生成对抗网络(四)-----------WGAN-GP
一、WGAN的分析
从我们WGAN的实现结果来看,WGAN可以很好的生成图像。因此,我们来分析一下W距离和生成图像之间的关系。理论上距离越近,图像生成质量越高。就说明WGAN的效果很好。在WGAN的论文式样中对三种架构进行了实验。第一种是生成器采用普通的感知机。第二组是生成器采用标准的DCGAN。第三组是生成器和判别器都采用MLP。实验结果如下图:
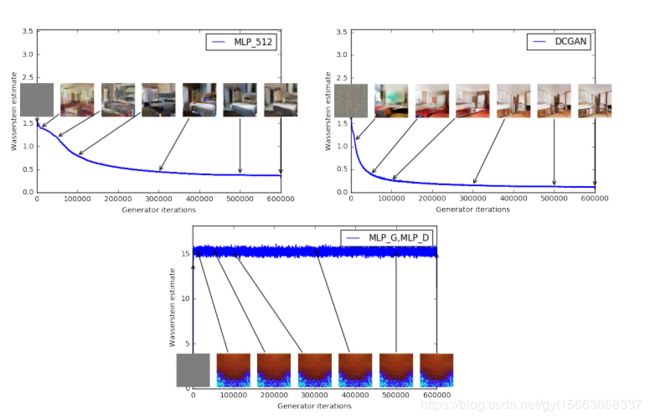
从第一和第二组实验中可以看出,随着W的距离降低图像的生成质量也越来越好。并且随着迭代次数的上升,一开始W距离降低,然后慢慢就趋于平稳。最优一组交过不佳,随着迭代次数上升。W距离并未下降,但是生成图像质量也没有变好。说明了WGAN的理论是正确的。同样的在原始的GAN上采用与上面相同的三组配置进行比较。实验结果如下图。可以看到JS散度与图像的质量并没有一个正向的关联。
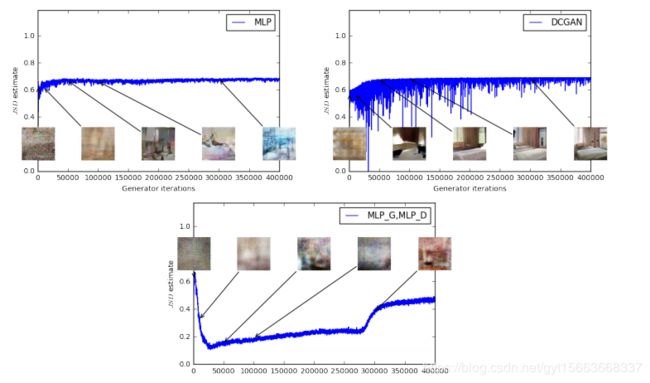
并且经过大量的实验,也可看出WGAN具有比原始GAN更稳定的生成能力,在最优架构的情况下也许无法体现出来,但是一旦中间出现问题。使用WGAN在一定程度上避免生成图像质量的急速下降。
GAN还存在一个问题就是模式崩溃的问题,模式崩溃就是指生成器不具备多样性,往往会不断重复同样的图像或者同类型的图像作为生成结果。在实际问题中,虽然完全的模式崩溃不多见,但是部分模式崩溃还是很普遍。部分模式崩溃是指生成网络只产生真实数据分布中的一部分数据,或者漏掉一小部分类型的数据。而WGAN在实验中表示可以解决模式崩溃问题。虽然没有理论证明,但是几乎在WGAN中没有出现模式崩溃问题。
二、WGAN的改进--WGAN-GP
在WGAN中为了满足1-Lipschitz条件,使用的方法是权值剪裁,把整个网络的权重限定在一个大小范围内。但是这样会产生一些问题。第一个问题就是权值剪裁限制了网络的表现能力。由于网络权重被限制在了固定的范围内,神经网络就很难模拟出复杂的函数。第二个问题就是梯度爆炸和梯度消失。为了解决WGAN的问题。研究者提出了一种改进方法WGAN-GP。使用梯度惩罚的方法替代权值剪裁。我们需要满足函数在任意位置上的梯度都小于1。所以可以考虑根据网络的输入来限制对应判别器的输出。对此我们更新目标函数,添加惩罚项。
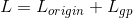
![]()
![]()
对于上述惩罚项中的采样分布![]() ,它的范围是真实数据分布与生成数据分布中间的分布。具体的实践方法是在真实数据分布和生成数据分布各进行一次采样,然后这两个点连线上再做一次随机采样。就是我们要的惩罚项。WGAN对四种GAN进行了实验对比。如下图:
,它的范围是真实数据分布与生成数据分布中间的分布。具体的实践方法是在真实数据分布和生成数据分布各进行一次采样,然后这两个点连线上再做一次随机采样。就是我们要的惩罚项。WGAN对四种GAN进行了实验对比。如下图:

从上图可以看出。WGAN-GP的效果更好。
三、WGAN-GPU的keras实现
1. 导包
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers.merge import _Merge
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import RMSprop
from functools import partial
import keras.backend as K
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)2. 取权重平均样本
class RandomWeightedAverage(_Merge):
"""提供一个真实样本与生成样本的权重平均值"""
def _merge_function(self, inputs):
alpha = K.random_uniform((32, 1, 1, 1))
return (alpha * inputs[0]) + ((1 - alpha) * inputs[1])3. 初始化模型
class WGANGP():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
# 优化
self.n_critic = 5
optimizer = RMSprop(lr=0.00005)
# 构建生成器和判别器
self.generator = self.build_generator()
self.critic = self.build_critic()
# 训练判别器时,冻结生成器
self.generator.trainable = False
# 真实数据输入
real_img = Input(shape=self.img_shape)
# 噪声输入
z_disc = Input(shape=(100,))
# 基于噪声生成虚假图像
fake_img = self.generator(z_disc)
# 判断样本是真是假
fake = self.critic(fake_img)
valid = self.critic(real_img)
# 构建权重平均图像
interpolated_img = RandomWeightedAverage()([real_img, fake_img])
# 得到验证结果
validity_interpolated = self.critic(interpolated_img)
# 构建惩罚项损失函数
partial_gp_loss = partial(self.gradient_penalty_loss,
averaged_samples=interpolated_img)
partial_gp_loss.__name__ = 'gradient_penalty' # Keras requires function names
self.critic_model = Model(inputs=[real_img, z_disc],
outputs=[valid, fake, validity_interpolated])
self.critic_model.compile(loss=[self.wasserstein_loss,
self.wasserstein_loss,
partial_gp_loss],
optimizer=optimizer,
loss_weights=[1, 1, 10])
# 训练生成器,固定判别器
self.critic.trainable = False
self.generator.trainable = True
# 噪声
z_gen = Input(shape=(100,))
# 生成图像
img = self.generator(z_gen)
# 判别结果
valid = self.critic(img)
# 定义模型
self.generator_model = Model(z_gen, valid)
self.generator_model.compile(loss=self.wasserstein_loss, optimizer=optimizer)
4. 惩罚损失
def gradient_penalty_loss(self, y_true, y_pred, averaged_samples):
"""
Computes gradient penalty based on prediction and weighted real / fake samples
"""
gradients = K.gradients(y_pred, averaged_samples)[0]
# compute the euclidean norm by squaring ...
gradients_sqr = K.square(gradients)
# ... summing over the rows ...
gradients_sqr_sum = K.sum(gradients_sqr,
axis=np.arange(1, len(gradients_sqr.shape)))
# ... and sqrt
gradient_l2_norm = K.sqrt(gradients_sqr_sum)
# compute lambda * (1 - ||grad||)^2 still for each single sample
gradient_penalty = K.square(1 - gradient_l2_norm)
# return the mean as loss over all the batch samples
return K.mean(gradient_penalty)
5. W损失
def wasserstein_loss(self, y_true, y_pred):
return K.mean(y_true * y_pred)6. 构建生成器
def build_generator(self):
model = Sequential()
model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=4, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=4, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(self.channels, kernel_size=4, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
7. 构建判别器
def build_critic(self):
model = Sequential()
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
8. 训练网咯
def train(self, epochs, batch_size, sample_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
# Adversarial ground truths
valid = -np.ones((batch_size, 1))
fake = np.ones((batch_size, 1))
dummy = np.zeros((batch_size, 1)) # Dummy gt for gradient penalty
for epoch in range(epochs):
for _ in range(self.n_critic):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# Sample generator input
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Train the critic
d_loss = self.critic_model.train_on_batch([imgs, noise],
[valid, fake, dummy])
# ---------------------
# Train Generator
# ---------------------
g_loss = self.generator_model.train_on_batch(noise, valid)
# Plot the progress
print ("%d [D loss: %f] [G loss: %f]" % (epoch, d_loss[0], g_loss))
# If at save interval => save generated image samples
if epoch % sample_interval == 0:
self.sample_images(epoch)
9. 展示数据
def sample_images(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 1
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/mnist_%d.png" % epoch)
plt.close()
10 运行代码
if __name__ == '__main__':
wgan = WGANGP()
wgan.train(epochs=30000, batch_size=32, sample_interval=100)