使用卡尔曼滤波进行状态估计的理解
简述
卡尔曼滤波适用于线性高斯系统,其基于马尔可夫假设,认为当前状态只与上次的状态相关(与之相反的是非线性优化,其认为当前状态与过去的所有状态相关),能够根据多个传感器的测量数据和当前的运动学模型估计出当前机器人的最优状态。
作为工程师,我认为还是很有必要理解和掌握卡尔曼滤波的核心思想和原理,不过对于证明和推导卡尔曼滤波公式就没有必要了;简而言之,理解会灵活运用即可,毕竟咱们都是普通人又不搞科研!
卡尔曼滤波能够解决什么问题
问题不是很准确,不过大概应该是可以说明问题的,别挑刺能意会哈!
- 当前比较流行的SLAM问题
假设机器人身上带了一个测距很准的多线激光雷达或者单线激光雷达(激光雷达的测距误差在我们能够忍受的范围内),我们想要构建一个区域的点云模型或者用于导航的地图,那么我们应该怎么做呢?认真考虑下这个问题后,你会发现当能够精确的获取到机器人状态后,上述问题是一个很简单的问题!
以下图说明(CAD绘制,哈哈,基础技能,很漂亮):

假设机器人在位置1(左下图)获取到了如右下图所示的激光雷达数据,机器人在位置2(左上图)获取到了如右上图所示的激光雷达数据。
注意:激光雷达数据说明:一般得到的是障碍物相对于激光雷达的Y、X,Z等距离或者是距离+方位角,好一点的雷达可能会有置信度或者强度等,毫米波雷达数据与激光雷达差不多。
认真观察上图可以发现,当准确的知道机器人从位置1到位置2走的距离(也就是1500米),然后结合机器人在这两个位置的测量的激光雷达数据,那么我们就能够构建一个完美的地图。
那么存在这样的一个传感器能够直接测量出机器人在一定时间内走了多远这个状态的传感器吗?遗憾的是当前并没有一个传感器能够直接测量出机器人在一定时间内究竟走了多少米,所以我们只能很无奈的采用一些其他传感器间接的计算出这个距离,去估计这个状态。这就是所谓的状态估计问题!
- 总结:状态估计问题就是由于无法直接得到机器人的一些状态,所以只好采用一些间接的方法去估计这些状态的问题。
当然了,我们肯定希望估计的状态非常接近真正的状态,那么我们应该如何做呢?按照上面的例子,我们接下来说下究竟有那些传感器可以间接的估计机器人的状态,以及这些传感器存在的误差,而我们又如何使用这么多的传感器数据估计最优状态呢!
- 当前使用的一系列感器:
1)光电编码器:安装于电机上的光电编码器能够测量出电机的转速,进而推导出车轮的转速,最后结合运动学模型(如二轮差分模型),我们可以粗糙的计算出机器人究竟走了多远,这就是所谓的轮式里程计。然后遗憾的是轮式里程计在车轮打滑的情况下容易产生较大误差。
2)GPS/差分GPS/RTK:提供了时间戳、机器人的经纬度等,基于经纬度数据(UTM坐标)我们也可以计算出这个平移。GPS这类传感器能够提供一个较高关于机器人很高精度的定位数据(绝对位置),特别是RTK定位数据还是非常准确的。不过这类传感器在室内、高楼之间、桥梁和隧道内等数据很差。
3)IMU:9轴线的IMU能够提供3轴的加速度,3轴的角速度,3轴的方位角(磁力计);通过磁力计提供的方位角我们可以计算机器人的姿态也就是旋转矩阵,通过初速度和初始角度,3轴的加速度和3轴的角速度等,我们可以基于二次积分计算出这个位移,不过问题在于加速度信号经过两次积分后,通常会发生漂移(假设加速度中存在着一个直流分量误差,对直流分量随着时间进行两次积分,其曲线是一个抛物线,即是漂移)。
4)视觉传感器:如单目、双目或者RGB-D等,可以通过特征匹配等类似技术获取到里程计信息,不过问题在于视觉容易受光照影响,感觉是很不稳定,有的时候就是无法提取到特征点,有的时候动态障碍物会对特征匹配影响颇大,总之不是很稳定。
5)激光雷达:如单线、多线和固态激光雷达等,可以通过如视觉手段如特征匹配获取到里程计信息,还是比较准确的,不过问题在于激光雷达有点贵,特征不是那么的丰富和容易定义提取,在走廊等地方容易出现“环境退化”等问题。
还有其他传感器能够估计出状态,如UWB等,但这些没有用过,具体不是很了解,不再赘述。
- 结论:现在回到我们的主题,以上的这些传感器对机器人的状态都有一个大概的估计,但它们都存在着种种问题,能不能把这些传感器数据进行融合从而获取到一个最优估计呢?这就引出了我们的卡尔曼滤波!
卡尔曼核心公式理解
- 首先我们明确下卡尔曼滤波的假设:以下面的两个公式进行描述


我们对它们的参数进行解释下:
![]() 机器人在t时刻的状态分量;
机器人在t时刻的状态分量;![]() 机器人在t-1时刻的状态分量;
机器人在t-1时刻的状态分量;
![]() 机器人的状态转移矩阵;
机器人的状态转移矩阵;![]() 机器人的控制矩阵;
机器人的控制矩阵;
![]() 机器人的控制输入矩阵;
机器人的控制输入矩阵;![]() 机器人在状态转移过程中的高斯噪声;
机器人在状态转移过程中的高斯噪声;
![]() 机器人的观测数据;
机器人的观测数据;![]() 机器人的观测转移矩阵;
机器人的观测转移矩阵;
![]() 观测过程中的高斯噪声
观测过程中的高斯噪声
小结:因此机器人系统方程和观测方程都必须满足“线性”,状态方程和观测方程中的噪声均是高斯噪声这两个假设。
- 以下我们开始正式迈入卡尔曼滤波的五大核心公式(《概率机器人》):

我们对它们的参数进行解释下:
![]() 机器人在t时刻预测的状态分量;
机器人在t时刻预测的状态分量; 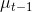 机器人在t-1时刻估计的最优状态分量;
机器人在t-1时刻估计的最优状态分量;
![]() 机器人的状态转移矩阵;
机器人的状态转移矩阵;![]() 机器人的控制矩阵;
机器人的控制矩阵;![]() 机器人的控制输入矩阵;
机器人的控制输入矩阵;
![]() 机器人在t时刻预测状态分量的协方差矩阵;
机器人在t时刻预测状态分量的协方差矩阵;![]() 机器人在t-1时刻估计最优状态分量的协方差矩阵;
机器人在t-1时刻估计最优状态分量的协方差矩阵;
![]() 状态转移过程中的高斯噪声的协方差矩阵;
状态转移过程中的高斯噪声的协方差矩阵;![]() 观测过程中高斯噪声的协方差矩阵;
观测过程中高斯噪声的协方差矩阵;
![]() 卡尔曼增益;
卡尔曼增益;![]() 机器人的观测转移矩阵;
机器人的观测转移矩阵;![]() 机器人的观测数据;
机器人的观测数据;
![]() 机器人在t时刻估计的最优状态分量;
机器人在t时刻估计的最优状态分量;![]() 机器人在t时刻估计最优状态分量的协方差矩阵;
机器人在t时刻估计最优状态分量的协方差矩阵;
关于以上这些公式的推导和证明,资料挺多的,我觉得了解就好;会用上面这些公式即可。
- 关于卡尔曼增益的理解
卡尔曼增益这个我们不从公式的角度进行分析,可能对于理解卡尔曼滤波如何融合多个传感器数据进行最优估计很有帮助。
1)假设观测噪声为0,![]() 也为0,也就是说我们的观测传感器没有任何的误差,那么卡尔曼的更新方程如下:
也为0,也就是说我们的观测传感器没有任何的误差,那么卡尔曼的更新方程如下:
![]()
![]()
![]()
根据上面的3个公式,并参考观测方程;你会发现当观测噪声为0的时候,我们估计的最优状态主要是依赖于观测方程 。
2)当我们买的传感器比较渣的时,![]() 也为无穷大,也就是说观测噪声特别大,那么卡尔曼的更新方程如下:
也为无穷大,也就是说观测噪声特别大,那么卡尔曼的更新方程如下:
![]()
![]()
![]()
根据上面的3个公式,并参考状态预测方程;你会发现当观测噪声为无穷大的时候,我们估计的最优状态主要是依赖于状态转移方程。
CSDN上两个比较有意思的卡尔曼滤波的例子
- 汽车的位置和速度估计
假设有一辆运动的汽车,要跟踪汽车的位置 p 和速度 v,这两个变量称为状态变量,我们使用
状态变量矩阵![]() 来表示小车在 t 时刻的状态,系统的状态过程方程是:
来表示小车在 t 时刻的状态,系统的状态过程方程是:

我们又通过一些其他传感器间接获取到了汽车的行走距离,假设获取的距离数据是一段从0到99,步长是1(匀速直线运动,速度为1),观测噪声是均值为0,方差为1的高斯噪声。。
import numpy as np
import matplotlib.pyplot as plt
# 创建一个0-99的一维矩阵
z = [i for i in range(100)]
z_watch = np.mat(z)
#print(z_mat)
# 创建一个方差为1的高斯噪声,精确到小数点后两位
noise = np.round(np.random.normal(0, 1, 100), 2)
noise_mat = np.mat(noise)
# 将z的观测值和噪声相加
z_mat = z_watch + noise_mat
#print(z_watch)
# 定义x的初始状态:位置 速度
x_mat = np.mat([[0,], [0,]])
# 定义初始状态协方差矩阵
p_mat = np.mat([[1, 0], [0, 1]])
# 定义状态转移矩阵,因为每秒钟采一次样,所以delta_t = 1;根据状态过程方程
f_mat = np.mat([[1, 1], [0, 1]])
# 定义状态转移协方差矩阵,这里我们把协方差设置的很小,因为觉得状态转移矩阵准确度高
q_mat = np.mat([[0.0001, 0], [0, 0.0001]])
# 定义观测矩阵
h_mat = np.mat([1, 0])
# 定义观测噪声协方差
r_mat = np.mat([1])
for i in range(100):
x_predict = f_mat * x_mat #状态预测方程,匀速直线运动,加速度为0,控制输入矩阵为0
p_predict = f_mat * p_mat * f_mat.T + q_mat #预测状态的协方差
kalman = p_predict * h_mat.T / (h_mat * p_predict * h_mat.T + r_mat) #卡尔曼增益
x_mat = x_predict + kalman *(z_mat[0, i] - h_mat * x_predict) #估计的最优状态
p_mat = (np.eye(2) - kalman * h_mat) * p_predict #估计最优状态的协方差
plt.plot(x_mat[0, 0], x_mat[1, 0], 'ro', markersize = 1)
plt.xlabel('position')
plt.ylabel('velocity')
plt.show()
结果如下图所示:

- 我们基于加速度,GPS/RTK给出的经纬度坐标 来估计飞机的位置 参考了司南牧的CSDN博客《高中生能看懂的详细通俗讲解卡尔曼滤波Kalman Filter原理及Python实现教程》
我们的状态方程是:![]() ,其中我们使用GPS两次估计位置估计速度!
,其中我们使用GPS两次估计位置估计速度!
import numpy as np
# 模拟数据
t = np.linspace(1, 100, 100)
a = 0.5
position = (a * t**2)/2
position_noise = position+np.random.normal(0, 120, size=(t.shape[0]))
import matplotlib.pyplot as plt
plt.plot(t,position,label='truth position')
plt.plot(t,position_noise,label='only use measured position')
# 初始位置使用GPS数据
predicts = [position_noise[0]]
position_predict = predicts[0]
predict_var = 0
odo_var = 120**2 #这是我们自己设定的位置测量仪器的方差,越大则测量值占比越低
v_std = 50 # 测量仪器的方差
for i in range(1,t.shape[0]):
dv = (position[i]-position[i-1]) + np.random.normal(0,50) # 这个是使用GPS数据估计的速度
position_predict = position_predict + dv + 0.5 * a # 预测方程
predict_var = v_std**2 # 更新预测数据的方差,状态转移矩阵为1,期间的噪声方差为v_std**2
# 下面是一个融合过程,直接利用方差进行了融合,精华部分,没有如一般的去求取卡尔曼增益
# 已知两个观测满足高斯分布和方差,可以直接进行融合
position_predict = position_predict*odo_var/(predict_var + odo_var) + \
position_noise[i]*predict_var/(predict_var + odo_var)
predict_var = (predict_var * odo_var)/(predict_var + odo_var)**2
predicts.append(position_predict)
plt.plot(t,predicts,label='kalman filtered position')
plt.xlabel('time')
plt.ylabel('position')
plt.legend()
plt.show()
结果如下图所示:
