libSVM + VS2013 + C++使用介绍
libSVM是一个非常有名的SVM开源库,最近我在做分类任务,最后需要用到SVM进行分类,可是网上对于libSVM的介绍大多是matlab的,还有就是使用DOS命令调用的,直接使用libSVM的函数进行编程的介绍非常少,我来大体介绍一下我使用的情况吧。
我对于libSVM的了解也不是很清楚,只是单纯的利用他做训练和识别而已。
一、环境搭建
我使用的VS2013 + C++作为开发的,首先下载libSVM最新的版本 http://www.csie.ntu.edu.tw/~cjlin/libsvm/,解压后如下图所示:
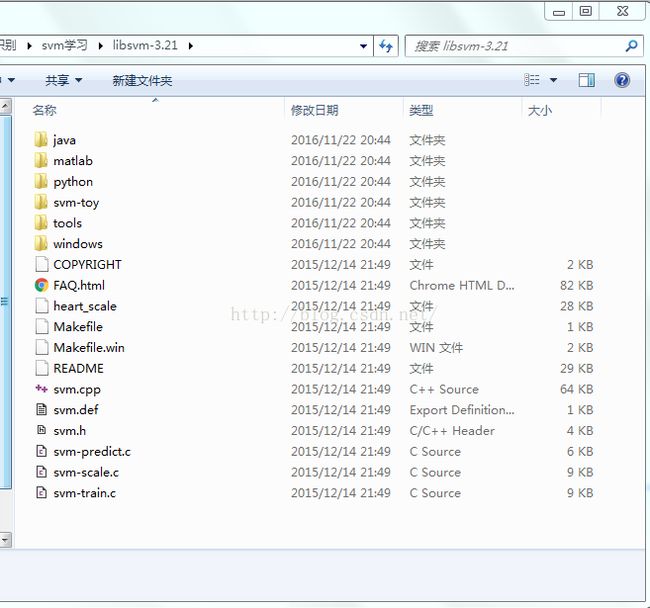
使用VS2013创建一个新的空工程,把上图目录中的svm.cpp和svm.h复制到工程目录下,并通过在工程中右键——Add——Exsiting Item把这两个文件添加到工程中去,如下图所示。
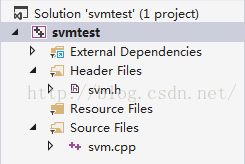
好了,到目前为止环境就搭建好了,简单明了~
注意:VS2013中使用fopen会出现一个错误,原因是VS2013自身兼容性不好,认为fopen不安全,可以通过 工程右键——Properties——C++——Preprocesser——Preprocesser Definitions中添加_CRT_SECURE_NO_WARNINGS解决该问题。
同时VS2013中编译会出现strdup函数编译不过去,同样根据提示,把该函数改为_strdup即可。
二、特征文件读取
我感觉网上对于libsvm有一种误导,就是你的特征文件必须要按照一定的格式来,才能够被读取训练,其实这只是对于使用dos命令行调用libsvm时的规定,因为libsvm自定义的特征文件格式是与其读取相匹配的。
如果我们使用自己的读取文件函数,则完全不用拘束于这种格式,只要我们在读取函数之中与我们自己的特征文件格式相匹配即可。
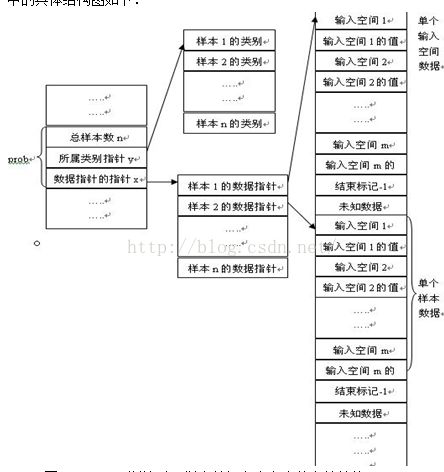
在libsvm中,与读取特征文件相关的类型为svm_problem。这个类中有三个元素,如下所示:
struct svm_problem
{
int n; //记录样本总数
double *y; //记录样本所属类别
struct svm_node **x; //存储所有样本的特征,二维数组,一行存一个样本的所有特征
};struct svm_node //用来存储输入空间中的单个特征
{
int index; //该特征在特征空间中的维度编号
double value; //该特征的值
};
好了,知道在libsvm中特征是如何存储以后,就可以编写读取文件的函数了。

我使用SVM的类的头文件如下所示:
#include "svm.h"
#include
#include
#include
#include
class ClassificationSVM
{
public:
ClassificationSVM();
~ClassificationSVM();
void train(const std::string& modelFileName);
void predict(const std::string& featureaFileName, const std::string& modelFileName);
private:
void setParam();
void readTrainData(const std::string& featureFileName);
private:
svm_parameter param;
svm_problem prob;//all the data for train
std::list dataList;//list of features of all the samples
std::list typeList;//list of type of all the samples
int sampleNum;
//bool* judgeRight;
};
void ClassificationSVM::setParam()
{
param.svm_type = C_SVC;
param.kernel_type = RBF;
param.degree = 3;
param.gamma = 0.5;
param.coef0 = 0;
param.nu = 0.5;
param.cache_size = 40;
param.C = 500;
param.eps = 1e-3;
param.p = 0.1;
param.shrinking = 1;
param.nr_weight = 0;
param.weight = NULL;
param.weight_label = NULL;
}我的读取文件的函数如下所示:
void ClassificationSVM::readTrainData(const string& featureFileName)
{
FILE *fp = fopen(featureFileName.c_str(), "r");
if (fp == NULL)
{
cout << "open feature file error!" << endl;
return;
}
fseek(fp, 0L, SEEK_END);
long end = ftell(fp);
fseek(fp, 0L, SEEK_SET);
long start = ftell(fp);
//读取文件,直到文件末尾
while (start != end)
{
//FEATUREDIM是自定义变量,表示特征的维度
svm_node* features = new svm_node[FEATUREDIM + 1];//因为需要结束标记,因此申请空间时特征维度+1
for (int k = 0; k < FEATUREDIM; k++)
{
double value = 0;
fscanf(fp, "%lf", &value);
features[k].index = k + 1;//特征标号,从1开始
features[k].value = value;//特征值
}
features[FEATUREDIM].index = -1;//结束标记
char c;
fscanf(fp, "\n", &c);
char name[100];
fgets(name, 100, fp);
name[strlen(name) - 1] = '\0';
//negative sample type is 0
int type = 0;
//positive sample type is 1
if (featureFileName == "PositiveFeatures.txt")
type = 1;
dataList.push_back(features);
typeList.push_back(type);
sampleNum++;
start = ftell(fp);
}
fclose(fp);
}
**修改**
dataList和typeList的声明如下:
std::list dataList;//list of features of all the samples
std::list typeList;//list of type of all the samples
std::list
三、svm训练和识别
训练时的代码如下图所示:
void ClassificationSVM::train(const string& modelFileName)
{
cout << "reading positivie features..." << endl;
readTrainData("PositiveFeatures.txt");
cout << "reading negative features..." << endl;
readTrainData("NegativeFeatures.txt");
cout << sampleNum << endl;
prob.l = sampleNum;//number of training samples
prob.x = new svm_node *[prob.l];//features of all the training samples
prob.y = new double[prob.l];//type of all the training samples
int index = 0;
while (!dataList.empty())
{
prob.x[index] = dataList.front();
prob.y[index] = typeList.front();
dataList.pop_front();
typeList.pop_front();
index++;
}
cout << "start training" << endl;
svm_model *svmModel = svm_train(&prob, ¶m);
cout << "save model" << endl;
svm_save_model(modelFileName.c_str(), svmModel);
cout << "done!" << endl;
}
svm_train和svm_save_model函数都是libsvm中自带的,在svm.h中定义。
分类时的代码如下所示:
void ClassificationSVM::predict(const string& featureFileName, const string& modelFileName)
{
std::vector judgeRight;
svm_model *svmModel = svm_load_model(modelFileName.c_str());
FILE *fp;
if ((fp = fopen(featureFileName.c_str(), "rt")) == NULL)
return;
fseek(fp, 0L, SEEK_END);
long end = ftell(fp);
fseek(fp, 0L, SEEK_SET);
long start = ftell(fp);
while (start != end)
{
svm_node* input = new svm_node[FEATUREDIM + 1];
for (int k = 0; k
最后注意:标准的svm只支持二分类问题,对于多分类问题,需要进行其他的处理操作。