MapReduce Design Patterns-chapter 6
**Oozie**
Job Chaining
CombineFileInputFormat takessmaller blocks and lumps them together to make a larger input split
before being processed by the mapper.
You can also fire off multiple jobs in parallel by using **Job.submit()** instead of **Job.wait
ForCompletion() **. **The submit method returns immediately to the current thread and
runs the job in the background **. This allows you to run several jobs at once. Use Job.is
Complete(), a nonblocking job completion check, to constantly poll to see whether all
of the jobs are complete.
Problem: Given a data set of StackOverflow posts, bin users based on if they are below
or above the number of average posts per user. Also to enrich each user with his or her
reputation from a separate data set when generating the output.
Job one mapper:
public static class UserIdCountMapper extends
Mapper
public static final String RECORDS_COUNTER_NAME = "Records";
private static final LongWritable ONE = new LongWritable(1);
private Text outkey = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map
.toString());
String userId = parsed.get("OwnerUserId");
if (userId != null) {
outkey.set(userId);
context.write(outkey, ONE);
context.getCounter(AVERAGE_CALC_GROUP,
RECORDS_COUNTER_NAME).increment(1);
}
}
}
Job one reducer:
public static class UserIdSumReducer extends
Reducer
public static final String USERS_COUNTER_NAME = "Users";
private LongWritable outvalue = new LongWritable();
public void reduce(Text key, Iterable
Context context) throws IOException, InterruptedException {
// Increment user counter, as each reduce group represents one user
context.getCounter(AVERAGE_CALC_GROUP, USERS_COUNTER_NAME).increment(1);
int sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
outvalue.set(sum);
context.write(key, outvalue);
}
}
Job two mapper:
The setup phase accomplishes three dif‐
ferent things. The average number of posts per user is pulled from the Context object
that was set during job configuration. The MultipleOutputs utility is initialized as well.
This is used to write the output to different bins. Finally, the user data set is parsed from
the DistributedCache to build a map of user ID to reputation. This map is used for the
desired data enrichment during output.
public static class UserIdBinningMapper extends
Mapper
public static final String AVERAGE_POSTS_PER_USER = "avg.posts.per.user";
public static void setAveragePostsPerUser(Job job, double avg) {
job.getConfiguration().set(AVERAGE_POSTS_PER_USER,
Double.toString(avg));
}
public static double getAveragePostsPerUser(Configuration conf) {
return Double.parseDouble(conf.get(AVERAGE_POSTS_PER_USER));
}
private double average = 0.0;
private MultipleOutputs
private Text outkey = new Text(), outvalue = new Text();
private HashMap
new HashMap
protected void setup(Context context) throws IOException,
InterruptedException {
average = getAveragePostsPerUser(context.getConfiguration());
mos = new MultipleOutputs
Path[] files = DistributedCache.getLocalCacheFiles(context
.getConfiguration());
// Read all files in the DistributedCache
for (Path p : files) {
BufferedReader rdr = new BufferedReader(
new InputStreamReader(
new GZIPInputStream(new FileInputStream(
new File(p.toString())))));
String line;
// For each record in the user file
while ((line = rdr.readLine()) != null) {
// Get the user ID and reputation
Map
.transformXmlToMap(line);
// Map the user ID to the reputation
userIdToReputation.put(parsed.get("Id"),
parsed.get("Reputation"));
}
}
}
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = value.toString().split("\t");
String userId = tokens[0];
int posts = Integer.parseInt(tokens[1]);
outkey.set(userId);
outvalue.set((long) posts + "\t" + userIdToReputation.get(userId));
if ((double) posts < average) {
mos.write(MULTIPLE_OUTPUTS_BELOW_NAME, outkey, outvalue,
MULTIPLE_OUTPUTS_BELOW_NAME + "/part");
} else {
mos.write(MULTIPLE_OUTPUTS_ABOVE_NAME, outkey, outvalue,
MULTIPLE_OUTPUTS_ABOVE_NAME + "/part");
}
}
protected void cleanup(Context context) throws IOException,
InterruptedException {
mos.close();
}
}
Driver Code
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Path postInput = new Path(args[0]);
Path userInput = new Path(args[1]);
Path outputDirIntermediate = new Path(args[2] + "_int");
Path outputDir = new Path(args[2]);
// Setup first job to counter user posts
Job countingJob = new Job(, "JobChaining-Counting");
countingJob.setJarByClass(JobChainingDriver.class);
// Set our mapper and reducer, we can use the API's long sum reducer for
// a combiner!
countingJob.setMapperClass(UserIdCountMapper.class);
countingJob.setCombinerClass(LongSumReducer.class);
countingJob.setReducerClass(UserIdSumReducer.class);
countingJob.setOutputKeyClass(Text.class);
countingJob.setOutputValueClass(LongWritable.class);
countingJob.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(countingJob, postInput);
countingJob.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(countingJob, outputDirIntermediate);
// Execute job and grab exit code
int code = countingJob.waitForCompletion(true) ? 0 : 1;
if (code == 0) {
// Calculate the average posts per user by getting counter values
double numRecords = (double) countingJob
.getCounters()
.findCounter(AVERAGE_CALC_GROUP,
UserIdCountMapper.RECORDS_COUNTER_NAME).getValue();
double numUsers = (double) countingJob
.getCounters()
.findCounter(AVERAGE_CALC_GROUP,
UserIdSumReducer.USERS_COUNTER_NAME).getValue();
double averagePostsPerUser = numRecords / numUsers;
// Setup binning job
Job binningJob = new Job(new Configuration(), "JobChaining-Binning");
binningJob.setJarByClass(JobChainingDriver.class);
// Set mapper and the average posts per user
binningJob.setMapperClass(UserIdBinningMapper.class);
UserIdBinningMapper.setAveragePostsPerUser(binningJob,
averagePostsPerUser);
binningJob.setNumReduceTasks(0);
binningJob.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(binningJob, outputDirIntermediate);
// Add two named outputs for below/above average
MultipleOutputs.addNamedOutput(binningJob,
MULTIPLE_OUTPUTS_BELOW_NAME, TextOutputFormat.class,
Text.class, Text.class);
MultipleOutputs.addNamedOutput(binningJob,
MULTIPLE_OUTPUTS_ABOVE_NAME, TextOutputFormat.class,
Text.class, Text.class);
MultipleOutputs.setCountersEnabled(binningJob, true);
TextOutputFormat.setOutputPath(binningJob, outputDir);
// Add the user files to the DistributedCache
FileStatus[] userFiles = FileSystem.get(conf).listStatus(userInput);
for (FileStatus status : userFiles) {
DistributedCache.addCacheFile(status.getPath().toUri(),
binningJob.getConfiguration());
}
// Execute job and grab exit code
code = binningJob.waitForCompletion(true) ? 0 : 1;
}
// Clean up the intermediate output
FileSystem.get(conf).delete(outputDirIntermediate, true);
System.exit(code);
}
*Parallel job chaining*
Problem: Given the previous example’s output of binned users, run parallel jobs over
both bins to calculate the average reputation of each user.
MapCode
public static class AverageReputationMapper extends
Mapper
private static final Text GROUP_ALL_KEY = new Text("Average Reputation:");
private DoubleWritable outvalue = new DoubleWritable();
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// Split the line into tokens
String[] tokens = value.toString().split("\t");
// Get the reputation from the third column
double reputation = Double.parseDouble(tokens[2]);
// Set the output value and write to context
outvalue.set(reputation);
context.write(GROUP_ALL_KEY, outvalue);
}
}
Reduce Code
public static class AverageReputationReducer extends
Reducer
private DoubleWritable outvalue = new DoubleWritable();
protected void reduce(Text key, Iterable
Context context) throws IOException, InterruptedException {
double sum = 0.0;
double count = 0;
for (DoubleWritable dw : values) {
sum += dw.get();
++count;
}
outvalue.set(sum / count);
context.write(key, outvalue);
}
}
Drive Code:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Path belowAvgInputDir = new Path(args[0]);
Path aboveAvgInputDir = new Path(args[1]);
Path belowAvgOutputDir = new Path(args[2]);
Path aboveAvgOutputDir = new Path(args[3]);
Job belowAvgJob = submitJob(conf, belowAvgInputDir, belowAvgOutputDir);
Job aboveAvgJob = submitJob(conf, aboveAvgInputDir, aboveAvgOutputDir);
// While both jobs are not finished, sleep
while (!belowAvgJob.isComplete() || !aboveAvgJob.isComplete()) {
Thread.sleep(5000);
}
if (belowAvgJob.isSuccessful()) {
System.out.println("Below average job completed successfully!");
} else {
System.out.println("Below average job failed!");
}
if (aboveAvgJob.isSuccessful()) {
System.out.println("Above average job completed successfully!");
} else {
System.out.println("Above average job failed!");
}
System.exit(belowAvgJob.isSuccessful() &&
aboveAvgJob.isSuccessful() ? 0 : 1);
}
private static Job submitJob(Configuration conf, Path inputDir,
Path outputDir) throws Exception {
Job job = new Job(conf, "ParallelJobs");
job.setJarByClass(ParallelJobs.class);
job.setMapperClass(AverageReputationMapper.class);
job.setReducerClass(AverageReputationReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, inputDir);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, outputDir);
// Submit job and immediately return, rather than waiting for completion
job.submit();
return job;
}
*With Shell Scripting*
Wrapping any Hadoop MapReduce job in a script, whether it be a single
Java MapReduce job, a Pig job, or whatever, has a number of benefits.
This includes post-processing, data flows, data preparation, additional
logging, and more.
The script is broken into two pieces: setting variables to actually execute
the jobs, and then executing them.
#!/bin/bash
JAR_FILE="mrdp.jar"
JOB_CHAIN_CLASS="mrdp.ch6.JobChainingDriver"
PARALLEL_JOB_CLASS="mrdp.ch6.ParallelJobs"
HADOOP="$( which hadoop )"
POST_INPUT="posts"
USER_INPUT="users"
JOBCHAIN_OUTDIR="jobchainout" #JobOne reduce output dir
BELOW_AVG_INPUT="${JOBCHAIN_OUTDIR}/belowavg"
ABOVE_AVG_INPUT="${JOBCHAIN_OUTDIR}/aboveavg"
BELOW_AVG_REP_OUTPUT="belowavgrep"
ABOVE_AVG_REP_OUTPUT="aboveavgrep"
#execute the first job
JOB_1_CMD="${HADOOP} jar ${JAR_FILE} ${JOB_CHAIN_CLASS} ${POST_INPUT} \
${USER_INPUT} ${JOBCHAIN_OUTDIR}"
JOB_2_CMD="${HADOOP} jar ${JAR_FILE} ${PARALLEL_JOB_CLASS} ${BELOW_AVG_INPUT} \
${ABOVE_AVG_INPUT} ${BELOW_AVG_REP_OUTPUT} ${ABOVE_AVG_REP_OUTPUT}"
CAT_BELOW_OUTPUT_CMD="${HADOOP} fs -cat ${BELOW_AVG_REP_OUTPUT}/part-*"
CAT_ABOVE_OUTPUT_CMD="${HADOOP} fs -cat ${ABOVE_AVG_REP_OUTPUT}/part-*"
#remove the temporary dirs
RMR_CMD="${HADOOP} fs -rmr ${JOBCHAIN_OUTDIR} ${BELOW_AVG_REP_OUTPUT} \
${ABOVE_AVG_REP_OUTPUT}"
LOG_FILE="avgrep_`date +%s`.txt"
The next part of the script echos each command prior to running it. It executes the first
job, and then checks the return code to see whether it failed. If it did, output is deleted
and the script exits. Upon success, the second job is executed and the same error condition is checked. If the second job completes successfully, the output of each job is
written to the log file and all the output is deleted. All the extra output is not required,
and since the final output of each file consists only one line, storing it in the log file is
worthwhile, instead of keeping it in HDFS.
{
echo ${JOB_1_CMD}
${JOB_1_CMD}
#The first Job executed failed
if [ $? -ne 0 ]
then
echo "First job failed!"
echo ${RMR_CMD}
${RMR_CMD}
exit $?
fi
echo ${JOB_2_CMD}
${JOB_2_CMD}
if [ $? -ne 0 ]
then
echo "Second job failed!"
echo ${RMR_CMD}
${RMR_CMD}
exit $?
fi
#display the second Job's result
echo ${CAT_BELOW_OUTPUT_CMD}
${CAT_BELOW_OUTPUT_CMD}
echo ${CAT_ABOVE_OUTPUT_CMD}
${CAT_ABOVE_OUTPUT_CMD}
#Remove the temporary dirs
echo ${RMR_CMD}
${RMR_CMD}
exit 0
} &> ${LOG_FILE} #redirect the standoutput to the logFile
----------
execute the script in cmd
/home/mrdp/hadoop/bin/hadoop jar mrdp.jar mrdp.ch6.JobChainingDriver posts \
users jobchainout
**The jobchainout is on HDFS?**
*With JobControl*
public static final String AVERAGE_CALC_GROUP = "AverageCalculation";
public static final String MULTIPLE_OUTPUTS_ABOVE_NAME = "aboveavg";
public static final String MULTIPLE_OUTPUTS_BELOW_NAME = "belowavg";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Path postInput = new Path(args[0]);
Path userInput = new Path(args[1]);
Path countingOutput = new Path(args[3] + "_count");
Path binningOutputRoot = new Path(args[3] + "_bins");
Path binningOutputBelow = new Path(binningOutputRoot + "/"
+ JobChainingDriver.MULTIPLE_OUTPUTS_BELOW_NAME);
Path binningOutputAbove = new Path(binningOutputRoot + "/"
+ JobChainingDriver.MULTIPLE_OUTPUTS_ABOVE_NAME);
Path belowAverageRepOutput = new Path(args[2]);
Path aboveAverageRepOutput = new Path(args[3]);
Job countingJob = getCountingJob(conf, postInput, countingOutput);
int code = 1;
//boolean waitForCompletion(boolean verbose)
//Submit the job to the cluster and wait for it to finish.
if (countingJob.waitForCompletion(true)) {
ControlledJob binningControlledJob = new ControlledJob(
getBinningJobConf(countingJob, conf, countingOutput,
userInput, binningOutputRoot));
ControlledJob belowAvgControlledJob = new ControlledJob(
getAverageJobConf(conf, binningOutputBelow,
belowAverageRepOutput));
belowAvgControlledJob.addDependingJob(binningControlledJob);
ControlledJob aboveAvgControlledJob = new ControlledJob(
getAverageJobConf(conf, binningOutputAbove,
aboveAverageRepOutput));
aboveAvgControlledJob.addDependingJob(binningControlledJob);
JobControl jc = new JobControl("AverageReputation");
jc.addJob(binningControlledJob);
jc.addJob(belowAvgControlledJob);
jc.addJob(aboveAvgControlledJob);
jc.run();
code = jc.getFailedJobList().size() == 0 ? 0 : 1;
}
FileSystem fs = FileSystem.get(conf);
fs.delete(countingOutput, true);
fs.delete(binningOutputRoot, true);
System.exit(code);
}
public static Job getCountingJob(Configuration conf, Path postInput,
Path outputDirIntermediate) throws IOException {
// Setup first job to counter user posts
Job countingJob = new Job(conf, "JobChaining-Counting");
countingJob.setJarByClass(JobChainingDriver.class);
// Set our mapper and reducer, we can use the API's long sum reducer for
// a combiner!
countingJob.setMapperClass(UserIdCountMapper.class);
countingJob.setCombinerClass(LongSumReducer.class);
countingJob.setReducerClass(UserIdSumReducer.class);
countingJob.setOutputKeyClass(Text.class);
countingJob.setOutputValueClass(LongWritable.class);
countingJob.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(countingJob, postInput);
countingJob.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(countingJob, outputDirIntermediate);
return countingJob;
}
public static Configuration getBinningJobConf(Job countingJob,
Configuration conf, Path jobchainOutdir, Path userInput,
Path binningOutput) throws IOException {
// Calculate the average posts per user by getting counter values
double numRecords = (double) countingJob
.getCounters()
.findCounter(JobChainingDriver.AVERAGE_CALC_GROUP,
UserIdCountMapper.RECORDS_COUNTER_NAME).getValue();
double numUsers = (double) countingJob
.getCounters()
.findCounter(JobChainingDriver.AVERAGE_CALC_GROUP,
UserIdSumReducer.USERS_COUNTER_NAME).getValue();
double averagePostsPerUser = numRecords / numUsers;
// Setup binning job
Job binningJob = new Job(conf, "JobChaining-Binning");
binningJob.setJarByClass(JobChainingDriver.class);
// Set mapper and the average posts per user
binningJob.setMapperClass(UserIdBinningMapper.class);
UserIdBinningMapper.setAveragePostsPerUser(binningJob,
averagePostsPerUser);
binningJob.setNumReduceTasks(0);
binningJob.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(binningJob, jobchainOutdir);
// Add two named outputs for below/above average
MultipleOutputs.addNamedOutput(binningJob,
JobChainingDriver.MULTIPLE_OUTPUTS_BELOW_NAME,
TextOutputFormat.class, Text.class, Text.class);
MultipleOutputs.addNamedOutput(binningJob,
JobChainingDriver.MULTIPLE_OUTPUTS_ABOVE_NAME,
TextOutputFormat.class, Text.class, Text.class);
MultipleOutputs.setCountersEnabled(binningJob, true);
// Configure multiple outputs
conf.setOutputFormat(NullOutputFormat.class);
FileOutputFormat.setOutputPath(conf, outputDir);
MultipleOutputs.addNamedOutput(conf, MULTIPLE_OUTPUTS_ABOVE_5000,
TextOutputFormat.class, Text.class, LongWritable.class);
MultipleOutputs.addNamedOutput(conf, MULTIPLE_OUTPUTS_BELOW_5000,
TextOutputFormat.class, Text.class, LongWritable.class);
// Add the user files to the DistributedCache
FileStatus[] userFiles = FileSystem.get(conf).listStatus(userInput);
for (FileStatus status : userFiles) {
DistributedCache.addCacheFile(status.getPath().toUri(),
binningJob.getConfiguration());
}
// Execute job and grab exit code
return binningJob.getConfiguration();
}
public static Configuration getAverageJobConf(Configuration conf,
Path averageOutputDir, Path outputDir) throws IOException {
Job averageJob = new Job(conf, "ParallelJobs");
averageJob.setJarByClass(ParallelJobs.class);
averageJob.setMapperClass(AverageReputationMapper.class);
averageJob.setReducerClass(AverageReputationReducer.class);
averageJob.setOutputKeyClass(Text.class);
averageJob.setOutputValueClass(DoubleWritable.class);
averageJob.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(averageJob, averageOutputDir);
averageJob.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(averageJob, outputDir);
// Execute job and grab exit code
return averageJob.getConfiguration();
}
Chain Folding
The most expensive parts of a MapReduce job aretypically pushing data through the pipeline: loading the data, the shuf‐
fle/sort, and storing the data.

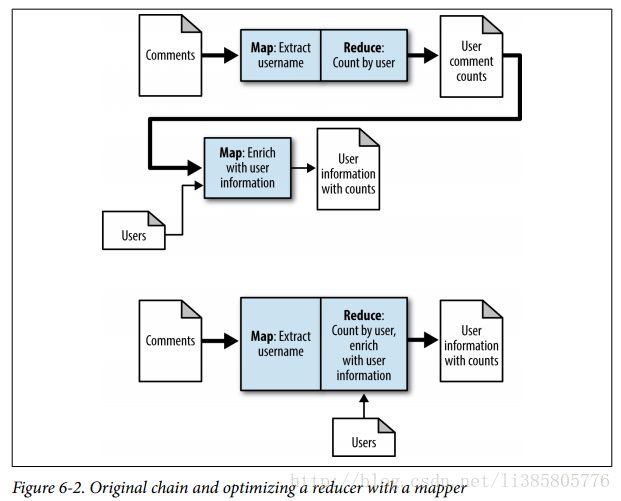

The ChainMapper and ChainReducer Approach
Each chained map phase feeds into the next in the pipeline. The output of the first is then processed by the second, which is then processed by the third, and so on. The map phases on the backend of the reducer take the output of the reducer and do additional computation. This is useful for post-processing operations or additional filtering.
Problem: Given a set of user posts and user information, bin users based on whether their reputation is below or above 5,000.
Parsing mapper code. This mapper implementation gets the user ID from the input post record and outputs it with a count of 1
public static class UserIdCountMapper extends MapReduceBase implements
Mapper {
public static final String RECORDS_COUNTER_NAME = "Records";
private static final LongWritable ONE = new LongWritable(1);
private Text outkey = new Text();
public void map(Object key, Text value,
OutputCollector output, Reporter reporter)
throws IOException {
Map parsed = MRDPUtils.transformXmlToMap(value
.toString());
// Get the value for the OwnerUserId attribute
outkey.set(parsed.get("OwnerUserId"));
output.collect(outkey, ONE);
}
} Replicated join mapper code.
public static class UserIdReputationEnrichmentMapper extends MapReduceBase
implements Mapper {
private Text outkey = new Text();
private HashMap userIdToReputation =
new HashMap();
public void configure(JobConf job) {
Path[] files = DistributedCache.getLocalCacheFiles(job);
// Read all files in the DistributedCache
for (Path p : files) {
BufferedReader rdr = new BufferedReader(
new InputStreamReader(
new GZIPInputStream(new FileInputStream(
new File(p.toString())))));
String line;
// For each record in the user file
while ((line = rdr.readLine()) != null) {
// Get the user ID and reputation
Map parsed = MRDPUtils
.transformXmlToMap(line);
// Map the user ID to the reputation
userIdToReputation.put(parsed.get("Id",
parsed.get("Reputation"));
}
}
}
public void map(Text key, LongWritable value,
OutputCollector output, Reporter reporter)
throws IOException {
String reputation = userIdToReputation.get(key.toString());
if (reputation != null) {
outkey.set(value.get() + "\t" + reputation);
output.collect(outkey, value);
}
}
} ChainMapper is first used to add the two map implementations that will be called back to back before any sorting and shuffling occurs. Then, the ChainReducer static methods are used to set the reducer implementation, and then finally a mapper on the end. Note that you don’t use ChainMapper to add a mapper after a reducer: use ChainReducer.
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf("ChainMapperReducer");
conf.setJarByClass(ChainMapperDriver.class);
Path postInput = new Path(args[0]);
Path userInput = new Path(args[1]);
Path outputDir = new Path(args[2]);
ChainMapper.addMapper(conf, UserIdCountMapper.class,
LongWritable.class, Text.class, Text.class, LongWritable.class,
false, new JobConf(false));
ChainMapper.addMapper(conf, UserIdReputationEnrichmentMapper.class,
Text.class, LongWritable.class, Text.class, LongWritable.class,
false, new JobConf(false));
ChainReducer.setReducer(conf, LongSumReducer.class, Text.class,
LongWritable.class, Text.class, LongWritable.class, false,
new JobConf(false));
ChainReducer.addMapper(conf, UserIdBinningMapper.class, Text.class,
LongWritable.class, Text.class, LongWritable.class, false,
new JobConf(false));
conf.setCombinerClass(LongSumReducer.class);
conf.setInputFormat(TextInputFormat.class);
TextInputFormat.setInputPaths(conf, postInput);
// Configure multiple outputs
conf.setOutputFormat(NullOutputFormat.class);
FileOutputFormat.setOutputPath(conf, outputDir);
MultipleOutputs.addNamedOutput(conf, MULTIPLE_OUTPUTS_ABOVE_5000,
TextOutputFormat.class, Text.class, LongWritable.class);
MultipleOutputs.addNamedOutput(conf, MULTIPLE_OUTPUTS_BELOW_5000,
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(LongWritable.class);
// Add the user files to the DistributedCache
FileStatus[] userFiles = FileSystem.get(conf).listStatus(userInput);
for (FileStatus status : userFiles) {
DistributedCache.addCacheFile(status.getPath().toUri(), conf);
}
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
Thread.sleep(5000);
}
System.exit(job.isSuccessful() ? 0 : 1);
}Job Merging
Problem: Given a set of comments, generate an anonymized version of the data and a distinct set of user IDs.
public static class TaggedText implements WritableComparable {
private String tag = "";
private Text text = new Text();
public TaggedText() { }
public void setTag(String tag) {
this.tag = tag;
}
public String getTag() {
return tag;
}
public void setText(Text text) {
this.text.set(text);
}
public void setText(String text) { this.text.set(text);
}
public Text getText() {
return text;
}
public void readFields(DataInput in) throws IOException {
tag = in.readUTF();
text.readFields(in);
}
public void write(DataOutput out) throws IOException {
out.writeUTF(tag);
text.write(out);
}
public int compareTo(TaggedText obj) {
int compare = tag.compareTo(obj.getTag());
if (compare == 0) {
return text.compareTo(obj.getText());
} else {
return compare;
}
}
public String toString() {
return tag.toString() + ":" + text.toString();
}
}Each helper math method parses the input record, but this parsing should instead be done inside the actual map method, The resulting Map
public static class AnonymizeDistinctMergedMapper extends
Mapper {
private static final Text DISTINCT_OUT_VALUE = new Text();
private Random rndm = new Random();
private TaggedText anonymizeOutkey = new TaggedText(),
distinctOutkey = new TaggedText();
private Text anonymizeOutvalue = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
anonymizeMap(key, value, context);
distinctMap(key, value, context);
}
private void anonymizeMap(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = MRDPUtils.transformXmlToMap(value
.toString());
if (parsed.size() > 0) {
StringBuilder bldr = new StringBuilder();
bldr.append(" entry : parsed.entrySet()) {
if (entry.getKey().equals("UserId")
|| entry.getKey().equals("Id")) {
// ignore these fields
} else if (entry.getKey().equals("CreationDate")) {
// Strip out the time, anything after the 'T'
// in the value
bldr.append(entry.getKey()
+ "=\""
+ entry.getValue().substring(0,
entry.getValue().indexOf('T'))
+ "\" ");
} else {
// Otherwise, output this.
bldr.append(entry.getKey() + "=\"" + entry.
getValue() + "\" ");
}
}
bldr.append(">");
anonymizeOutkey.setTag("A");
anonymizeOutkey.setText(Integer.toString(rndm.nextInt()));
anonymizeOutvalue.set(bldr.toString());
context.write(anonymizeOutkey, anonymizeOutvalue);
}
}
private void distinctMap(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed = MRDPUtils.transformXmlToMap(value
.toString());
// Otherwise, set our output key to the user's id,
// tagged with a "D"
distinctOutkey.setTag("D");
distinctOutkey.setText(parsed.get("UserId"));
// Write the user's id with a null value
context.write(distinctOutkey, DISTINCT_OUT_VALUE);
}
}
Merged reducer code. The reducer’s calls to setup and cleanup handle the creation and closing of the MultipleOutputs utility.
public static class AnonymizeDistinctMergedReducer extends
Reducer {
private MultipleOutputs mos = null;
protected void setup(Context context) throws IOException,
InterruptedException {
mos = new MultipleOutputs(context);
}
protected void reduce(TaggedText key, Iterable values,
Context context) throws IOException, InterruptedException {
if (key.getTag().equals("A")) {
anonymizeReduce(key.getText(), values, context);
} else {
distinctReduce(key.getText(), values, context);
}
}
private void anonymizeReduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
for (Text value : values) {
mos.write(MULTIPLE_OUTPUTS_ANONYMIZE, value,
NullWritable.get(), MULTIPLE_OUTPUTS_ANONYMIZE + "/part");
}
}
private void distinctReduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
mos.write(MULTIPLE_OUTPUTS_DISTINCT, key, NullWritable.get(),
MULTIPLE_OUTPUTS_DISTINCT + "/part");
}
protected void cleanup(Context context) throws IOException,
InterruptedException {
mos.close();
}
} Driver code.
public static void main(String[] args) throws Exception {
// Configure the merged job
Job job = new Job(new Configuration(), "MergedJob");
job.setJarByClass(MergedJobDriver.class);
job.setMapperClass(AnonymizeDistinctMergedMapper.class);
job.setReducerClass(AnonymizeDistinctMergedReducer.class);
job.setNumReduceTasks(10);
TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
MultipleOutputs.addNamedOutput(job, MULTIPLE_OUTPUTS_ANONYMIZE,
TextOutputFormat.class, Text.class, NullWritable.class);
MultipleOutputs.addNamedOutput(job, MULTIPLE_OUTPUTS_DISTINCT,
TextOutputFormat.class, Text.class, NullWritable.class);
job.setOutputKeyClass(TaggedText.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}setOutputKeyClass同时设置map和reduce的key类型