MySql知识点整理
事务:
ACDI:
原子性(atomicity):指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(consistency):事务必须使数据库从一个一致性状态变换到另外一个一致性状态,数据一致(如 转账总数不变)。
持久性(durability):一个事务一旦被提交,所做的修改就会永久保存到数据库中,无法回滚。
隔离性(isolation):一个事务所做的修改在最终提交之前,对其他事务是不可见的。
隔离级别:
读未提及(READ-UNCOMMITTED):从一个事务读取另一个未提交的事务,会存在脏读现象
读已提交(READ-COMMITTED):在一个事务A中新增或修改记录时,提交之前,在另一个事务B中是查询不到改动记录的,当事务A提交后,事务B中查询得到变化,存在不可重复读(两次读不一致,可通过锁行解决)和幻读问题
可重复读(REPEATABLE-READ,mysql默认):从一个事务A中修改一条数据,另一个事务B中查询,在事务A提交之前读取的都是修改之前的记录,重复读取得到的记录是一样的,解决了不可重读。当从一个事务A中新增一条数据并提交,在另一个事务B查询看不到新增记录,当update表时(条件要能包含新增的记录),在查询,可以看到记录,称之为幻读(可通过锁表解决)。
串行化(SERIALIZABLE):不支持并发,事务串行化顺序执行,可以避免脏读、不可重复读、幻读,但是性能很低
事务传播行为:
PROPAGATION_REQUIRED:如果存在一个事务则支持当前事务,否则开启一个新的事务。spring默认事务传播特性
PROPAGATION_SUPPORTS:如果存在一个事务则支持当前事务,否则不开启事务
PROPAGATION_MANDATORY:如果存在一个事务则支持当前事务,否则抛异常
PROPAGETION_REQUIRES_NEW:总是开启一个新的事务,将旧事务挂起
PROPAGETION_NOT_SUPPORTED:总是非事务的执行,并挂起任何存在的事务
PROPAGATION_NEVER:总是非事务的执行,如果存在活动事务则抛出异常
PROPAGATION_NESTED:如果一个活动事务存在,则运行在一个嵌套的事务中,如果没有活动事务,则按照PROPAGETION_REQUIRED属性执行
索引:
索引类型:
普通索引:查询效率高
唯一索引:查询效率高且列值唯一(可以有null)
主键索引:查询效率高且列值唯一(不能有null)且一张表只有一个主键索引
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并(使用多个单列索引组合搜索)
全文索引:对文本的内容进行分词,进行搜索
索引分类:
HASH:
仅能满足 等于 和 in 操作,不能使用范围查询
无法处理排序运算
对于组合索引,无法使用部分索引,是根据全量组合索引算出的hash值
hash索引不能避免表的扫描,查找后还要通过访问表中的实际数据进行比较才得到结果
hash碰撞比较大的时候性能会降低,可能会比B-Tree索引效率低
BTREE:
是B+树(所有数据都存放在子节点)
在INNODB中有两种形态,如果是主键的话,子节点存放的数据包含索引键的数据以及其他字段数据,否则只存放主键的值
MyISAM里,子节点存放的是指向数据文件里的对应数据行信息
FULLTEXT:
全文索引,目前只有MyISAM引擎支持,且只有CHAR、VARCHAR、TEXT上可以创建全文索引
RTREE:
仅支持geometry(几何对象)数据类型,优势在于范围查找
mysql引擎:
常用四种,在5.6版本支持的有八种 ,可以用show engines查看支持的引擎
MyISAM:
拥有较高的查询、插入速度,有单独变量记录整表的行数,支持全文索引,可以索引blob和text列,但不支持事务,不支持外键、不支持行锁
InnoDB:
支持事务、行锁、外键,查询整表记录时需要扫描全表,不支持全文索引、不支持blob和text列,存储大小是MyISAM(256TB)的四分之一(64TB)
聚簇索引(主键的索引):一个表只能有一个聚簇索引,叶子结点记录的是行数据。耗费空间但查询的快
非聚簇索引(二级索引):叶子结点保存的数据是主键的值,在通过主键的值去聚簇索引中查找数据
Memory:
将表中的数据存储到内存中,支持包含null列的索引,通常只存放临时数据,数据量不大且不需要较高的安全性
Archive:
如果只有INSERT和SELECT操作,可以使用Archive,支持高并发的插入操作,单本身不是事务安全的,适用于存储归档数据,比如记录日志信息

主键:
如果定义主键,InnoDB会选择主键作为聚集索引
如果没显示定义主键,InnoDB会选择第一个不包含null值的唯一索引作为主键
如果没有上面的索引,InnoDB会选择内置的6字节长的rowID作为隐含的聚集索引
如果使用自增主键,每次插入新的记录,B+Tree会顺序在后面添加,如果使用非自增主键,插入则是随机的,会频繁移动节点位置
视图:
也被称作虚表,是一组数据的逻辑表示形式,本质是一条select语句,本身不包含任何数据,只展现映射到基表的数据
可以通过视图限制数据访问,以及简化复杂操作查询,create view as select * ...,使用视图如表一样,对于增删改有如下限制:
如果基表中有非空列,且对视图不可见,无法insert;
如果视图中包含函数、表达式、分组、distinct、rownum等,不允许DML操作;
通过join的无法删除或新增(亲测)
存储过程、触发器、函数:
存储过程:在创建时进行编译,提高执行速度;可以将复杂逻辑进行封装。在不同数据库中移植性差且会使业务逻辑更复杂,增加系统维护难度
函数:提高重用性|可读性以及sql的可移植性,无需修改sql即只保证函数正确即可。可以提高执行速度减少网络流量。
触发器:包含DML(insert update delete)触发器和DDL(create alter drop)触发器;而且包含DML完成后触发以及替代DML操作。DDL没有替代操作
union\union all:
必须保证各个select的结果有相同个数的列且类型相同
union: 对两个结果集进行并集操作,会去重,同时进行默认规则的排序
union all:对两个结果集进行并集操作,不会去重,不进行排序
char\varchar:
varvhar\char里面的数字在4.0版本以下指的是字节(每个汉字3字节),5.0版本以上指的是字符,varchar最大是65532字节(两个字节存长度)
如果字符类型为gbk,每个字符最多占两个字节,如果是utf8则每个字符最多占三个字节。
行长度限制是65535,即一条记录所有字段加起来的总和。
char:定长,效率高。范围是0-255。保存char值时,会将小于长度的右侧进行空格填充,比较占用空间
varchar:不定长,效率偏低。最长是64K,包含其他列,是可变字符串,多余一两个字节记录长度
blob:需要1-4个字节记录值的长度,超大会被截断,可以存储二进制大对象,比如图片。排序大小写敏感
text:需要1-4个字节记录值的长度,排序大小写不敏感。
分页:
mysql:
使用limit,如limit 0,20 从第一条开始,查询20条记录。第一个参数是起始索引,第二个参数是查询的记录数。如果只有一个的话,则代表查询前多少条。
oracle:
使用rownum,在无order by时需要两层嵌套,有order by时需要三层嵌套。ID从1开始,且使用 > 或 between..and.. 。
不允许大于比较的原因是:
rownum是对结果集加的一个伪列,是符合条件的结果的序号。当使用> 时,先查出来结果集,然后判断条件> n时,第一行的rownum是1 不符合,然后第二行地rownum设置1 不符合,以此类
推,所以大于的就得不到记录,只有>=1 这种情况应该是没问题的(推测),但是下次换页就有问题了。
不使用order by则需要两层,使用order by则需要三层。示例如下:
select tab.* from (select rownum as rowid, u.* from user u where rownum<=20) tab where tab.rowid >=11
select tab.* from (select rownum as rowid, u.* from (select * from user order by id) u where rownum<=20) tab where tab.rowid >=11
排序:
多个排序字段逗号分隔
asc: 升序,从小到大,默认排序方式
desc: 降序,从大到小
连接:
内连接:只匹配连接的行 A join B on
左外连接:包含左边的全部行及右表中匹配的行 A left (outer) join B on
右外连接:包含右边的全部行及左表中匹配的行 A right (outer) join B on
全外连接:包含左右两表的全部行 A full (outer) join B on
交叉连接:生成笛卡尔积,没有条件 A join B
范式:
第一范式:
确保每列保持原子性,即所有字段都是不可分解的原子值,比如要把地址拆成省份、城市、详细地址等。
第二范式:
确保表中的每列都和主键相关,即一个表中只能保存一种数据,比如订单和商品联合主键,保存的信息不能包含订单和商品的信息,需要拆分出来一个商品表和关系表
第三范式:
确保每列都和主键列直接相关,而不是间接相关,比如订单表里要包含用户的信息,通过用户ID进行外键关联,不能再包含用户名的信息
sql优化:
where的执行顺序是从右到左的,应再最右侧使用能过滤掉大部分记录的条件
from后的表管理是从右向左解析的,大表放在右边
select 查询条件使用具体的值来代替*,减少多余字段网络传输
避免频繁创建和删除临时表,减少系统资源的消耗
删除临时表时可以先truncate table 后drop table,避免表锁定时间长
避免大事务操作,可以提高系统并发能力
适当建立索引,可以在频繁频繁查询但修改较少的地方增加索引
索引失效的原因:
对索引列判null,会放弃使用索引进行全表扫描
类型不匹配会放弃使用索引进行全表扫描
使用!= <> 会放弃使用索引进行全表扫描,主键索引应该还会使用
使用or连接条件会放弃使用索引进行全表扫描,可以用union all替换,or 两侧都是使用索引应该是会使用索引的
使用in\not in 需要注意,需要in里的类型和字段类型一致,不一致的话普通索引会失效,普通索引对not in不生效
like在左侧不使用%还会用到索引
在=号左侧使用函数、表达式、算术运算会放弃使用索引进行全表扫描
复合索引匹配最左边,遇到范围查询列之后索引失效(a=2 and b between 1 and 2 and c=3 复合索引abc c 不会使用索引)排序也会使用索引,与where后顺序无关
临时表:
创建时增加 TEMPORARY 关键字,当断开连接时自定删除表并释放空间
注意点:
like使用的通配符 %代表匹配任意多 _ 代表匹配一个字符
count(列) 不计算包含null值的
使用B+tree不是Btree因为B+树的深度一定,查询更稳定,且磁盘读写代价更低(内部节点没有存放数据信息,节点更小,在单位范围内存储的节点数量更多,树深度更低)
主从复制:
复制方式:同步复制(效率低下,基本没用)、异步复制(效率高,msql默认配置)、半同步复制(保证有一个slaves操作成功即返回)
主节点挂掉:可以通过在应用程序内配置数据库的域名,当主挂掉将子节点升级为master,并将原master域名指向新的master, 重新建立连接。
读写分离:主写从读,配置多数据源
分库分表:垂直分库(按业务模块按表拆分出来),水平分表(依据数据关系,把同一个表的数据拆分到各个库,比如按ID取余)
oracle有分区表,按时间或数量进行分区,不要和分表搞混
事务一致性:
CAP(帽子)理论:
C(Consistency):一致性。多个副本能保证数据一致的特性
A(Availability):可用性。服务一致处于可用状态,不会中断,必须在有限的时间内返回结果
P(Partition tolerance):分区容错性。分布式系统在遇到任何网络分区故障的时候仍然可以对外提供服务,比如数据库分区,某一个区
的网络被隔离,仍然可以提供其他分区的服务。(一般来说是必须的)
一个分布式系统不可能同时满足这三个特性,最多只能同时满足两个
CA : 当数据库只有一个时,可以保证数据一致性可可用性,当网络把数据库隔离时,满足不了分区容错
CP:即保证数据强一致,当出现阻塞时会导致可用性不满足
AP:即不保证数据强一致时,不会出现阻塞状态,可以保证系统的可用性
BASE理论:
BA (Basically Available 基本可用):出现不可预知的错误后还是能用,比如时间变长或降级等
S (Soft state 软状态):允许存在中间状态的数
E (Eventually consistent 最终一致性):不能一直处于软状态,最终要达到数据一致
XA:
是一个两阶段提交的协议,大部分商业数据库都实现了XA的接口
第一阶段:事务协调器要求每个涉及到事务的数据库预提交(procommit)此操作,并反映是否可以提交
第二阶段:事务协调器要求每一个数据库提交数据
2PC:
牺牲了一些性能尽量保证数据是一致的
准备阶段:事务协调者向所有参与者询问是否可以提交事务,等待参与者答复,如果参与者超时,则认为是NO
提交阶段:当所有参与者均反馈YES,则向所有参与者发起提交请求,参与者提交事务并反馈结果。当存在参与者反馈NO时,向所有
参与者发起回滚请求,参与者回滚到undo状态,并反馈结果,等待反馈结果会存在阻塞状态
3PC:
CanCommit: 与2PC的准备阶段相似,询问参与者是否可以提交事务,等待回复,超时则认为NO
PreCommit: 当所有参与者反馈YES,则发起预提交,参与者执行事务请求并记录到undo和redo中但不提交,反馈结果,参与者阻塞等待协调者请求,等待超时则认为是commit
DoCommit: 当所有参与者都PreCommit都反馈成功,下发DoCommit(commit\rollback),等待结果,超时则认为成功,参与者接收到请求执行commit或rollback
解决了2PC中提交阶段的阻塞问题,以及协调者单点故障的问题
TCC:
Try: 主要做业务的检查以及资源预留
Confirm: 做确认提交的逻辑,Try执行成功后开始执行Confirm,默认Confirm阶段不会出错的
Cancel:业务执行错误时,需要回滚执行业务的取消,Try中的预留资源的释放
属于应用层的一种补偿方式,需要写好多补偿代码
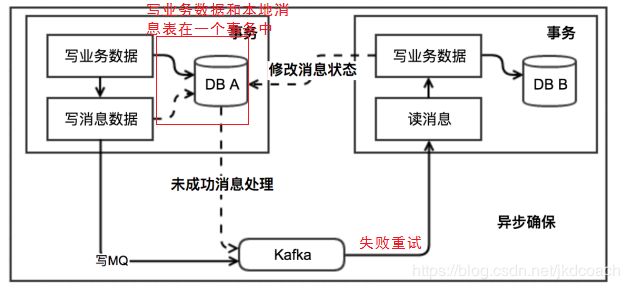
本地消息表:
分布式时,在各个数据库中维护一张本地的消息表,通过各个本地事务保证局部一致,在通过消息队列进行发送消息异步通知,保证最终一致性