k8s三部曲(1)——kubernetes 完整集群部署(二进制安装)
kubernetes 完整集群部署(二进制安装)
1.准备环境
-
安装环境
CentOS7服务器 3台 -
准备安装包
etcd-v3.3.15-linux-amd64.tar.gzkubernetes-server-linux-amd64.tar.gzdocker-17.03.2-ce.tgzflanneld 0.7.1cfssl 1.2.0
2.安装规划
| 节点IP | 角色 | 安装的组件 |
|---|---|---|
| 192.168.0.111 | Master | etcd、kube-apiserver、kube-controller-manager、kube-scheduler、cfssl、kubectl |
| 192.168.0.112 | Node1 | docker 、kubelet、kube-proxy、flanneld 、cfssl、kubectl |
| 192.168.0.113 | Node2 | docker 、kubelet、kube-proxy flanneld、cfssl 、kubectl |
3.预备SSL/TSL证书
-
安装cfssl(所有节点)
$ yum install -y wget #下载 $ wget -q --show-progress --https-only --timestamping \ https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 \ https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 #修改为可执行权限 $ chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 #移动到bin目录 $ mv cfssl_linux-amd64 /usr/local/bin/cfssl $ mv cfssljson_linux-amd64 /usr/local/bin/cfssljson #验证 $ cfssl version -
准备生成证书的配置文件
ca-config.json(主节点){ "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "87600h" } } } } -
准备生成证书的配置文件
ca-csr.json(主节点){ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "XS", "O": "k8s", "OU": "System" } ] } -
生成根证书(主节点)
1.根证书是证书信任链的根,各个组件通讯的前提是有一份大家都信任的证书(根证书),每个人使用的证书都是由这个根证书签发的。
2.生成根证书后将根证书复制到其他节点以便生成子证书或者在主节点上生成资子证书然后复制到其他节点#所有证书相关的东西都放在这 $ mkdir -p /etc/kubernetes/ca #准备生成证书的配置文件 $ cp ca-config.json /etc/kubernetes/ca $ cp ca-csr.json /etc/kubernetes/ca #生成证书和秘钥 $ cd /etc/kubernetes/ca $ cfssl gencert -initca ca-csr.json | cfssljson -bare ca #生成完成后会有以下文件(我们最终想要的就是ca-key.pem和ca.pem,一个秘钥,一个证书) $ ls ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
4.etcd部署
-
准备证书
0.1 编写
etcd-csr.json文件(主节点){ "CN": "etcd", "hosts": [ "127.0.0.1", "192.168.0.111 " ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "XS", "O": "k8s", "OU": "System" } ] }0.2 签发etcd证书(主节点)
#etcd证书放在这 $ mkdir -p /etc/kubernetes/ca/etcd #准备etcd证书配置 $ cp etcd-csr.json /etc/kubernetes/ca/etcd/ $ cd /etc/kubernetes/ca/etcd/ #使用根证书(ca.pem)签发etcd证书 $ cfssl gencert \ -ca=/etc/kubernetes/ca/ca.pem \ -ca-key=/etc/kubernetes/ca/ca-key.pem \ -config=/etc/kubernetes/ca/ca-config.json \ -profile=kubernetes etcd-csr.json | cfssljson -bare etcd #跟之前类似生成三个文件etcd.csr是个中间证书请求文件,我们最终要的是etcd-key.pem和etcd.pem $ ls etcd.csr etcd-csr.json etcd-key.pem etcd.pem -
解压
etcd-v3.3.15-linux-amd64.tar.gztar -zxvf etcd-v3.3.15-linux-amd64.tar.gz -
解压后,将
etcd、etcdctl文件复制到/usr/bin目录cd etcd-v3.3.15-linux-amd64 cp etcd etcdctl /usr/bin -
设置
etcd.service服务文件在/etc/systemd/system/目录下创建etcd.service文件,内容如下:
[Unit] Description=etcd.service [Service] Type=notify TimeoutStartSec=0 Restart=always WorkingDirectory=/var/lib/etcd EnvironmentFile=-/etc/etcd/etcd.conf ExecStart=/usr/bin/etcd [Install] WantedBy=multi-user.target创建/var/lib/etcd 目录
mkdir /var/lib/etcd -
创建配置
/etc/etcd/etcd.conf文件,内容如下ETCD_NAME=ETCD Server ETCD_DATA_DIR="/var/lib/etcd/" ETCD_LISTEN_CLIENT_URLS="https://192.168.0.111:2379,http://127.0.0.1:2379" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.0.111:2379" ETCD_LISTEN_PEER_URLS="https://192.168.0.111:2380" ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.0.111:2380" ETCD_CERT_FILE="/etc/kubernetes/ca/etcd/etcd.pem" ETCD_KEY_FILE="/etc/kubernetes/ca/etcd/etcd-key.pem" ETCD_PEER_CERT_FILE="/etc/kubernetes/ca/etcd/etcd.pem" ETCD_PEER_KEY_FILE="/etc/kubernetes/ca/etcd/etcd-key.pem" ETCD_TRUSTED_CA_FILE="/etc/kubernetes/ca/ca.pem" ETCD_PEER_TRUSTED_CA_FILE="/etc/kubernetes/ca/ca.pem" ETCD_AUTO_TLS="true" ETCD_PEER_AUTO_TLS="true" -
配置开机启动
systemctl daemon-reload systemctl enable etcd.service systemctl start etcd.service -
检验etcd是否按照成功
ETCDCTL_API=3 etcdctl \ --endpoints=https://192.168.0.111:2379 \ --cacert=/etc/kubernetes/ca/ca.pem \ --cert=/etc/kubernetes/ca/etcd/etcd.pem \ --key=/etc/kubernetes/ca/etcd/etcd-key.pem \ endpoint health #显示health代表正常 https://192.168.0.111:2379 is healthy: successfully committed proposal: took = 23.87696ms
5.kube-apiserver部署
-
准备证书
0.1 编写
kubernetes-csr.json文件(主节点){ "CN": "kubernetes", "hosts": [ "127.0.0.1", "192.168.0.111", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "XS", "O": "k8s", "OU": "System" } ] }0.2 生成证书(主节点)
#api-server证书放在这,api-server是核心,文件夹叫kubernetes吧,如果想叫apiserver也可以,不过相关的地方都需要修改哦 $ mkdir -p /etc/kubernetes/ca/kubernetes #准备apiserver证书配置 $ cp kubernetes-csr.json /etc/kubernetes/ca/kubernetes/ $ cd /etc/kubernetes/ca/kubernetes/ #使用根证书(ca.pem)签发kubernetes证书 $ cfssl gencert \ -ca=/etc/kubernetes/ca/ca.pem \ -ca-key=/etc/kubernetes/ca/ca-key.pem \ -config=/etc/kubernetes/ca/ca-config.json \ -profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes #跟之前类似生成三个文件kubernetes.csr是个中间证书请求文件,我们最终要的是kubernetes-key.pem和kubernetes.pem $ ls kubernetes.csr kubernetes-csr.json kubernetes-key.pem kubernetes.pem -
解压
kubernetes-server-linux-amd64.tar.gztar -zxvf kubernetes-server-linux-amd64.tar.gz -
解压后,将
kube-apiserver文件复制到/usr/bin目录cp kube-apiserver /usr/bin -
设置
kube-apiserver.service服务文件在/etc/systemd/system/目录下创建kube-apiserver.service,内容如下:
–advertise-address : 提供给其他组件使用的内部kube-apiserver地址
–bind-address: 安全端口https监听的host
–service-cluster-ip-range:集群的ip范围[Unit] Description=Kubernetes API Server Documentation=https://github.com/GoogleCloudPlatform/kubernetes After=network.target [Service] ExecStart=/usr/bin/kube-apiserver \ --admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota,NodeRestriction \ --insecure-bind-address=127.0.0.1 \ --kubelet-https=true \ --advertise-address=192.168.0.111 \ --bind-address=192.168.0.111 \ --authorization-mode=Node,RBAC \ --runtime-config=rbac.authorization.k8s.io/v1 \ --enable-bootstrap-token-auth \ --token-auth-file=/etc/kubernetes/ca/kubernetes/token.csv \ --tls-cert-file=/etc/kubernetes/ca/kubernetes/kubernetes.pem \ --tls-private-key-file=/etc/kubernetes/ca/kubernetes/kubernetes-key.pem \ --client-ca-file=/etc/kubernetes/ca/ca.pem \ --service-account-key-file=/etc/kubernetes/ca/ca-key.pem \ --etcd-cafile=/etc/kubernetes/ca/ca.pem \ --etcd-certfile=/etc/kubernetes/ca/kubernetes/kubernetes.pem \ --etcd-keyfile=/etc/kubernetes/ca/kubernetes/kubernetes-key.pem \ --service-cluster-ip-range=192.168.0.0/24 \ --service-node-port-range=20000-40000 \ --etcd-servers=http://127.0.0.1:2379 \ --enable-swagger-ui=true \ --allow-privileged=true \ --audit-log-maxage=30 \ --audit-log-maxbackup=3 \ --audit-log-maxsize=100 \ --audit-log-path=/var/lib/audit.log \ --event-ttl=1h --v=2 Restart=on-failure RestartSec=5 Type=notify LimitNOFILE=65536 [Install] WantedBy=multi-user.target: -
配置开机启动并查看状态
systemctl daemon-reload systemctl enable kube-apiserver.service systemctl start kube-apiserver.service systemctl status kube-apiserver.service -
生成随机token
后期需要通过token认证方式接入集群
#生成随机token $ head -c 16 /dev/urandom | od -An -t x | tr -d ' ' 64e3bafc3a02f2a56aa3570b9f6c86ef #按照固定格式写入token.csv,注意替换token内容 $ echo "64e3bafc3a02f2a56aa3570b9f6c86ef,kubelet-bootstrap,10001,\"system:kubelet-bootstrap\"" > /etc/kubernetes/ca/kubernetes/token.csv
6.kube-controller-manager部署
-
无需证书(主节点)
controller-manager一般与api-server在同一台机器上,所以可以使用非安全端口与api-server通讯,不需要生成证书和私钥。
-
解压
kubernetes-server-linux-amd64.tar.gztar -zxvf kubernetes-server-linux-amd64.tar.gz -
解压后,将
kube-controller-manager文件复制到/usr/bin目录cp kube-controller-manager /usr/bin -
设置
kube-controller-manager.service服务文件在/etc/systemd/system/目录下创建kube-controller-manager.service,内容如下:
[Unit] Description=Kubernetes Scheduler After=kube-apiserver.service Requires=kube-apiserver.service [Service] ExecStart=/usr/bin/kube-controller-manager \ --master=http://127.0.0.1:8080 \ --logtostderr=true --log-dir /var/log/kubernetes --v=2 Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target -
配置开机启动并查看状态
systemctl daemon-reload systemctl enable kube-controller-manager.service systemctl start kube-controller-manager.service systemctl status kube-controller-manager.service
7.kube-scheduler部署
-
无需证书(主节点)
controller-manager一般与api-server在同一台机器上,所以可以使用非安全端口与api-server通讯,不需要生成证书和私钥。
-
解压
kubernetes-server-linux-amd64.tar.gztar -zxvf kubernetes-server-linux-amd64.tar.gz -
解压后,将
kube-scheduler文件复制到/usr/bin目录cp kube-scheduler /usr/bin -
设置
kube-scheduler.service服务文件在/etc/systemd/system/目录下创建kube-scheduler.service,内容如下:
[Unit] Description=Kubernetes Scheduler After=kube-apiserver.service Requires=kube-apiserver.service [Service] User=root ExecStart=/usr/bin/kube-scheduler --master=http://127.0.0.1:8080 --logtostderr=true --log-dir /var/log/kubernetes --v=2 Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target -
配置开机启动并查看状态
systemctl daemon-reload systemctl enable kube-scheduler.service systemctl start kube-scheduler.service systemctl status kube-scheduler.service
8.kubectl部署
-
准备证书
前言:
1.kubectl不部署则跳过此步骤,只需将kubectl复制到主节点的/usr/bin 即可(但是之后创建的一些认证配置文件需要自行迁移到其他主机)
2.kubectl部署在所有节点,需要配置连接信息,则如下所示(可以直接在当前主机创建配置文件)0.1 编写
admin-csr.json文件{ "CN": "admin", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "XS", "O": "system:masters", "OU": "System" } ] }0.2 创建证书
#kubectl证书放在这,由于kubectl相当于系统管理员,我们使用admin命名 $ mkdir -p /etc/kubernetes/ca/admin #准备admin证书配置 - kubectl只需客户端证书,因此证书请求中 hosts 字段可以为空 $ cp admin-csr.json /etc/kubernetes/ca/admin/ $ cd /etc/kubernetes/ca/admin/ #使用根证书(ca.pem)签发admin证书 $ cfssl gencert \ -ca=/etc/kubernetes/ca/ca.pem \ -ca-key=/etc/kubernetes/ca/ca-key.pem \ -config=/etc/kubernetes/ca/ca-config.json \ -profile=kubernetes admin-csr.json | cfssljson -bare admin #我们最终要的是admin-key.pem和admin.pem $ ls admin.csr admin-csr.json admin-key.pem admin.pem -
配置
kubectl#指定apiserver的地址和证书位置(ip自行修改) $ kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/ca/ca.pem \ --embed-certs=true \ --server=https://192.168.0.111:6443 #设置客户端认证参数,指定admin证书和秘钥 $ kubectl config set-credentials admin \ --client-certificate=/etc/kubernetes/ca/admin/admin.pem \ --embed-certs=true \ --client-key=/etc/kubernetes/ca/admin/admin-key.pem #关联用户和集群 $ kubectl config set-context kubernetes \ --cluster=kubernetes --user=admin #设置当前上下文 $ kubectl config use-context kubernetes #设置结果就是一个配置文件,可以看看内容 $ cat ~/.kube/config -
验证master节点
kubectl get componentstatus NAME AGE scheduler <unknown> controller-manager <unknown> etcd-0 <unknown>
9.kube-proxy部署
-
准备证书(工作节点)
0.1 编写
kube-proxy-csr.json文件{ "CN": "system:kube-proxy", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "XS", "O": "k8s", "OU": "System" } ] }0.2 生成证书
#proxy证书放在这 $ mkdir -p /etc/kubernetes/ca/kube-proxy #准备proxy证书配置 - proxy只需客户端证书,因此证书请求中 hosts 字段可以为空。 #CN 指定该证书的 User 为 system:kube-proxy,预定义的 ClusterRoleBinding system:node-proxy 将User system:kube-proxy 与 Role system:node-proxier 绑定,授予了调用 kube-api-server proxy的相关 API 的权限 $ cp kube-proxy-csr.json /etc/kubernetes/ca/kube-proxy/ $ cd /etc/kubernetes/ca/kube-proxy/ #使用根证书(ca.pem)签发kubr-proxy证书 $ cfssl gencert \ -ca=/etc/kubernetes/ca/ca.pem \ -ca-key=/etc/kubernetes/ca/ca-key.pem \ -config=/etc/kubernetes/ca/ca-config.json \ -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy #我们最终要的是kube-proxy-key.pem和kube-proxy.pem $ ls kube-proxy.csr kube-proxy-csr.json kube-proxy-key.pem kube-proxy.pem0.3 生成
kube-proxy.kubeconfig配置#设置集群参数(注意替换ip) $ kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/ca/ca.pem \ --embed-certs=true \ --server=https://192.168.0.111:6443 \ --kubeconfig=kube-proxy.kubeconfig #设置客户端认证参数 $ kubectl config set-credentials kube-proxy \ --client-certificate=/etc/kubernetes/ca/kube-proxy/kube-proxy.pem \ --client-key=/etc/kubernetes/ca/kube-proxy/kube-proxy-key.pem \ --embed-certs=true \ --kubeconfig=kube-proxy.kubeconfig #设置上下文参数 $ kubectl config set-context default \ --cluster=kubernetes \ --user=kube-proxy \ --kubeconfig=kube-proxy.kubeconfig #选择上下文 $ kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig #移动到合适位置 $ mv kube-proxy.kubeconfig /etc/kubernetes/kube-proxy.kubeconfig -
解压
kubernetes-server-linux-amd64.tar.gztar -zxvf kubernetes-server-linux-amd64.tar.gz -
解压后,将
kube-proxy文件复制到/usr/bin目录cp kube-proxy /usr/bin -
设置
kube-proxy.service服务文件在/etc/systemd/system/目录下创建kube-proxy.service,内容如下:
[Unit] Description=Kubernetes Proxy After=network.target [Service] ExecStart=/usr/bin/kube-proxy \ --hostname-override=192.168.0.112 \ --kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig \ --logtostderr=true Restart=on-failure [Install] WantedBy=multi-user.target -
配置开机启动并查看状态
systemctl daemon-reload systemctl enable kube-proxy.service systemctl start kube-proxy.service systemctl status kube-proxy.service
10.kubelet部署
-
部署准备
0.1 创建角色绑定(主节点)
引导token的方式要求客户端向api-server发起请求时告诉他你的用户名和token,并且这个用户是具有一个特定的角色:system:node-bootstrapper,所以需要先将bootstrap token 文件中的 kubelet-bootstrap 用户赋予这个特定角色,然后 kubelet才有权限发起创建认证请求。 在主节点执行下面命令
#可以通过下面命令查询clusterrole列表 kubectl -n kube-system get clusterrole #可以回顾一下token文件的内容 cat /etc/kubernetes/ca/kubernetes/token.csv 64e3bafc3a02f2a56aa3570b9f6c86ef,kubelet-bootstrap,10001,"system:kubelet-bootstrap" #创建角色绑定(将用户kubelet-bootstrap与角色system:node-bootstrapper绑定) kubectl create clusterrolebinding kubelet-bootstrap \ --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap0.2 创建bootstrap.kubeconfig(工作节点)
这个配置是用来完成bootstrap token认证的,保存了用户,token等重要的认证信息,这个文件可以借助kubectl命令生成:(也可以自己写配置)
#设置集群参数(注意替换ip) $ kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/ca/ca.pem \ --embed-certs=true \ --server=https://192.168.0.111:6443 \ --kubeconfig=bootstrap.kubeconfig #设置客户端认证参数(注意替换token) $ kubectl config set-credentials kubelet-bootstrap \ --token=64e3bafc3a02f2a56aa3570b9f6c86ef \ --kubeconfig=bootstrap.kubeconfig #设置上下文 $ kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig #选择上下文 $ kubectl config use-context default --kubeconfig=bootstrap.kubeconfig #将刚生成的文件移动到合适的位置 $ mv bootstrap.kubeconfig /etc/kubernetes/ -
解压
kubernetes-server-linux-amd64.tar.gztar -zxvf kubernetes-server-linux-amd64.tar.gz -
解压后,将
kubelet文件复制到/usr/bin目录cp kubelet /usr/bin -
设置
kubelet.service服务文件在/etc/systemd/system/目录下创建kubelet.service,内容如下:
cluster-dns :kube-dns服务的ip地址,稍后创建相应的kube-dns服务[Unit] Description=Kubernetes Kubelet After=docker.service Requires=docker.service [Service] WorkingDirectory=/var/lib/kubelet ExecStart=/usr/bin/kubelet \ --hostname-override=192.168.0.112\ --kubeconfig=/etc/kubernetes/bootstrap.kubeconfig\ --cluster-dns=192.168.0.2 \ --bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig \ --cert-dir=/etc/kubernetes/ca \ --hairpin-mode hairpin-veth \ --cluster-domain=cluster.local \ --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0\ --logtostderr=true #kubelet cAdvisor 默认在所有接口监听 4194 端口的请求, 以下iptables限制内网访问 ExecStartPost=/sbin/iptables -A INPUT -s 10.0.0.0/8 -p tcp --dport 4194 -j ACCEPT ExecStartPost=/sbin/iptables -A INPUT -s 172.16.0.0/12 -p tcp --dport 4194 -j ACCEPT ExecStartPost=/sbin/iptables -A INPUT -s 192.168.0.0/16 -p tcp --dport 4194 -j ACCEPT ExecStartPost=/sbin/iptables -A INPUT -p tcp --dport 4194 -j DROP Restart=on-failure KillMode=process记得创建
/var/lib/kubelet目录 -
禁用swap分区
sudo swapoff -a #要永久禁掉swap分区,打开如下文件注释掉swap那一行 sudo vi /etc/fstab -
配置开机启动并查看状态
systemctl daemon-reload systemctl enable kubelet.service systemctl start kubelet.service systemctl status kubelet.service#启动kubelet之后到 master节点 允许worker加入(批准worker的tls证书请求) #--------*在主节点执行*--------- $ kubectl get csr|grep 'Pending' | awk '{print $1}'| xargs kubectl certificate approve #----------------------------- #检查日志 $ journalctl -f -u kubelet
11.docker 安装
-
解压
docker-17.03.2-ce.tgztar -zxvf docker-17.03.2-ce.tgz -
解压后,将
docker文件复制到/usr/bin目录cp docker* /usr/bin -
设置
docker.service服务文件在/etc/systemd/system/目录下创建docker.service,内容如下:
[Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify # the default is not to use systemd for cgroups because the delegate issues still # exists and systemd currently does not support the cgroup feature set required # for containers run by docker ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix://var/run/docker.sock ExecReload=/bin/kill -s HUP $MAINPID # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity # Uncomment TasksMax if your systemd version supports it. # Only systemd 226 and above support this version. #TasksMax=infinity TimeoutStartSec=0 # set delegate yes so that systemd does not reset the cgroups of docker containers Delegate=yes # kill only the docker process, not all processes in the cgroup KillMode=process # restart the docker process if it exits prematurely Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target -
配置开机启动并查看状态
systemctl daemon-reload systemctl enable docker systemctl start docker systemctl status docker
12. flanneld 安装
-
准备证书
0.1 编写
flanneld-csr.json文件{ "CN": "flanneld", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "Beijing", "L": "XS", "O": "k8s", "OU": "System" } ] }0.2 生成证书
#flanneld证书放在这 $ mkdir -p /etc/kubernetes/ca/flanneld #准备flanneld证书配置 - flanneld只需客户端证书,因此证书请求中 hosts 字段可以为空 $ cp flanneld-csr.json /etc/kubernetes/ca/flanneld/ $ cd /etc/kubernetes/ca/flanneld/ #使用根证书(ca.pem)签发flanneld证书 $ cfssl gencert \ -ca=/etc/kubernetes/ca/ca.pem \ -ca-key=/etc/kubernetes/ca/ca-key.pem \ -config=/etc/kubernetes/ca/ca-config.json \ -profile=kubernetes calico-csr.json | cfssljson -bare flanneld #我们最终要的是flanneld-key.pem和flanneld.pem $ ls flanneld.csr flanneld-csr.json flanneld-key.pem flanneld.pem -
安装之前首先在Master节点的etcd上存储网关值
172.66.0.0 为docker网段(可以自定义)
ETCDCTL_API=2 etcdctl \ --endpoints=https://192.168.0.111:2379 \ --ca-file=/etc/kubernetes/ca/ca.pem \ --cert-file=/etc/kubernetes/ca/etcd/etcd.pem \ --key-file=/etc/kubernetes/ca/etcd/etcd-key.pem \ mk /atomic.io/network/config '{"Network": "172.66.0.0/16"}' -
使用yum安装flanneld
yum install -y flanneld -
service配置文件
/usr/lib/systemd/system/flanneld.service[Unit] Description=Flanneld overlay address etcd agent After=network.target After=network-online.target Wants=network-online.target After=etcd.service Before=docker.service [Service] Type=notify EnvironmentFile=/etc/sysconfig/flanneld EnvironmentFile=-/etc/sysconfig/docker-network ExecStart=/usr/bin/flanneld-start $FLANNEL_OPTIONS ${FLANNEL_ETCD_CAFILE} ${FLANNEL_ETCD_CERTFILE} ${FLANNEL_ETCD_KEYFILE} ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker Restart=on-failure [Install] WantedBy=multi-user.target WantedBy=docker.service -
/etc/sysconfig/flanneld配置文件解释: 1. --ifce=eth1 这里是网卡,一般为当前所在ip的网卡 2. FLANNEL_ETCD_PREFIX 这是etcd存储的相关网络信息的key 3. FLANNEL_ETCD_ENDPOINTS 这是etcd服务的地址# etcd url location. Point this to the server where etcd runs FLANNEL_ETCD_ENDPOINTS="https://192.168.0.111:2379" # # etcd config key. This is the configuration key that flannel queries # # For address range assignment FLANNEL_ETCD_PREFIX="/atomic.io/network" # # Any additional options that you want to pass FLANNEL_OPTIONS="--iface=eth1 --etcd-prefix=/atomic.io/network --etcd-endpoints=https://192.168.0.111:2379" FLANNEL_ETCD_CAFILE="--etcd-cafile=/etc/kubernetes/ca/ca.pem" FLANNEL_ETCD_CERTFILE="--etcd-certfile=/etc/kubernetes/ca/calico/calico.pem" FLANNEL_ETCD_KEYFILE="--etcd-keyfile=/etc/kubernetes/ca/calico/calico-key.pem" -
配置docker文件,将flanneld绑定到docker上面
最重要的就是 --bip=${FLANNEL_SUBNET} 原理就是通过绑定这个网段参数,让docker启动的时候按照这个参数去启动Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify # the default is not to use systemd for cgroups because the delegate issues still # exists and systemd currently does not support the cgroup feature set required # for containers run by docker #import flannel configuration EnvironmentFile=-/etc/sysconfig/flanneld EnvironmentFile=-/run/flannel/subnet.env EnvironmentFile=-/etc/sysconfig/docker EnvironmentFile=-/etc/sysconfig/docker-storage EnvironmentFile=-/etc/sysconfig/docker-network Environment=GOTRACEBACK=crash ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix://var/run/docker.sock --bip=${FLANNEL_SUBNET} ExecStartPost=/sbin/iptables -I FORWARD -s 0.0.0.0/0 -j ACCEPT ExecReload=/bin/kill -s HUP $MAINPID # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity # Uncomment TasksMax if your systemd version supports it. # Only systemd 226 and above support this version. #TasksMax=infinity TimeoutStartSec=0 # set delegate yes so that systemd does not reset the cgroups of docker containers Delegate=yes # kill only the docker process, not all processes in the cgroup KillMode=process # restart the docker process if it exits prematurely Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target ~ -
启动flanneld
systemctl daemon-reload systemctl enable flanneld.service systemctl start flanneld.service systemctl status flanneld.service -
重启docker
systemctl daemon-reload systemctl restart flanneld.service systemctl status flanneld.service
13.安装kube-dns
-
创建
kube-dns.yml文件vim kube-dns.yaml -
修改部分配置
clusterIP :与上面的kubelet 的cluster-dns遥遥呼应(也就是说这里的clusterIP就是上边kubelet的dns的ip)
```bash
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 192.168.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
addonmanager.kubernetes.io/mode: Reconcile
spec:
strategy:
rollingUpdate:
maxSurge: 10%
maxUnavailable: 0
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
volumes:
- name: kube-dns-config
configMap:
name: kube-dns
optional: true
containers:
- name: kubedns
image: registry.cn-hangzhou.aliyuncs.com/imooc/k8s-dns-kube-dns-amd64:1.14.5
resources:
# TODO: Set memory limits when we've profiled the container for large
# clusters, then set request = limit to keep this container in
# guaranteed class. Currently, this container falls into the
# "burstable" category so the kubelet doesn't backoff from restarting it.
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
livenessProbe:
httpGet:
path: /healthcheck/kubedns
port: 10054
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /readiness
port: 8081
scheme: HTTP
# we poll on pod startup for the Kubernetes master service and
# only setup the /readiness HTTP server once that's available.
initialDelaySeconds: 3
timeoutSeconds: 5
args:
- --domain=cluster.local.
- --dns-port=10053
- --config-dir=/kube-dns-config
- --v=2
env:
- name: PROMETHEUS_PORT
value: "10055"
ports:
- containerPort: 10053
name: dns-local
protocol: UDP
- containerPort: 10053
name: dns-tcp-local
protocol: TCP
- containerPort: 10055
name: metrics
protocol: TCP
volumeMounts:
- name: kube-dns-config
mountPath: /kube-dns-config
- name: dnsmasq
image: registry.cn-hangzhou.aliyuncs.com/imooc/k8s-dns-dnsmasq-nanny-amd64:1.14.5
livenessProbe:
httpGet:
path: /healthcheck/dnsmasq
port: 10054
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
args:
- -v=2
- -logtostderr
- -configDir=/etc/k8s/dns/dnsmasq-nanny
- -restartDnsmasq=true
- --
- -k
- --cache-size=1000
- --log-facility=-
- --server=/cluster.local./127.0.0.1#10053
- --server=/in-addr.arpa/127.0.0.1#10053
- --server=/ip6.arpa/127.0.0.1#10053
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
# see: https://github.com/kubernetes/kubernetes/issues/29055 for details
resources:
requests:
cpu: 150m
memory: 20Mi
volumeMounts:
- name: kube-dns-config
mountPath: /etc/k8s/dns/dnsmasq-nanny
- name: sidecar
image: registry.cn-hangzhou.aliyuncs.com/imooc/k8s-dns-sidecar-amd64:1.14.5
livenessProbe:
httpGet:
path: /metrics
port: 10054
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
args:
- --v=2
- --logtostderr
- --probe=kubedns,127.0.0.1:10053,kubernetes.default.svc.cluster.local.,5,A
- --probe=dnsmasq,127.0.0.1:53,kubernetes.default.svc.cluster.local.,5,A
ports:
- containerPort: 10054
name: metrics
protocol: TCP
resources:
requests:
memory: 20Mi
cpu: 10m
dnsPolicy: Default # Don't use cluster DNS.
serviceAccountName: kube-dns
```
- 创建相应服务资源
```bash
kubectl create -f kube-dns.yml
```
13.安装ingress
-
四层负载与七层负载
四层负载:根据 ip:port 进行负载
七层负载:基于四层代理之上,可以根据请求的内容、例如url、head等信息进行负载
-
安装相应资源服务
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/mandatory.yaml -
暴露相应NodePort端口
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/provider/baremetal/service-nodeport.yaml -
创建实例测试
ingress.ymlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: nginx-test spec: rules: - host: www1.liliguang.top http: paths: - path: / backend: serviceName: nginx-pod servicePort: 80 -
主机添加host 访问测试
14.可能遇到的坑
-
外部无法访问(NodePort只能一个节点访问,其他节点不行)
#核中的forward功能开启(立即生效,重启后效果不再) echo "1" > /proc/sys/net/ipv4/ip_forward #打开iptables的外网访问 iptables -P FORWARD ACCEPT -
配置服务文件时日志报Unknown lvalue或 Missing ‘=’ 错误
问题的原因是因为配置文件有可能是从window复制而来,可能会有一些隐藏格式让linux无法识别,可以使用vi命令重新创建一个文件,将配置信息复制到这个新创建文件即可解决
[vagrant@Master system]$ sudo systemctl daemon-reload [vagrant@Master system]$ sudo systemctl start kube-apiserver Failed to start kube-apiserver.service: Unit is not loaded properly: Bad message. See system logs and 'systemctl status kube-apiserver.service' for details. [vagrant@Master system]$ sudo systemctl status kube-apiserver ● kube-apiserver.service - Kubernetes API Server Loaded: error (Reason: Bad message) Active: inactive (dead) since Thu 2019-11-21 08:02:21 UTC; 8min ago Docs: https://github.com/GoogleCloudPlatform/kubernetes Main PID: 2208 (code=exited, status=0/SUCCESS) Nov 21 08:08:50 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:6] Trailing garbage, ignoring. Nov 21 08:08:50 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:7] Missing '='. Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:6] Trailing garbage, ignoring. Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:7] Unknown lvalue '--admission-control' in section 'Service' Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:8] Unknown lvalue '--insecure-bind-address' in section 'Service' Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:9] Unknown lvalue '--kubelet-https' in section 'Service' Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:10] Unknown lvalue '--bind-address' in section 'Service' Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:11] Unknown lvalue '--authorization-mode' in section 'Service' Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:12] Unknown lvalue '--runtime-config' in section 'Service' Nov 21 08:10:27 Master systemd[1]: [/etc/systemd/system/kube-apiserver.service:13] Missing '='. -
etcdctl异常x509: certificate signed by unknown authority
$ etcdctl mk /atomic.io/network/config '{"Network": "172.66.0.0/16"}' Error: x509: certificate signed by unknown authorityetcdctl工具是一个可以对etcd数据进行管理的命令行工具,这个工具在两个不同的etcd版本下的行为方式也完全不同。
export ETCDCTL_API=2
export ETCDCTL_API=3# 使用 ETCDCTL_API=2 ETCDCTL_API=2 etcdctl \ --endpoints=https://192.168.0.111:2379 \ --ca-file=/etc/kubernetes/ca/ca.pem \ --cert-file=/etc/kubernetes/ca/etcd/etcd.pem \ --key-file=/etc/kubernetes/ca/etcd/etcd-key.pem \ mk /atomic.io/network/config '{"Network": "172.66.0.0/16"}' #使用 ETCDCTL_API=3 etcdctl set /atomic.io/network/config '{"Network": "172.66.0.0/16"}' -
整个k8s集群崩溃
往往是由于etcd的数据库崩溃为主要原因,这时候只需要删除数据库,重新导入数据即可,之后会发现etcd启动正常,其他服务陆续启动正常,未启动的可以手动启动
sudo rm -rf /var/lib/etcd/* systemctl daemon-reload && systemctl restart etcd -
service account 无法访问apiserver
此问题可以参考https://blog.csdn.net/kozazyh/article/details/88541533
此问题是由于我们的default route 并不是我们当前主机的ip 造成了 如图所示
Endpoints 的 ip 并不是我们集群的master的ip
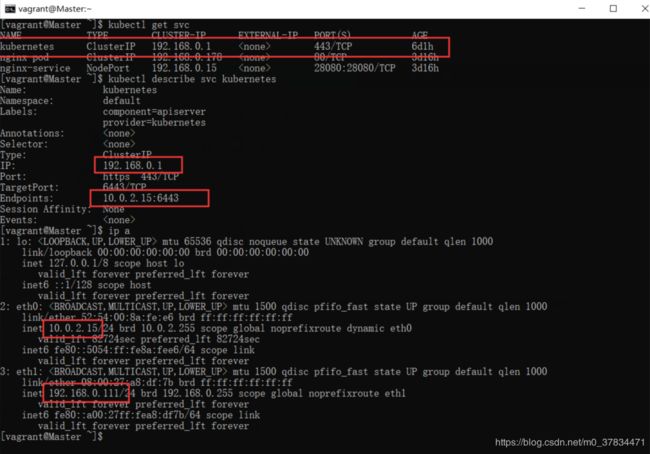
解决方案:
通过在kube-apiserver配置文件上配置 --advertise-address = 192.168.0.111
15.参考资料
慕课网 :https://coding.imooc.com/class/198.html
知乎: https://zhuanlan.zhihu.com/p/64777456