mysql事务、隔离级别、长事务的处理、mvcc
事物的概念:
4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
1) 原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。redoLog实现
2)一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。undoLog实现
3)隔离性(isolation)。多个事物之间,一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。锁实现
4)持久性(durability)。事物的结果,持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。redoLog实现
Java初级控制:
ct.setAutoCommit(false);//把事物设为不自动提交
PreparedStatement ps=ct.prepareStatement(sql);
PreparedStatement ps2=ct.prepareStatement(sql1);
ps.executeUpdate();
ps2.executeUpdate();
ct.commit();//ct事物统一提交
★事物隔离级别
事物的隔离级别用于确定事物的隔离程度
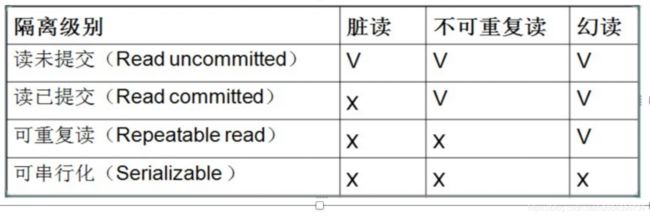
第1级别:Read Uncommitted(读取未提交内容)
(1)所有事务都可以看到其他未提交事务的执行结果
(2)本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
(3)该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
第2级别:Read Committed(读取提交内容)
(1)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
(2)它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变
(3)这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。
|——>导致这种情况的原因可能有:(1)有一个交叉的事务有修改和删除并commit了,导致了数据的改变;(2)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit
(4)InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题
第3级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别
(2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
(3)此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行;假设两个事务,事物1开始select where id=3为空,事务1插入了id=3的并提交,事务2 select where id=3仍为空,但是insert id=3的时候会报错,这就是幻读。
第4级别:Serializable(可串行化)
(1)最高的隔离级别:一个个事务排成序列的形式。事务一个挨一个执行,等待前一个事务执行完,后面的事务才可以顺序执行
(2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
(3)在这个级别,可能导致大量的超时现象和锁竞争
不同的事物隔离级别导致的现象:
脏读:一个事物读取另一个事物尚未提交的修改;
实例:a事物做了修改但还没有提交,此时b事务读取到了a所做的修改,并且a事务后来发生了回滚,发生脏读。通过设置隔离级别为读已提交来解决。
不可重复读:同一查询在同一事物中多次进行,由于其他事物所做的修改或删除,每次返回不同的结果集。
实例:a事务执行查询语句sql1,b事务所做的修改刚好会影响a事务的sql1的执行结果,b事务提交,a事务再次执行sql1,a事务中sql1两次结果不同。解决方式是采用mvcc,即每个事务对应一个版本号,当前事务仅仅读取当前事务对应版本号的数据
幻读:同一查询在同一事物中多次进行,由于其他事物所做的插入操作,无法执行插入
实例:a事务查询表,发现只有id 1-5的记录,b事务也查询表,同样发现只有id1-5的记录,然后a事务会插入id为6的数据并提交,此时b事务再次查询,依然是只有id 1-5的数据,这里不会发生不可重复读的问题,接着插入id为6的数据,会失败,这就是幻读。解决方式是:
1)可重复读隔离级别(间隙锁)+事务a中用select for update或select lock in share mode来查询,此时mysql在可重复读级别下会在每行加上行锁,并且在1-5之外加上间隙锁,b就不能能够执行insert操作,这样这样可以避免幻读。
2)直接将隔离级别设置为串行化。所有事物串行执行。
“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。数据库实现事务隔离的方式,基本可以分为以下两种。
一种是在读取数据前,对其加锁,阻止其他事务对数据进行修改。
另一种是不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度,好像是数据库可以提供同一数据的多个版本,因此,这种技术叫做数据多版本并发控制(MultiVersion Concurrency Control,简称MVCC或MCC),也经常称为多版本数据库。
数据库的事务隔离级别越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的,同时,不同的应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用对“不可重复读”和“幻读”并不敏感,可能更关心数据并发访问的能力。
为了解决“隔离”与“并发”的矛盾,ISO/ANSI SQL92定义了4个事务隔离级别,每个级别的隔离程度不同,允许出现的副作用也不同,应用可以根据自己业务逻辑要求,通过选择不同的隔离级别来平衡"隔离"与"并发"的矛盾
现在看看如何把事物的隔离级别设为串行化 serializable
■设置一个事物的隔离级别
set transaction isolation level read committed;(默认)
set transaction isolation level serializable;(手动设置)
set transaction read only;
■设置整个会话的隔离级别
alter session set isolation_level serializable;
alter session set isolation_level read commited;
长事务的危害与避免
危害
1)长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。
2)长事务还占用锁资源,阻碍别的事务的执行和处理,也可能拖垮整个库,
避免方案
这个问题,我们可以从应用开发端和数据库端来看。
首先,从应用开发端来看:
-
确认是否使用了 set autocommit=0。这个确认工作可以在测试环境中开展,把 MySQL 的 general_log 开起来,然后随便跑一个业务逻辑,通过 general_log 的日志来确认。一般框架如果会设置这个值,也就会提供参数来控制行为,你的目标就是把它改成 1。
-
确认是否有不必要的只读事务。有些框架会习惯不管什么语句先用 begin/commit 框起来。我见过有些是业务并没有这个需要,但是也把好几个 select 语句放到了事务中。这种只读事务可以去掉。
-
业务连接数据库的时候,根据业务本身的预估,通过 SET MAX_EXECUTION_TIME 命令,来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。(为什么会意外?在后续的文章中会提到这类案例)
其次,从数据库端来看:
-
监控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警 / 或者 kill;
-
Percona 的 pt-kill 这个工具不错,推荐使用;
-
在业务功能测试阶段要求输出所有的 general_log,分析日志行为提前发现问题;
-
如果使用的是 MySQL 5.6 或者更新版本,把 innodb_undo_tablespaces 设置成 2(或更大的值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。
通过mvcc实现可重复读和读已提交
事务 每个事务都有一个事务号,每一个事务都会对应一个快照,没有事务需要对应快照的时候,快照会被删除;
某行记录如果对应多个事务都会有多个快照,快照之间用事务的事务号区分,快照之间的切换可以通过undo log来实现,不是直接copy一份数据;
读已提交和可重复读的区别是,读已提交是读最新提交的事务号对应的快照中的实际值,而可重复读是读自身事务号对应的快照中存储的值;即:
对于可重复读,查询只承认在事务启动前就已经提交完成的数据;
对于读提交,查询只承认在语句启动前就已经提交完成的数据;
但是可重复读有一个例外,那就是在更新数据的时候,不能再在历史版本上更新了,否则别的事务的更新就丢失了,因此,事务更新会在当前最新提交事务的基础上进行的操作。当然如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
这里就用到了这样一条规则:更新数据都是先读后写的,而这个读,只能读当前最新提交事务对应的值,称为“当前读(current read)”。
mvcc再理解:
a=1
事物1 开始
事物2 开始,修改a=2, commit
事物1 读a,a为多少?
此时a为2,因为在此之前事物1没有读过a,所以没有做版本号的控制。所以a读到的结果是a=2