使用自动编码器检测信用卡欺诈

- 来源 | 愿码(ChainDesk.CN)内容编辑
- 愿码Slogan | 连接每个程序员的故事
- 网站 | http://chaindesk.cn
- 愿码愿景 | 打造全学科IT系统免费课程,助力小白用户、初级工程师0成本免费系统学习、低成本进阶,帮助BAT一线资深工程师成长并利用自身优势创造睡后收入。
- 官方公众号 | 愿码 | 愿码服务号 | 区块链部落
- 免费加入愿码全思维工程师社群 | 任一公众号回复“愿码”两个字获取入群二维码
本文阅读时间:11min
自动编码器是重要的生成模型类型之一,具有一些有趣的特性,可以用于检测信用卡欺诈等应用。在本文中,我们将使用Autoencoders来检测信用卡欺诈。
我们将使用一个新的数据集,其中包含具有匿名功能的实际信用卡交易记录。数据集不适用于很多特征工程。我们将不得不依靠端到端的学习方法来构建一个好的欺诈检测器。
从数据集加载数据
像往常一样,我们首先加载数据。时间特征显示了交易的绝对时间,这使得在这里处理起来有点困难。所以我们将放弃它。
df = pd.read_csv('../input/creditcard.csv')
df = df.drop('Time',axis=1)
我们将事务的X数据与事务的分类分开,并提取作为pandas数据帧基础的numpy数组。
X = df.drop('Class',axis=1).values
y = df['Class'].values
功能缩放
现在我们需要扩展功能。特征缩放使我们的模型更容易学习数据的良好表示。对于特征缩放,我们将所有特征缩放为介于0和1之间。这可确保数据集中没有非常高或非常低的值。但要注意,这种方法容易受到影响结果的异常值的影响。对于每列,我们首先减去最小值,以使新的最小值变为零。然后我们除以最大值,使新的最大值变为1。通过指定axis = 0,我们执行缩放列。
X -= X.min(axis=0)
X /= X.max(axis=0)
最后,我们分割了我们的数据:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train,y_test = train_test_split(X,y,test_size=0.1)
我们的编码器输入现在有29个尺寸,我们压缩到12个尺寸,然后再恢复原始的29维输出。
from keras.models import Model
from keras.layers import Input, Dense
您会注意到我们最终使用的是sigmoid激活函数。这是唯一可能的,因为我们将数据缩放为0到1之间的值。我们还使用编码层的tanh激活。这只是一种在实验中运行良好的样式选择,并确保编码值在-1和1之间。您可以根据需要使用不同的激活功能。如果您正在处理图像或更深层次的网络,则重新激活通常是一个不错的选择。如果您正在使用比我们在这里更浅的网络,那么tanh激活通常很有效。
data_in = Input(shape=(29,))
encoded = Dense(12,activation='tanh')(data_in)
decoded = Dense(29,activation='sigmoid')(encoded)
autoencoder = Model(data_in,decoded)
我们使用均方误差损失。这首先是一个不寻常的选择,使用sigmoid激活和均方误差丢失,但它是有道理的。大多数人认为乙状结肠激活必须与交叉熵损失一起使用。但是交叉熵损失会使值为零或一,并且在这种情况下适用于分类任务。但在我们的信用卡示例中,大多数值约为0.5。均值误差在处理目标不是二进制的值时更好,但在频谱上更好。
autoencoder.compile(optimizer='adam',loss='mean_squared_error')
训练后,自动编码器收敛到低损耗。
autoencoder.fit(X_train, X_train, epochs = 20, batch_size=128,
validation_data=(X_test,X_test))
重建损失很低,但我们怎么知道我们的自动编码器是否运行良好?再次,检查。人类非常善于视觉判断事物,但不善于判断抽象数字。
我们将首先进行一些预测,其中我们通过自动编码器运行测试集的子集。
pred = autoencoder.predict(X_test[0:10])
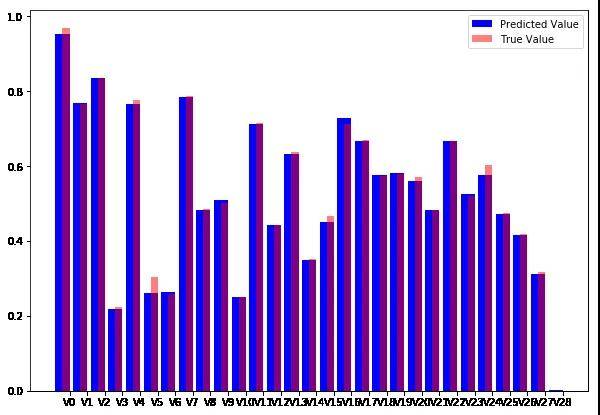
然后我们可以绘制单个样本。下面的代码生成一个重叠的条形图,将原始交易数据与重建的交易数据进行比较。
import matplotlib.pyplot as plt
import numpy as np
width = 0.8
prediction = pred[9]
true_value = X_test[9]
indices = np.arange(len(prediction))
fig = plt.figure(figsize=(10,7))
plt.bar(indices, prediction, width=width,
color='b', label='Predicted Value')
plt.bar([i+0.25*width for i in indices], true_value,
width=0.5*width, color='r', alpha=0.5, label='True Value')
plt.xticks(indices+width/2.,
['V{}'.format(i) for i in range(len(prediction))] )
plt.legend()
plt.show()
用t-SNE可视化潜在空间
我们现在有一个神经网络,它接受信用卡交易并输出看起来或多或少相同的信用卡交易。但这当然不是我们构建自动编码器的原因。自动编码器的主要优点是我们现在可以将事务编码为较低维度的表示,该表示捕获事务的主要元素。要创建编码器模型,我们所要做的就是定义一个新的Keras模型,它从输入映射到编码状态:
encoder = Model(data_in,encoded)
请注意,您无需再次训练此模型。这些层保留了我们之前训练过的自动编码器的权重。
为了编码我们的数据,我们现在使用编码器模型:
enc = encoder.predict(X_test)
但是,我们如何知道这些编码是否包含有关欺诈的任何有意义的信息?再一次,视觉表现是关键。虽然我们的编码尺寸低于输入数据,但它们仍然具有十二个维度。人类不可能考虑12维空间,因此我们需要在较低维度的空间中绘制我们的编码,同时仍然保留我们关心的特征。
在我们的例子中,我们关心的特征是接近度。我们希望在二维图中,在12维空间中彼此接近的点彼此接近。更确切地说,我们关心邻域,我们希望在高维空间中彼此最接近的点在低维空间中也彼此最接近。
保留邻居是相关的,因为我们想要找到欺诈集群。如果我们发现欺诈性交易在我们的高维编码中形成一个集群,我们可以使用一个简单的检查来判断一个新的交易是否属于欺诈集群,以便将交易标记为欺诈。
将高维数据投影到低维图中同时保留邻域的流行方法称为t分布随机邻域嵌入或t-SNE。
简而言之,t-SNE旨在忠实地表示在所有点的随机样本中两个点是邻居的概率。也就是说,它试图找到数据的低维表示,其中随机样本中的点具有与高维数据中相同的最接近邻居的概率。
t-SNE算法遵循以下步骤:
- 计算所有点之间的高斯相似度。这是通过计算点之间的欧几里德(空间)距离然后计算该距离处的高斯曲线的值来完成的,参见图形。来自该点的所有点的高斯相似度可以计算为:
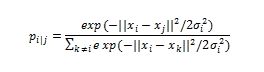
- ' sigma '是高斯分布的方差?我们将在稍后讨论如何确定这种差异。注意,由于点i和j之间的相似性通过所有其他点之间的距离之和(表示为k)来缩放,因此i,j,pi|j之间的相似性可以与j和i之间的相似性不同,pj|i 。因此,我们平均两个相似点以获得我们继续工作的最终相似性,其中n是数据点的数量。
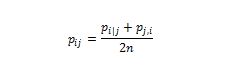
随机地将数据点定位在较低维空间中。
计算较低维空间中所有点之间的t-相似度。
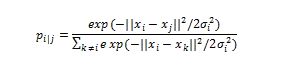
- 就像训练神经网络一样,我们将通过遵循损失函数的梯度来优化较低维空间中的数据点的位置。在这种情况下,损失函数是较高和较低维空间中相似性之间的Kullback-Leibler(KL)差异。我们将在变分自动编码器部分详细介绍KL分歧。现在,只需将其视为衡量两种分布之间差异的方法。损失函数相对于 较低维空间中的数据点i的位置yi的导数是:
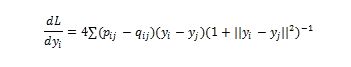
- 使用梯度下降调整较低维空间中的数据点。高维数据中靠近的移动点靠近在一起,并且移动点彼此远离更远。
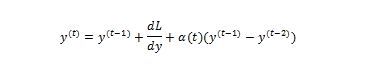
您会将此识别为具有动量的梯度下降形式,因为先前的渐变已合并到位置更新中。
使用的t分布总是具有一个自由度。一个自由度的选择导致更简单的公式以及一些不错的数值属性,从而导致更快的计算和更有用的图表。
具有困惑超参数的用户可以影响高斯分布的标准偏差。困惑可以解释为我们期望得到的邻居的数量。低茫然值强调局部邻近,而大茫然值强调全局茫然值。在数学上,困惑可以计算为:

其中Pi是数据集中所有数据点位置的概率分布,H(Pi)是此分布的Shannon熵,计算公式如下:
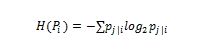
虽然该公式的细节与使用t-SNE不是非常相关,但重要的是要知道t-SNE执行对标准偏差' sigma '的值的搜索,以便它找到其上的熵的全局分布Pi。我们的数据是我们所希望的困惑。换句话说,您需要手动指定困惑,但这种困惑对数据集的意义也取决于数据集。
t-SNE的发明者Van Maarten和Hinton报告说,该算法对于5到50之间的困惑选择相对稳健。大多数库中的默认值是30,这对于大多数数据集来说是一个很好的值。如果你发现你的可视化效果不理想,那么调整困惑度值可能是你想要做的第一件事。
对于所涉及的所有数学,使用t-SNE非常简单。scikit-learn有一个方便的t-SNE 实现,我们可以像scikit中的任何算法一样使用它。我们首先导入TSNE类。然后我们创建一个新的TSNE实例。我们定义我们想要训练5000个时期,使用30的默认困惑和200的默认学习率。我们还指定我们希望在训练过程中输出。然后我们只需调用fit_transform,它将我们的12维编码转换为二维投影。
from sklearn.manifold import TSNE
tsne = TSNE(verbose=1,n_iter=5000)
res = tsne.fit_transform(enc)
作为警告,t-SNE非常慢,因为它需要计算所有点之间的距离。默认情况下,sklearn使用称为Barnes Hut近似的更快版本的t-SNE,它不是那么精确但已经快得多。
有一个更快的python实现t-SNE,可以用来代替sklearn的实现。然而,它没有得到很好的记录,并且具有较少的功能。
我们可以将t-SNE结果绘制为散点图。例如,我们将通过颜色区分欺诈与非欺诈,欺诈以红色绘制,非欺诈以蓝色绘制。由于t-SNE的实际值无关紧要,我们将隐藏轴。
fig = plt.figure(figsize=(10,7))
scatter =plt.scatter(res[:,0],res[:,1],c=y_test, cmap='coolwarm', s=0.6)
scatter.axes.get_xaxis().set_visible(False)
scatter.axes.get_yaxis().set_visible(False)

为了便于定位,包含大多数欺诈的群集标有圆圈。您可以看到欺诈与其他交易完全分开。显然,我们的自动编码器已经找到了一种方法,可以在不给出标签的情况下将欺诈与真实交易区分开来。这是一种无监督学习的形式。事实上,普通自动编码器执行PCA的近似,这对于无监督学习很有用。在图表中,您可以看到一些明显与其他交易分开但不是欺诈的集群。使用自动编码器和无监督学习,可以以我们之前没有考虑过的方式分离和分组我们的数据。