郝健: Linux内存管理学习笔记-第2节课

摘要
slab、/proc/slabinfo和slabtop
用户空间malloc/free、内核空间kmalloc/kfee与Buddy的关系
mallopt
vmalloc
Linux为应用程序分配内存的lazy行为
内存耗尽(OOM)、oom_score和oom_adj
Android进程生命周期与OOM
1. slab、/proc/slabinfo和slabtop
Buddy的最小单位是页(4k),无论是内核还是用户程序都会申请一些更小粒度的内存,所以在Linux内核中类似于堆的内存申请都会基于二次分配器slab。


slab原理:比如申请8 byte内存,就从Buddy申请到4K,然后将4K分成很多个8 byte,每一个8 byte就叫做Slab的一个object。
slab机制的实现算法有slab,slub,slob。
Linux会针对一些小粒度内存的申请以及一些常规数据结构的内存申请做slab,可以cat /proc/slabinfo查看。
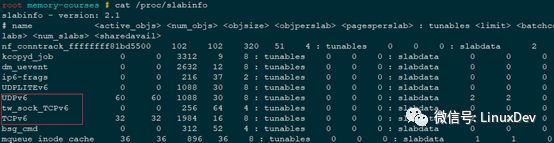

可以看出slab主要分为两类:一类是内核里常用的数据结构,如TCPv6,UDPv6等,由于内核经常要申请和释放这类数据结构,所以就针对这些数据结构做一个slab,然后再次申请这类结构体时就总是从这个slab里来申请一个object(使用kmem_cache_alloc()申请)。另一类是一些小粒度的内存申请,如slabinfo中的kmalloc-16,kmalloc-32等(使用kmalloc()申请)。
注意:slab是只针对内核空间的,与用户空间没有关系。
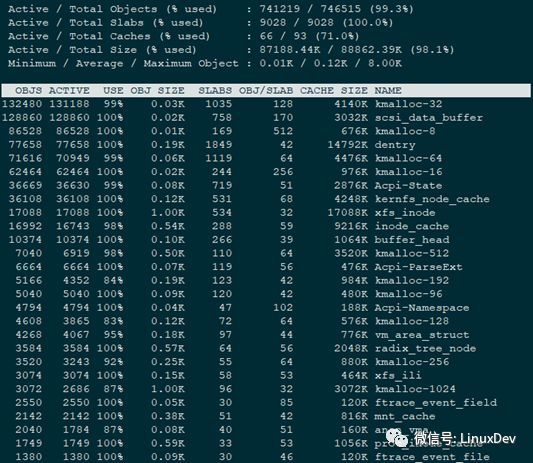
slabtop
slabtop displays detailed kernel slab cache information in real time. It displays a listing of the top cachessorted by one of the listed sort criteria. It also displays a statistics header filled with slab layer information.
2. 用户空间malloc/free、内核空间kmalloc/kfee与Buddy的关系
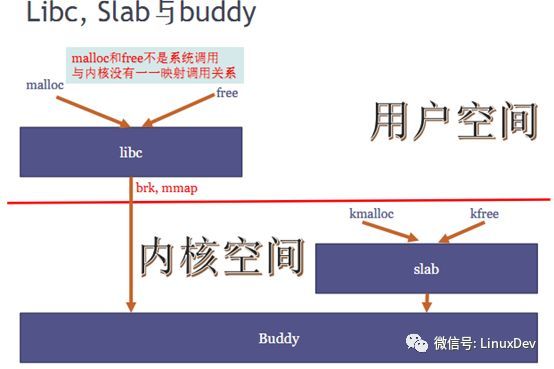
所有的内存申请最终都来自Buddy,但malloc/free及kmalloc/kfree都不与Buddy一一对应,libc和slab都相当于二级分配器。
slab与Buddy的关系:
slab与Buddy都是内存分配器。
slab的内存来自Buddy
slab与Buddy在算法上级别对等。Buddy把内存条当作一个池子来管理,slab是把从Buddy拿到的内存当作一个池子来管理的。
3. mallopt

mallopt(M_TRIM_THRESHOLD, -1UL); 控制libc把内存还给内核的门限。把门限设置为-1UL表示在任何情况下,libc都不把内存还给内核。则从
4. vmalloc
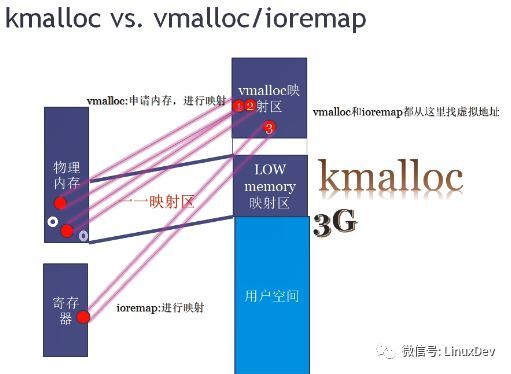
首先内存地址空间是包括物理内存+寄存器的,CPU在访问内存地址空间时都是经过virt->mmu->phys的过程。
图中内存空间中不同颜色的点都代表一页内存,无论是高端内存还是低端内存,都有可能被kmalloc,vmalloc和用户空间的malloc申请走(Buddy算法即是管理这一页是否被申请走的)。
malloc、vmalloc与kmalloc的唯一区别是malloc、vmalloc申请内存后需要修改页表,而kmalloc申请内存时由于已经做了开机线性映射,所以不需要修改页表。
寄存器是通过ioremap向vmalloc映射区去映射的,一旦调用ioremap,Linux就从vmalloc映射区找一个空闲的虚拟地址空间,然后去修改进程的页表,把这个虚拟地址往这个寄存器的物理地址去指。
vmalloc区域完成两个作用:
1)调用vmalloc从内核中申请内存并映射到vmalloc区
2)寄存器通过ioremap也映射到vmalloc区域
可以通过/proc/vmallocinfo文件查看
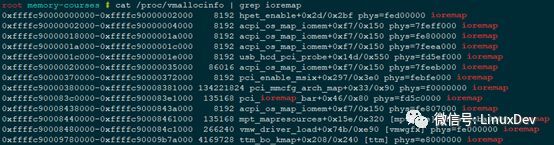
附注:
MMU通过虚拟地址察物理地址,不同的虚拟地址是可以对应一个相同的物理地址的:
理解页表最简单的方法(先只考虑一级页表),可以把页表想象成一个一维数组(a[1M],1M个成员是因为32位宽的地址,低12位作页内偏移,高20位对应第几页),CPU访问虚拟地址时,MMU用高20位作为数组的下标去取物理地址,比如假设成取a[i]成员,则a[i]中存物理地址,RWX权限和user/kernel权限。所以,两个不同的虚拟地址a[i]和a[j]中的内容(物理地址)相同是完全可能的。
5. Linux内核为应用程序分配内存的lazy行为
如,在用户空间成功申请100M内存时并没有真的申请成功,只有100M内存中的任意一页被写的时候才真的成功。
用户空间malloc成功申请100M内存时,Linux内核将这100M内存中的每一个4K都以只读的形式映射到一个全部清零的页面(这其实不太符合堆的定义,堆一般是可读可写的),当任意一个4K被写的时候即会发生page fault,Linux内核收到缺页中断后就可以从硬件寄存器中读取到缺页中断的地址和发生原因。之后Linux内核根据缺页中断报告的虚拟地址和原因分析出是用户程序在写malloc的合法区域,此时Linux内核会从内存中新申请一页内存,执行copy on write,把全部清零的页面重新拷贝给新申请的页面,然后把进程的页表项的虚拟地址指向一个新的物理地址。同时,页表中这一页地址的权限也修改为R+W的。注意以页单位发生page fault。
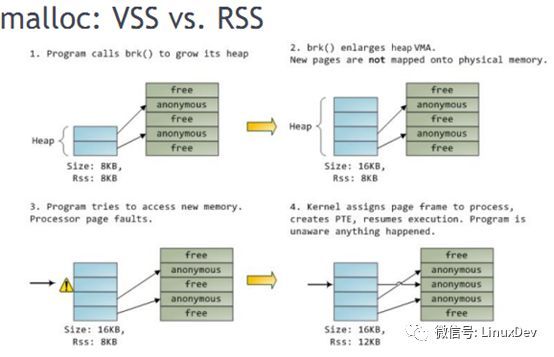
VSS - Virtual Set Size
RSS - Resident Set Size
图中第一步,堆初始为8K已写8K,所以RSS为8K;第二步调用brk扩展堆为16K,此时VSS变为16K,但RSS仍然是8K;第三步,写堆的第三页发生page fault;第四步,写时拷贝,RSS变为12K。以此类推,写第四页成功后RSS才会变为16K。
注:Lazy机制可以理解为“欺骗应用程序”。但在内核空间调用kmalloc是不欺骗的,要么分配成功,要么分配失败。
6. 内存耗尽(OOM)、oom_score和oom_adj
Linux在运行时会对每一个进程进行一个Out of Memory的打分(基于进程所耗费内存的大小,耗费越多分数越高)。可以通过/proc/pid/oom_score文件查看分数。一旦内存耗尽,Linux内核会kill掉当前oom_score分值最高的进程。

例1:编译图上程序,swapoff -a将交换分区关闭,并且配置overcommit_memory为1(允许应用程序申请很大的内存,而内核不再去评估系统中当前还有多少内存可用。):sudo sh -c ‘echo 1 > /proc/sys/vm/overcommit_memory’(echo不会启动一个新的进程,所以加sh -c,在新的shell中执行,这样才能使sudo有效),然后运行。可以发现在运行一段时间后此程序被杀死,dmesg查看:
![]()
Out of memory:score分数848被杀死。
另外,OOM打分还会看一些其他的因子,如下图所示:

例2:启动另一个进程firefox,同样关闭swap分区并配置overcommit_memory为1,然后将firefox的oom_score调到最高,运行例1中的a.out观察哪个进程先被杀死。
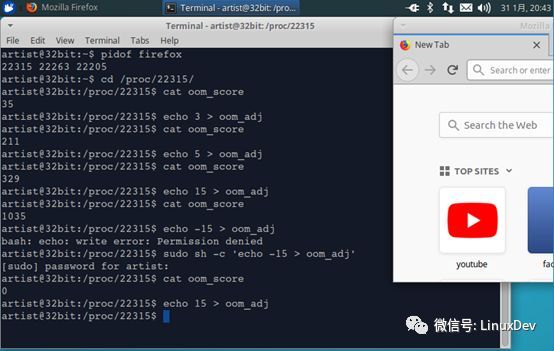
如上图所示,写入到oom_adj的数值越大,导致oom_score的打分越高,越容易被杀死,此时写入不需要root权限,但想使其打分值变小则需要root权限,这也是符合现实意义的。
运行例1中的a.out,可以发现由于firefox的oom_score更高,所以先被杀死,但一段时间过后再次发生Out of memory,a.out也被杀死。
7. Android进程生命周期与OOM
Android在程序退出时候,并不杀死进程,而是等OOM发生后再杀死。Android根据不同的进程类型设置不同的oom_adj。这样做的目的就是为了最大程度上的提高用户体验。
内存管理报名
报名:《Linux的任督二脉》之《内存管理》微课(连续5晚)