Hadoop 稀疏矩阵乘法的MapReduce计算
我们在用矩阵处理真实数据的时候,一般都是非常稀疏矩阵,为了节省存储空间,通常只会存储非0的数据。
下面我们来做一个稀疏矩阵:
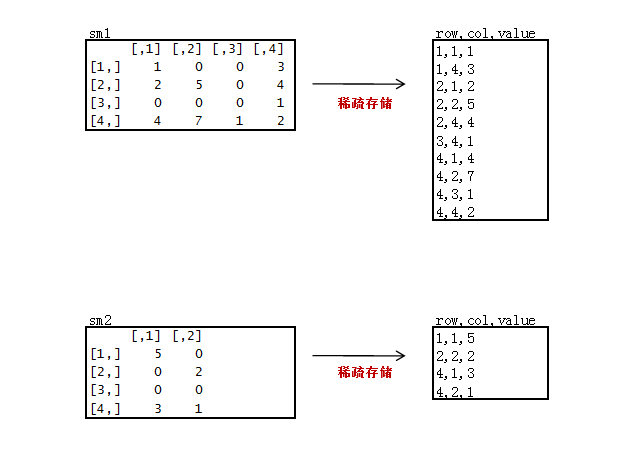
新建2个稀疏矩阵数据文件sm1.csv, sm2.csv
只存储非0的数据,3列存储,第一列“原矩阵行”,第二列“原矩阵列”,第三列“原矩阵值”。
sm1.csv
1,1,1
1,4,3
2,1,2
2,2,5
2,4,4
3,4,1
4,1,4
4,2,7
4,3,1
4,4,2
sm2.csv
1,1,5
2,2,2
4,1,3
4,2,1代码:
package org.edu.bupt.xiaoye.sparsemartrix;
import java.io.IOException;
import java.net.URI;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SparseMartrixMultiply {
public static class MyMapper extends Mapper {
private String flag; // m1 or m2
private int rowNumA = 4; // 矩阵A的行数,因为要在对B的矩阵处理中要用
private int colNumA = 4;// 矩阵A的列数
private int rolNumB = 4;
private int colNumB = 2;// 矩阵B的列数
private static final Text k = new Text();
private static final Text v = new Text();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getName();// 判断读的数据集
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] records = value.toString().split(",");
int x = Integer.parseInt(records[0]);
int y = Integer.parseInt(records[1]);
int num = Integer.parseInt(records[2]);
if (flag.equals("m1")) {
String[] vs = value.toString().split(",");
for (int j = 0; j < colNumB; j++) {
k.set(x + "," + (j + 1));
v.set("A" + ":" + y + "," + num);
context.write(k, v);
}
} else if (flag.equals("m2")) {
for (int j = 0; j < rowNumA; j++) {
k.set((j + 1) + "," + y);
v.set("B:" + x + "," + num);
context.write(k, v);
}
}
}
}
public static class MyReducer extends
Reducer {
private static IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
/*
* 这里和一般矩阵不同
* 一般矩阵中,当进行第二次reduce方法调用的时候,会对数组a和b的所有元素都重新赋值
* 而在稀疏矩阵中,不会对数组的所有元素重新赋值,从而会发生上次调用reduce方法残留的数组元素值对这一次reduce产生影响。
*/
int[] a = new int[4];
int[] b = new int[4];
for (Text value : values) {
String[] vs = value.toString().split(":");
if (vs[0].equals("A")) {
String[] ints = vs[1].toString().split(",");
a[Integer.parseInt(ints[0]) - 1] = Integer
.parseInt(ints[1]);
} else {
String[] ints = vs[1].toString().split(",");
b[Integer.parseInt(ints[0]) - 1] = Integer
.parseInt(ints[1]);
}
}
// 用矩阵A的行乘矩阵B的列
int sum = 0;
for (int i = 0; i < 4; i++) {
sum += a[i] * b[i];
}
v.set(sum);
context.write(key, v);
}
}
public static void run(Map path) throws Exception {
String input = path.get("input");
String output = path.get("output");
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(input), conf);
final Path outPath = new Path(output);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
conf.set("hadoop.job.user", "hadoop");
// conf.set("mapred.job.tracker", "10.103.240.160:9001");
final Job job = new Job(conf);
FileInputFormat.setInputPaths(job, input);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1);// 设置个数为1
FileOutputFormat.setOutputPath(job, outPath);
job.waitForCompletion(true);
}
}
package org.edu.bupt.xiaoye.sparsemartrix;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
public class MainRun {
public static final String HDFS = "hdfs://10.103.240.160:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
martrixMultiply();
}
public static void martrixMultiply() {
Map path = new HashMap();
path.put("input", HDFS + "/usr/hadoop/SparseMatrix");// HDFS的目录
path.put("output", HDFS + "/usr/hadoop/SparseMatrix/output");
try {
SparseMartrixMultiply.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
} 在reducer中定义数组a和b的时候,不要定义成MyMapper类成员。我就是因为这里定义成了成员变量导致出了错误调了好久。
/*
* 这里和一般矩阵不同
* 一般矩阵中,当进行第二次reduce方法调用的时候,会对数组a和b的所有元素都重新赋值
* 而在稀疏矩阵中,不会对数组的所有元素重新赋值,从而会发生上次调用reduce方法残留的数组元素值对这一次reduce产生影响。
*/