ # curl 10.97.167.21/hostname.html
nginx-deployment-74748dcf96-bf4ff
/ #
/ # curl 10.97.167.21/hostname.html
nginx-deployment-74748dcf96-b5qjg ##均衡负载
/ #
/ # curl 10.97.167.21/hostname.html
nginx-deployment-74748dcf96-qmfjs
/ #
/ # curl 10.97.167.21/hostname.html
nginx-deployment-74748dcf96-bf4ff
4.2、kubernetes 提供了一个NDS插件
Service外部可以通过两种方式来访问后端的服务:
(1)、通过生成的ip
(2)、通过coredns nslookup svc-nginx生成的域名
做一个dns的解析
/ # nslookup svc-nginx ##busyboxplus测试页中查看DNS解析的域名
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: svc-nginx ##系统自动解析的域名
Address 1: 10.97.167.21 svc-nginx.default.svc.cluster.local
/ #
/ # curl svc-nginx/hostname.html ##通过系统解析的域名进行访问
nginx-deployment-74748dcf96-b5qjg
/ #
/ # curl svc-nginx/hostname.html
nginx-deployment-74748dcf96-qmfjs
/ #
/ # curl svc-nginx/hostname.html
nginx-deployment-74748dcf96-qmfjs
[kubeadm@server1 ~]$ kubectl get deployments.apps -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 2/2 2 2 7d22h

四、开启kube-proxy的ipvs模式
- 1、在节点上查看相关的iptables命令、安装 ipvsadm软件
- 2、开启kube-proxy的ipvs模式
- 3、查看ipvs策略是否生效
- 4、多创建服务(来查看节点的ip)
- 5、kube-proxy会在service创建后在宿主机添加网卡(kube-ipvs0)
- 6、验证与外部链接的轮询机制
service 是由kube-proxy组件 加上iptables 来共同实现的
kube-proxy通过iptables处理service的过程 ,需要在宿主机上 设置相当多的iptables规则 如果宿主机上有大量的pod,不断的刷新iptables规则会消耗大量的cpu资源
IPVS模式的service可以是k8s集群的支持更多的量级的pod
开启kube-proxy的ipvs模式
1、在节点上查看相关的iptables命令
ipvsadm 是拿内核来维护的
iptables -nL -t nat ##iptables的策略很多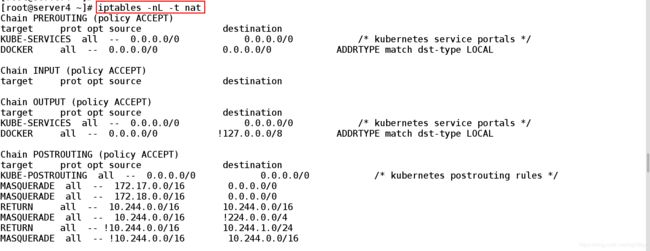
1.2、在各个节点上安装ipvsadm查看ipvs策略是否生效
yum install -y ipvsadm ##所有节点上都安装
server1上:
server3上:
server4上:
1.3、查看系统的服务信息
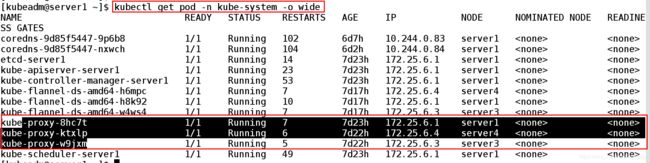
[kubeadm@server1 ~]$ kubectl get pod -n kube-system -o wide ##查看系统的服务信息
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-9d85f5447-9p6b8 1/1 Running 102 6d7h 10.244.0.83 server1
coredns-9d85f5447-nxwch 1/1 Running 104 6d2h 10.244.0.84 server1
etcd-server1 1/1 Running 14 7d23h 172.25.6.1 server1
kube-apiserver-server1 1/1 Running 23 7d23h 172.25.6.1 server1
kube-controller-manager-server1 1/1 Running 53 7d23h 172.25.6.1 server1
kube-flannel-ds-amd64-h6mpc 1/1 Running 7 7d17h 172.25.6.4 server4
kube-flannel-ds-amd64-h8k92 1/1 Running 10 7d17h 172.25.6.1 server1
kube-flannel-ds-amd64-w4ws4 1/1 Running 7 7d17h 172.25.6.3 server3
kube-proxy-8hc7t 1/1 Running 7 7d23h 172.25.6.1 server1
kube-proxy-ktxlp 1/1 Running 6 7d22h 172.25.6.4 server4
kube-proxy-w9jxm 1/1 Running 5 7d22h 172.25.6.3 server3
kube-scheduler-server1 1/1 Running 49 7d23h 172.25.6.1 server1
[kubeadm@server1 ~]
2、开启kube-proxy 的povs模式
在集群主配置节点上:
[kubeadm@server1 ~]$ kubectl -n kube-system edit cm kube-proxy ##改为IPVS mode"ipvs"
---
mode "ipvs" ##将mode "" 改为 mode "ipvs"
---

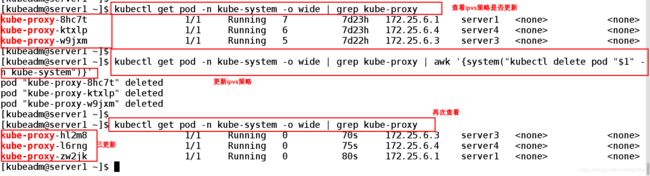
2.1、第一次用命令查看kube-proxy是否更新新
发现并没有更新
输入更新kube-proxy pod的命令
[kubeadm@server1 ~]$ kubectl get pod -n kube-system -o wide | grep kube-proxy ##查看ipvs策略是否更新的命令
[kubeadm@server1 ~]$ kubectl get pod -n kube-system -o wide | grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}' ##更新kube-proxy pod
pod "kube-proxy-8hc7t" deleted
pod "kube-proxy-ktxlp" deleted
pod "kube-proxy-w9jxm" deleted ##已经生效
[kubeadm@server1 ~]$
2.2、查看ipvs策略是否生效
在server4上:
[root@server4 ~]# ipvsadm -ln ##查看ipvsdm策略
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 172.25.6.1:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr
-> 10.244.0.83:53 Masq 1 0 0 ##rr负载均衡的轮询机制
-> 10.244.0.84:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.0.83:9153 Masq 1 0 0
-> 10.244.0.84:9153 Masq 1 0 0
TCP 10.97.167.21:80 rr
-> 10.244.0.86:80 Masq 1 0 0
-> 10.244.1.51:80 Masq 1 0 0
-> 10.244.2.36:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.0.83:53 Masq 1 0 0
-> 10.244.0.84:53 Masq 1 0 0
[root@server4 ~]#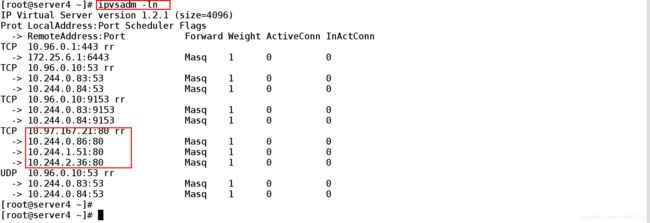
2.3、测试:
查看iptables 的策略已经很少了
[root@server4 ~]# systemctl start firewalld
[root@server4 ~]#
[root@server4 ~]# iptables -nL -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
PREROUTING_direct all -- 0.0.0.0/0 0.0.0.0/0
PREROUTING_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0
PREROUTING_ZONES all -- 0.0.0.0/0 0.0.0.0/0
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
OUTPUT_direct all -- 0.0.0.0/0 0.0.0.0/0
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
POSTROUTING_direct all -- 0.0.0.0/0 0.0.0.0/0
POSTROUTING_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0
POSTROUTING_ZONES all -- 0.0.0.0/0 0.0.0.0/0
RETURN all -- 10.244.0.0/16 10.244.0.0/16
MASQUERADE all -- 10.244.0.0/16 !224.0.0.0/4
RETURN all -- !10.244.0.0/16 10.244.1.0/24
MASQUERADE all -- !10.244.0.0/16 10.244.0.0/16
Chain OUTPUT_direct (1 references)
target prot opt source destination
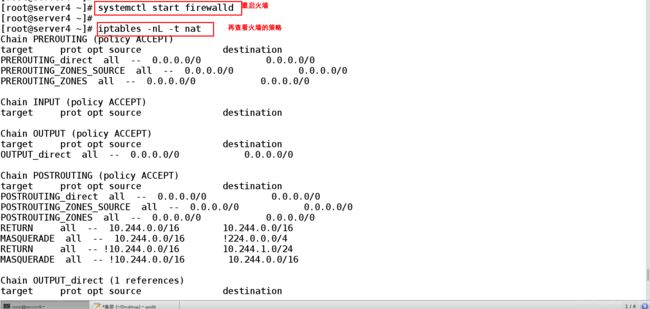
2.5、各个节点上的内核一定要装有ip_vs_rr 这是ipvsadm生效的前提
[root@server4 ~]# lsmod | grep ip_vs ##查看看节点的ip_vs_rr
ip_vs_rr 12600 5
ip_vs 141432 7 ip_vs_rr
nf_conntrack 133053 6 ip_vs,nf_nat,nf_nat_ipv4,xt_conntrack,nf_nat_masquerade_ipv4,nf_conntrack_ipv4
libcrc32c 12644 4 xfs,ip_vs,nf_nat,nf_conntrack
3、查看ipvs策略是否生效
# 重启火墙策略
[root@server1 ~]# systemctl restart firewalld ##重启动火墙
[root@server1 ~]#
[root@server1 ~]#
[root@server1 ~]# su - kubeadm
Last login: lun mar 2 04:25:04 EST 2020 on pts/0
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ vim deployment-example.yaml ##将文件中的副本个数修改为6![]()
3.1、将副本的个数改为6个

3.2、查看对外暴露的ip
3.3、测试:
在server4上进行验证
查看ipvs策略是否生效
[root@server4 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 172.25.6.1:6443 Masq 1 1 0
TCP 10.96.0.10:53 rr
-> 10.244.0.83:53 Masq 1 0 0
-> 10.244.0.84:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.0.83:9153 Masq 1 0 0
-> 10.244.0.84:9153 Masq 1 0 0
TCP 10.97.167.21:80 rr ##发现ipvs策略已经生效
-> 10.244.0.86:80 Masq 1 0 0
-> 10.244.0.87:80 Masq 1 0 0
-> 10.244.1.51:80 Masq 1 0 0
-> 10.244.1.53:80 Masq 1 0 0
-> 10.244.2.36:80 Masq 1 0 0
-> 10.244.2.37:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.0.83:53 Masq 1 0 0
-> 10.244.0.84:53 Masq 1 0 0
[root@server4 ~]#
3.4、设置ipvs策略后
启动ipvs后会再每个节点上添加一个ip
[kubeadm@server1 ~]$ kubectl get svc ##创建ipvs策略完后这个服务的时候获取10.97.167.21 加给各个节点查看生成的ip
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 7d23h
svc-nginx ClusterIP 10.97.167.21 80/TCP 90m
[kubeadm@server1 ~]$ 
3.5、测试
在server3上
输入ip addr show
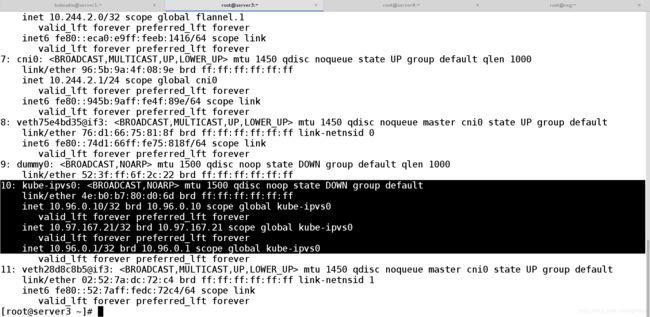
server4上和server3上的内容一样
4、多创建服务(来查看节点的ip) 一个文件中创建多个清单用--- 来分割
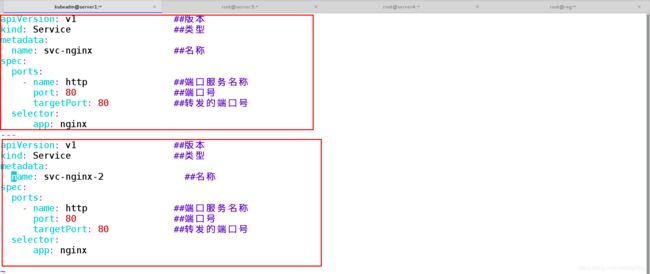
[kubeadm@server1 ~]$ vim svc.nginx.yaml
apiVersion: v1 ##版本
kind: Service ##类型
metadata:
name: svc-nginx ##名称
spec:
ports:
- name: http ##端口服务名称
port: 80 ##端口号
targetPort: 80 ##转发的端口号
selector:
app: nginx
---
apiVersion: v1 ##版本
kind: Service ##类型
metadata:
name: svc-nginx-2 ##名称
spec:
ports:
- name: http ##端口服务名称
port: 80 ##端口号
targetPort: 80 ##转发的端口号
selector:
app: nginx(资源清单中创建了两个服务)
4.2、测试:
[kubeadm@server1 ~]$ kubectl apply -f svc.nginx.yaml ##创建
service/svc-nginx unchanged
service/svc-nginx-2 created
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get svc ##查看两个service服务所对应的ip
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 8d
svc-nginx ClusterIP 10.97.167.21 80/TCP 101m
svc-nginx-2 ClusterIP 10.98.107.163 80/TCP 45s
[kubeadm@server1 ~]$ vim s 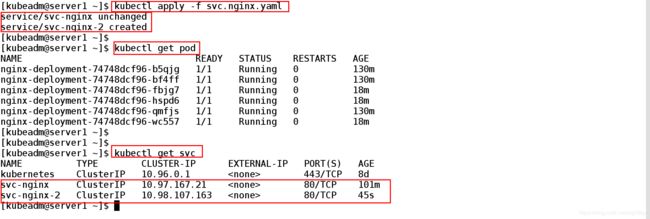
4.3、两个服务调度6个节点
5、kube-proxy会在service创建后在宿主机添加网卡(kube-ipvs0)
在server4进行测试
在IPVS模式下,kube-proxy会在service创建后 在宿主机添加一个网卡:kube-ipvs0 并分配service IP
(只要是k8s的service方式都可以看iptables里边的策略 通过kube-proxy的动态监听service的创建过程 然后在更新的ipvsadm策略 )
输入:ip addr show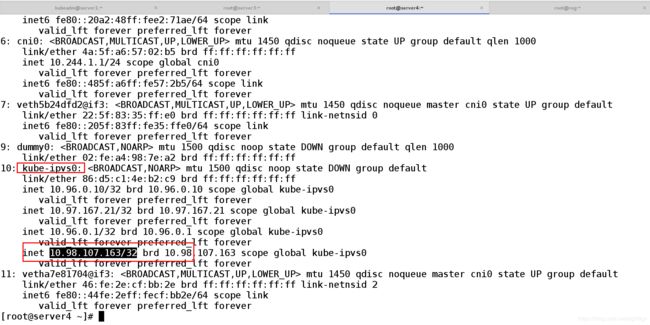
5.1、查看ipvs策略是否生效
[root@server4 ~]# ipvsadm -ln ##查看ipvs策略
6、验证与外部链接的轮询机制
6.1、将副本个数改为3个
[kubeadm@server1 ~]$ vim deployment-example.yaml
[kubeadm@server1 ~]$ kubectl delete -f deployment-example.yaml
deployment.apps "nginx-deployment" deleted
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl create -f deployment-example.yaml
deployment.apps/nginx-deployment created
[kubeadm@server1 ~]$
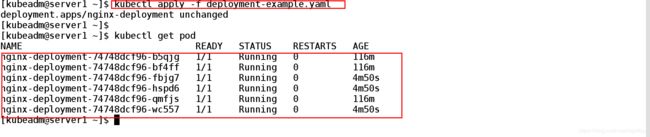
[kubeadm@server1 ~]$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-74748dcf96-4f668 0/1 ContainerCreating 0 8s
nginx-deployment-74748dcf96-gbzfn 1/1 Running 0 8s
nginx-deployment-74748dcf96-trxtp 1/1 Running 0 8s![]()
 、
、
6.2、测试:
查看各个pod对应的 名称方便后边实验的观察
[kubeadm@server1 ~]$ kubectl get pod ##查看各个pod的名称
NAME READY STATUS RESTARTS AGE
nginx-deployment-74748dcf96-4f668 1/1 Running 0 34m
nginx-deployment-74748dcf96-gbzfn 1/1 Running 0 34m
nginx-deployment-74748dcf96-trxtp 1/1 Running 0 34m
test-7db5bb79c9-mzsgw 1/1 Running 4 24m ##busyboxplus的pod名称 
6.3、查看对外暴露的ip
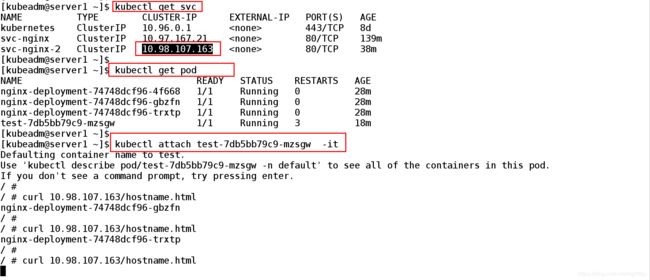
[kubeadm@server1 ~]$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 8d
svc-nginx ClusterIP 10.97.167.21 80/TCP 145m ##对外暴露的ip
svc-nginx-2 ClusterIP 10.98.107.163 80/TCP 45m
[kubeadm@server1 ~]$
6.4、进入busybosplus测试容器中
[kubeadm@server1 ~]$ kubectl attach test-7db5bb79c9-mzsgw -it ##进入busyboxplus测试页面
Defaulting container name to test.
Use 'kubectl describe pod/test-7db5bb79c9-mzsgw -n default' to see all of the containers in this pod.
If you don't see a command prompt, try pressing enter.
/ #
/ # curl 10.98.107.163/hostname.html
nginx-deployment-74748dcf96-gbzfn
/ # curl 10.98.107.163/hostname.html
nginx-deployment-74748dcf96-trxtp
/ # curl 10.98.107.163/hostname.html
nginx-deployment-74748dcf96-4f668
/ # curl 10.98.107.163/hostname.html
6.5、在server4上:
在server4上查看ipvsadm 策略
[root@server4 ~]# ipvsadm -ln ##查看ipvs策略
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 172.25.6.1:6443 Masq 1 1 0
TCP 10.96.0.10:53 rr
-> 10.244.0.83:53 Masq 1 0 0
-> 10.244.0.84:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.0.83:9153 Masq 1 0 0
-> 10.244.0.84:9153 Masq 1 0 0
TCP 10.97.167.21:80 rr ##对外暴露的端口的调度下边的3个pod后端
-> 10.244.0.88:80 Masq 1 0 0
-> 10.244.1.54:80 Masq 1 0 0
-> 10.244.2.38:80 Masq 1 0 0
TCP 10.98.107.163:80 rr #########
-> 10.244.0.88:80 Masq 1 0 0
-> 10.244.1.54:80 Masq 1 0 0
-> 10.244.2.38:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.0.83:53 Masq 1 0 0
-> 10.244.0.84:53 Masq 1 0 0
[root@server4 ~]#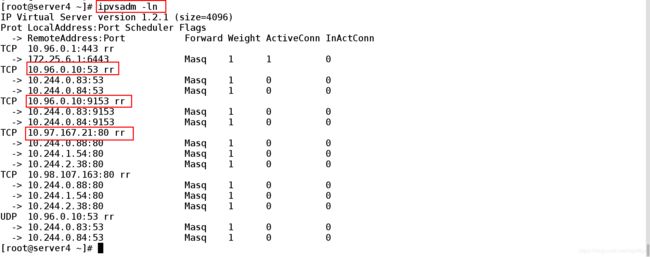
五、 Flannel vxlan模式跨主机通信原理(跨物理节点)
- 1、工作原理:
- 2、查看网桥的工作原理
- 3、各个节点的ip_forward 一定要打开
- 4、查看各个节点的pod ip对应的mac地址、以及mac和flannel.1
1、工作原理:
vxlan是linux内核功能
网络转递的原理 从server1的进来 pod ——> cni0 ——>flannel.1——> eth0 从eth0出去 ——>server3、server4——> eth0
——>flannel.1(VTEP隧道的几个虚拟端点用于解包、封包)——> cni0 ——> pod (本机pod网络、cni0本机的网关 )
k8s内部工作原理 :kubelet系统会自动生成 cni0再由cni0和 pod进行通讯
网桥的工作原理:
查看本机的网桥
创建service 系统会在每个节点上自动生成 一个cni0网桥 是每个节点上都会有的
2、查看网桥的工作原理
[kubeadm@server1 ~]$ brctl show ##查看网桥的命令
bridge name bridge id STP enabled interfaces
br-e0d0c6390100 8000.0242a33641bc no
cni0 8000.3a468cf23c96 no veth0e376a81 创建service在系统中会自动生成cni0 的网前链接
veth50cc6a4c
veth55717f74
docker0 8000.02423716b9e1 no
docker_gwbridge 8000.0242c6d404c6 no
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$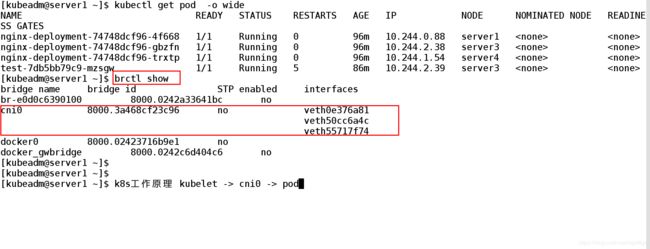
2.2、查看cni0(一般cni0和本机的pod的网关相连 cni0可以通过网关联系到pod)
[kubeadm@server1 ~]$ ip addr show cni0
11: cni0: mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 3a:46:8c:f2:3c:96 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 scope global cni0 ##网关为 10.244.0.1/24
valid_lft forever preferred_lft forever
inet6 fe80::3846:8cff:fef2:3c96/64 scope link
valid_lft forever preferred_lft forever
[kubeadm@server1 ~]$ 
3、各个节点的ip_forward 一定要打开(net.ipv4.ip_forward = 1)否则无法进行各个物理节点之间的信息的转递
[root@server4 ~]# sysctl -a | grep ip_forward
net.ipv4.ip_forward = 1
net.ipv4.ip_forward_use_pmtu = 0
[root@server4 ~]#
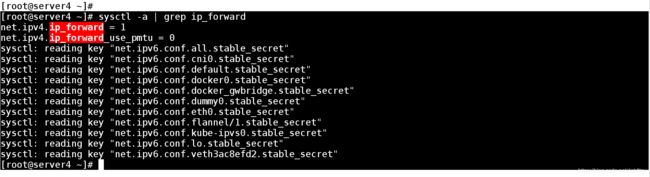
其他节点上都一样
4、查看各个节点的pod ip对应的mac地址、以及mac和flannel.1
拿到mac地址就可以 通过flannel.1的VIEP 封装包
(10.244.0.88(server1) ——> 10.244.2.38(server3)) ——> (flannel.1 VTEP)——> eth0(server1) ——>eth0(server3)不知道server3的ip地址
[kubeadm@server1 ~]$ arp -an
? (172.25.6.3) at 52:54:00:81:71:3b [ether] on eth0
? (10.244.0.86) at 2a:ab:83:de:5e:3f [ether] on cni0
? (10.244.1.0) at 22:a2:48:e2:71:ae [ether] PERM on flannel.1
? (10.244.0.88) at 26:78:1f:d2:ce:a6 [ether] on cni0
? (10.244.2.0) at ee:a0:e9:eb:14:16 [ether] PERM on flannel.1
? (172.25.6.250) at 1c:39:47:b8:3d:82 [ether] on eth0
? (172.25.6.4) at 52:54:00:56:d1:1f [ether] on eth0
? (169.254.169.254) at on eth0
? (10.244.0.84) at fe:8e:cb:d9:19:b6 [ether] on cni0
? (10.244.0.83) at c6:7d:c2:90:de:ae [ether] on cni0
? (172.25.6.2) at 52:54:00:d1:93:6e [ether] on eth0
[kubeadm@server1 ~]$ 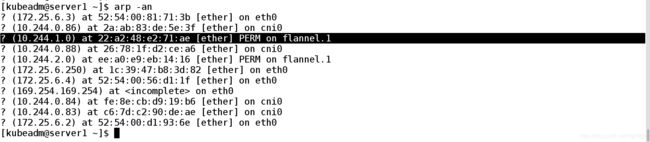
4.2、各个网关和flannel.1向对应
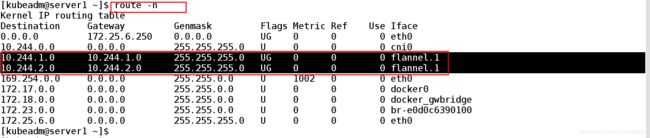

4.3、mac地址 flannel.1和eth0的关系
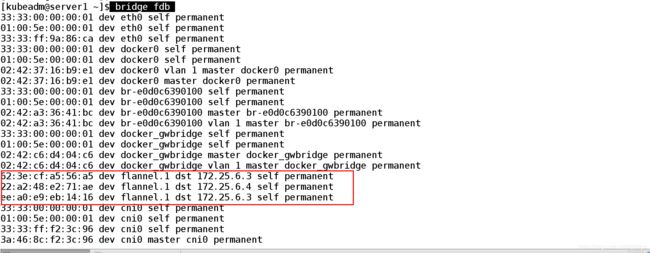
[kubeadm@server1 ~]$ bridge fdb ##转发数据库通过mac地址和外部的接口相连 网络二层可以互相通信
62:3e:cf:a5:56:a5 dev flannel.1 dst 172.25.6.3 self permanent
22:a2:48:e2:71:ae dev flannel.1 dst 172.25.6.4 self permanent
ee:a0:e9:eb:14:16 dev flannel.1 dst 172.25.6.3 self permanent ##通过flannel.1拿到server3的eth0
六、NodePort
- 1、创建 NodePort
- 2、测试
NodePort方式的方式是以节点的ip和暴露端口的方式 来访问的
NodePort方式暴露内部节点的方式 给集群外的节点访问的
1、创建 NodePort
[kubeadm@server1 ~]$ kubectl delete svc svc-nginx-2 ##清空上一个实验的信息
service "svc-nginx-2" deleted
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ vim svc.nginx.nodeport.yaml ##编辑文件信息
apiVersion: v1 ##版本
kind: Service ##类型
metadata:
name: svc-nginx-2 ##名称
spec:
ports:
- name: http ##端口服务名称
port: 80 ##端口号
targetPort: 80 ##转发的端口号
selector:
app: nginx
type: NodePort ##网络的链接类型
[kubeadm@server1 ~]$ kubectl create -f svc.nginx.nodeport.yaml ##创建
service/svc-nginx-2 created
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get svc ##查看端口向外部暴露的NodePort 端口
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 8d
svc-nginx ClusterIP 10.97.167.21 80/TCP 4h42m
svc-nginx-2 NodePort 10.97.127.77 80:30235/TCP 19s ##系统会自动分配80:30235端口
[kubeadm@server1 ~]$

2、测试:

2.2、在server4上查看ipvs的规则是否被添加
ipvsadm -ln 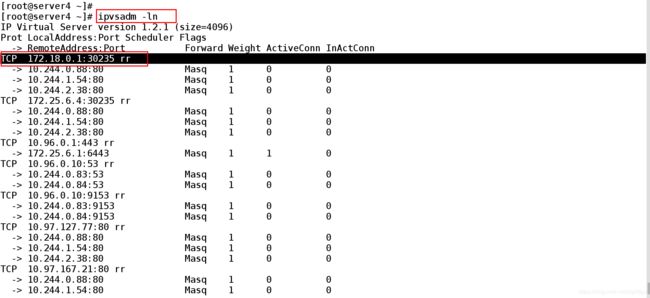
2.3、在真机上测试:
[root@foundation6 kiosk]# curl 172.25.6.3:30235 ##以节点ip加端口的方式进行访问
Hello MyApp | Version: v1 | Pod Name
[root@foundation6 kiosk]#
2.4、在网页上访问:
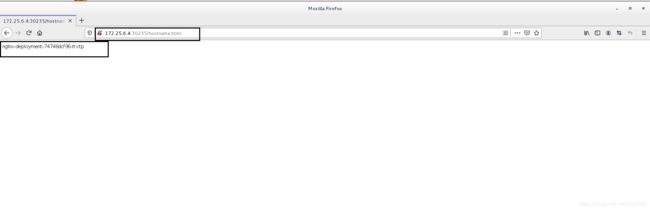
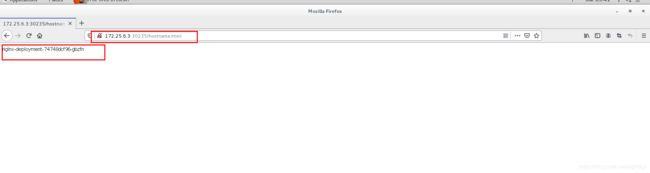
输入:172.25.6.1:30235
访问到的是后端都3个节点 对应的pod 实现了负载均衡
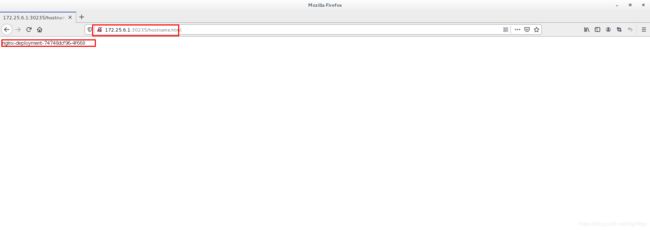
七、LoadBalancer
从外部访问的Service的第二种方式 是用于共有云上的Kubernetes服务,这时候,可以指定一个LoadBalancer类型的Service。
在service提交后,Kubernetes就会调用CloudProvider 在共有云上 你可以创建一个负载均衡服务,并且把代理的pod的IP 地址配置给负载均衡服务做后缀。(共有云、阿里云、亚马逊)。
在外部的公有云上才可以创建 (因为要收费)
八、ExternalName
- 1、创建ExternalName
- 2、测试
ExtenlName:将服务通过DNS CNAME 记录方式转发到指定的域名
在访问的时候service
client ——> test.westos.org (service) ——> pod(n) 直接用ip访问应用里边的地址可能会改变
1、创建ExternalName
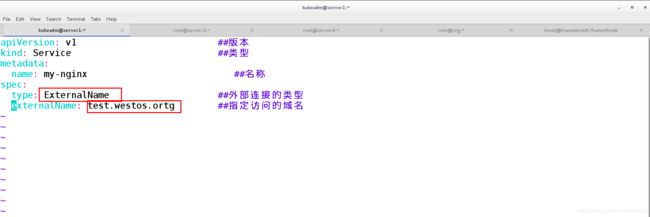
[kubeadm@server1 ~]$ vim ex-service.yaml
apiVersion: v1 ##版本
kind: Service ##类型
metadata:
name: my-nginx ##名称
spec:
type: ExternalName ##外部连接的类型
externalName: test.westos.ortg ##指定访问的域名
[kubeadm@server1 ~]$ kubectl create -f ex-service.yaml
service/my-nginx created
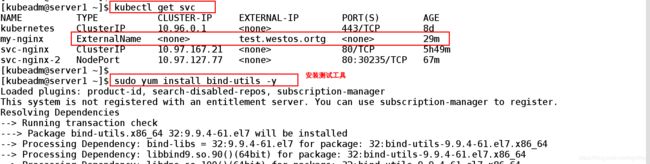
[kubeadm@server1 ~]$ kubectl get svc ##查看生成的svc信息
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 8d
my-nginx ExternalName test.westos.ortg 29m
svc-nginx ClusterIP 10.97.167.21 80/TCP 5h49m
svc-nginx-2 NodePort 10.97.127.77 80:30235/TCP 67m
[kubeadm@server1 ~]$
2、测试:
[kubeadm@server1 ~]$ sudo yum install bind-utils -y ##安装测试软件
[kubeadm@server1 ~]$ kubectl get svc -n kube-system ##查看dns 对应的ClusterIP
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 8d
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ dig -t A test.westos.ortg @10.96.0.10 ##测试
; <<>> DiG 9.9.4-RedHat-9.9.4-61.el7 <<>> -t A test.westos.ortg @10.96.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 23243
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;test.westos.ortg. IN A
;; Query time: 1255 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Mon Mar 02 09:35:40 EST 2020
;; MSG SIZE rcvd: 45
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels:
Annotations:
Selector:
Type: ExternalName
IP:
External Name: test.westos.ortg
Session Affinity: None
Events:
[kubeadm@server1 ~]$ 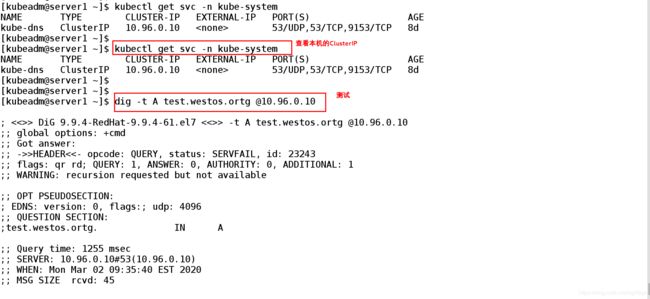
2.2、测试:
通过访问内部pod镜像名称的 方式进行访问
[kubeadm@server1 ~]$ dig -t A my-nginx.default.svc.cluster.local. @10.96.0.10
; <<>> DiG 9.9.4-RedHat-9.9.4-61.el7 <<>> -t A my-nginx.default.svc.cluster.local. @10.96.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11757
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;my-nginx.default.svc.cluster.local. IN A
;; ANSWER SECTION:
my-nginx.default.svc.cluster.local. 30 IN CNAME test.westos.ortg.
;; Query time: 98 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Mon Mar 02 09:44:15 EST 2020
;; MSG SIZE rcvd: 127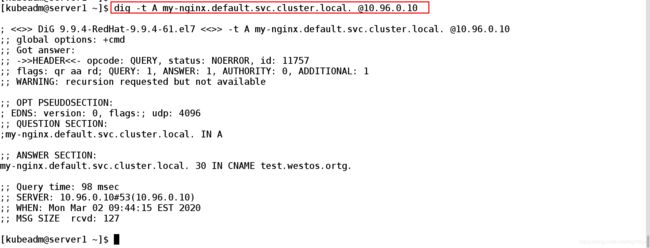
九、创建一个对外暴露的自定义IP
- 1、创建service
- 2、测试
- 3、查看系统自动分配的ip
1、创建service
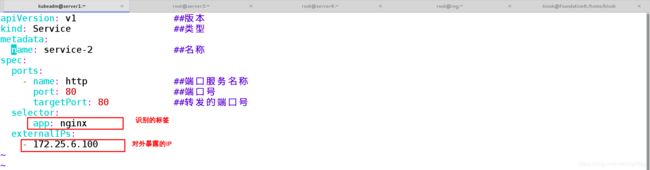
[kubeadm@server1 ~]$ vim service-2.yaml
apiVersion: v1 ##版本
kind: Service ##类型
metadata:
name: service-2 ##名称
spec:
ports:
- name: http ##端口服务名称
port: 80 ##端口号
targetPort: 80 ##转发的端口号
selector:
app: nginx
externalIPs:
- 172.25.6.100 ##创建一个供外部访问的共有ip
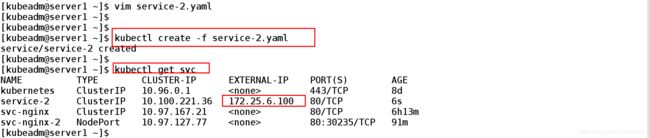
[kubeadm@server1 ~]$ kubectl create -f service-2.yaml ##创建
service/service-2 created
[kubeadm@server1 ~]$
[kubeadm@server1 ~]$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 8d
service-2 ClusterIP 10.100.221.36 172.25.6.100 80/TCP 6s
svc-nginx ClusterIP 10.97.167.21 80/TCP 6h13m
svc-nginx-2 NodePort 10.97.127.77 80:30235/TCP 91m
[kubeadm@server1 ~]$
2、测试:
查看配置的ip是否生效
kubeadm@server1 ~]$ kubectl describe svc service-2
Name: service-2
Namespace: default
Labels:
Annotations:
Selector: app=nginx
Type: ClusterIP
IP: 10.100.221.36
External IPs: 172.25.6.100 ##对外开放的ip
Port: http 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.0.88:80,10.244.1.54:80,10.244.2.38:80 ##通过对外开放的ip可以访问到三个后端
Session Affinity: None
Events:
[kubeadm@server1 ~]$
2.2、在正机上:
访问成功
[root@foundation6 ~]# ping 172.25.6.100 ##再真机上查看是否可以和创建的ip进行连接
PING 172.25.6.100 (172.25.6.100) 56(84) bytes of data.
64 bytes from 172.25.6.100: icmp_seq=1 ttl=64 time=0.227 ms
64 bytes from 172.25.6.100: icmp_seq=2 ttl=64 time=0.244 ms
64 bytes from 172.25.6.100: icmp_seq=3 ttl=64 time=0.181 ms
64 bytes from 172.25.6.100: icmp_seq=4 ttl=64 time=0.284 ms
^C
--- 172.25.6.100 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2999ms
rtt min/avg/max/mdev = 0.181/0.234/0.284/0.036 ms
[root@foundation6 ~]#
[root@foundation6 ~]# curl 172.25.6.100 ##访问172.25.6.100 查看到后端的pod
Hello MyApp | Version: v1 | Pod Name
[root@foundation6 ~]# curl 172.25.6.100
Hello MyApp | Version: v1 | Pod Name
[root@foundation6 ~]#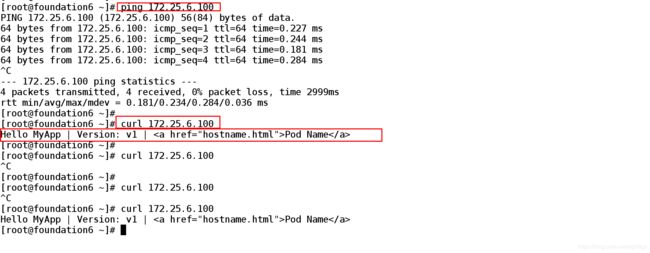
2.3、在server4上:
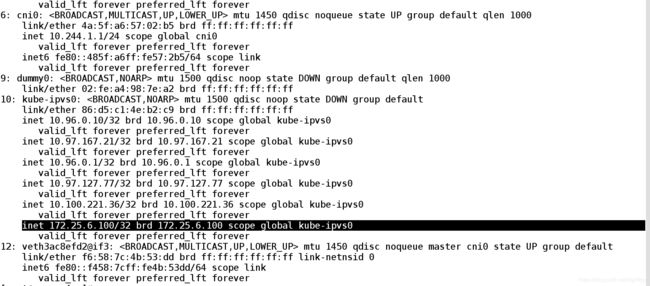
[root@server4 ~]# ip addr ##查看172.25.6.100是否在每个节点上都会生效
[root@server4 ~]# ipvsadm -ln ##查看ipvs策略
***
TCP 172.25.6.100:80 rr ##172.25,6.100已经加入到ipvs策略中
-> 10.244.0.88:80 Masq 1 0 0
-> 10.244.1.54:80 Masq 1 0 0
-> 10.244.2.38:80 Masq 1 0 0
***
3、查看系统自动分配的ip