基于Python的拉勾网Python工程师招聘信息的爬取和处理分析
目录
- 一、项目简介
- 1、项目完成的功能
- 2、项目完成的特色
- 3、项目采用的技术栈
- 二、项目的需求分析
- 1、项目的功能需求分析
- 2、项目的非功能需求分析
- 系统性能需求
- 系统观感需求(界面需求)
- 三、项目UML图
- 1、项目功能架构图
- 2、项目主要功能流程图
- 四、项目模块
- 1、数据爬取、过滤与清洗
- 2、数据可视化展示
- (1)分析中国各个城市的职位数量及分布情况
- (2)使用词云图展示公司福利
- (3)搜索
- (4)GUI页面
- 五、项目总结
- 1、项目特点
- 2、项目不足之处
- 六、项目借鉴
一、项目简介
该项目是基于Python的拉勾网Python工程师招聘信息的爬取和处理分析,利用Python写了爬虫去获取拉勾网的招聘信息,然后进行数据可视化分析,最后用一个GUI页面串起整个项目。
1、项目完成的功能
项目完成了以下几个主要功能:
①数据的爬取、过滤与清洗:爬取拉勾网在中国范围内关于python工程师职位相关的数据信息,过滤后存储公司全名、公司福利、城市字段的内容,将数据存入.csv文件,然后对.csv文件相关字段的数据进行清洗。
②数据的可视化展示:使用GUI页面展示项目,使用柱状图展示中国各个城市的职位数量,使用词云图展示公司福利,还可以通过指定城市搜索相关内容。
2、项目完成的特色
该项目的主要特色有以下四点:
①项目采用了GUI页面展示,能使用户更加直观方面的观察到数据,而且为项目中的搜索功能设置了提示框,能够让用户的更好理解代码所返回的内容。
②由于项目所爬取的拉勾网有反爬虫机制,所以项目采用了代理IP技术和休眠技术,文明爬取。
③该项目主要是分析公司的所在城市及福利,而且拉勾网的职位相关信息量过于庞大,所以保存信息时进行了分别、过滤,只保存了与项目相关的字段,大大减少了信息量,也减少了代码爬取的时间。
④数据的可视化采用了词云图,而且把词云图的背景替换成了Python的标志,更好的将项目所采用的技术与项目内容相结合。
3、项目采用的技术栈
1、Python:版本为 Python3.6。
2、requests: 爬虫的主要技术之一,用于抓取网页的数据。
3、pandas:进行数据分析并保存为csv文件。
4、matplotlib:进行数据可视化,绘制饼图。
5、wordcloud、jieba:生成中文词云。
6、tkinter:生成GUI页面。
二、项目的需求分析
需求分析就是分析用户的需要与要求,影响着设计的过程和开发的方向。需求分析是对项目的功能需求等方面进行分析评估,在项目开发完成后,需要检查是否完成了之前分析的所要完成的功能,是否符合用户的需求。需求分析是在开发项目的前期需要做的功能,也是不可或缺的一个过程。
1、项目的功能需求分析
本项目是在分析了Python能做的事情以后,找到了一个有意义的课题去做的一个项目。本项目,不仅仅只有一些分析,还考虑到了如何更好的展示给用户看。
本项目大致分为三个功能(用户角度):饼状图分析职位数量、词云图展示公司福利、搜索特定城市信息。每个功能既相互独立又互有联系。
项目需要使用Python爬虫爬取拉勾网全国站的招聘关键词:Python工程师。出现了每页15条、30页的招聘信息,总职位条数:450条,其中包括公司全名,公司简称,公司规模,融资阶段,区域,职位名称,工作经验,学历要求,薪资,职位福利,经营范围,职位类型,公司福利,第二职位类型,城市等14个字段列。
由于是做一个小型的项目,且考虑到全部爬取得信息量太大,所以选取了用户最关心的数据进行了分析。当提到工作时,最先要解决的便是在哪个城市工作,所以本项目主要针对公司所在的城市进行一个信息爬取与分析,希望能为要找工作的用户提供一些在城市选取上的建议。譬如很多用户就会想知道各个城市的招聘数量分布情况,会担心会不会大部分的工作机会都集中在北上广深。所以,本项目是在分析了招聘的现状、特点,专门围绕着招聘的公司所在的城市设计的。
2、项目的非功能需求分析
系统性能需求
在系统性能方面,项目的日常运行对硬件没有太大的要求,但是爬取的数据量较多,所有会有很大的数据量和并发资源的占用,所以在硬件必须要具备强大的计算能力和存储能力,要具有较高的访问效率,以此保证系统良好的性能。
系统观感需求(界面需求)
系统采用了GUI页面,整体风格美观简洁,操作简单易懂,用户使用方便。
三、项目UML图
1、项目功能架构图

2、项目主要功能流程图
城市分布分析功能流程图
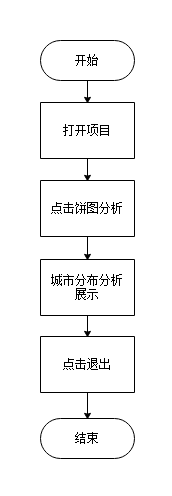
公司福利分析功能流程图

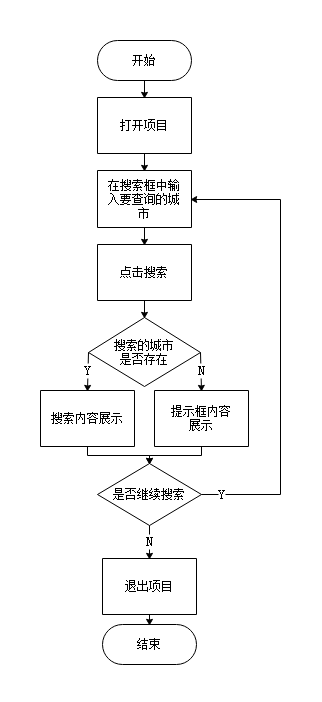
城市搜索功能流程图
四、项目模块
1、数据爬取、过滤与清洗
数据来源:拉勾网 https://www.lagou.com/
由于拉勾网有反爬虫机制,同时也为了防止频繁请求一个网站而被限制ip,所以设置了一个代理IP(你也可以选择设置IP池)和在爬取一页代码后选择睡(sleep())一段时间。
SJ_LGW()
import requests
import math
import time
import pandas as pd
from urllib import request
def getjson(url, num): # 传入两个参数url,页数
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
# 另外一种方法
# handler = request.ProxyHandler({"https":"222.76.74.183:41309"})
# opener = request.build_opener(handler)
proxies_ip = {"http": "https://222.76.74.183:41309"} # 代理ip
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=' # 关键词python开发工程师
# 模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
# 'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
# 'X-Anit-Forge-Code': '0',
# 'X-Anit-Forge-Token': 'None',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'first': 'true',
'pn': num, # 页数
'kd': 'python工程师'} # 关键字
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, proxies=proxies_ip, timeout=3) # 3秒内没有从基础套接字上接收到任何字节的数据时,将返回异常
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
res = requests.post(url, headers=headers, proxies=proxies_ip, data=data, cookies=cookie, timeout=3)
# res = opener.post(url, headers=headers,proxies=proxies, data=data, cookies=cookie, timeout=3)
res.raise_for_status() # 响应码抓取 正常为200
res.encoding = 'utf-8'
pdata = res.json() # 处理json数据返回到pdata
print('请求响应结果:', pdata, '\n\n')
return pdata
def getpnum(num):
"""
计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息
:return:
"""
pnum = math.ceil(num / 15) # ceil返回整数
if pnum > 30:
return 30
else:
return pnum
def getp(list): # 传入一个形参职位列表
"""
获取职位
:param jobs_list:
:return:
"""
plist = [] # 生成一个总页面列表
for page in list: # 循环每一页所有职位信息
jobmgs = [] # 生成一个工作信息列表
jobmgs.append(page['companyFullName']) # 把公司的名字追加到工作信息列表中
jobmgs.append(page['companyLabelList']) # 把公司福利加到工作信息列表中
jobmgs.append(page['city']) # 公司城市加到列表中
plist.append(jobmgs) # 把职位追加到总列表中
return plist
def main():
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' # json数据url F12 network 重新加载json 可以看见
shouye = getjson(url, 1) # 第一页
pnum = shouye['content']['positionResult']['totalCount'] # 页面的总数赋值
num = getpnum(pnum) # 总数调用函数后等于当前的页面数
kong = [] # 生成一个空的总职位列表
time.sleep(10)
print("python开发相关职位总数:{},总页数为:{}".format(pnum, num))
for num in range(1, num + 1):
# 获取每一页的职位相关的信息
pdata = getjson(url, num) # 获取响应json
jobs = pdata['content']['positionResult']['result'] # 获取每页的所有python相关的职位信息
pinfo = getp(jobs) # 把当前页所有的公司名字,福利,地址保存后,赋给当前页的信息
print("每一页python相关的职位信息:%s" % pinfo, '\n\n')
kong += pinfo # 当前页+总页并赋值给总页
print('已经爬取到第{}页,职位总数为{}'.format(num, len(kong)))
time.sleep(20)
# total_info爬的数据与cloumns里的数据一一对应
# 将总数据转化为data frame再输出,然后在写入到csv各式的文件中
df = pd.DataFrame(data=kong,
columns=['公司全名', '公司福利', '城市'])
df.to_csv('Date.csv', index=False) # 保存到csv中 否保存索引
print('python相关职位信息已保存')
if __name__ == '__main__':
main()


2、数据可视化展示
SJQX_LGW()
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from imageio import imread
import jieba
import matplotlib as mpl
# 使用matplotlib能够显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
df = pd.read_csv('Date.csv', encoding='utf-8')
(1)分析中国各个城市的职位数量及分布情况
分析拉勾网上有关于Python工程师招聘信息里的公司所在城市,总结中国不同城市的职位数量,使用饼状图展示结果。
SJQX_LGW()
# 绘制饼状图并保存
city = df['城市'].value_counts()#统计每个城市出现的次数
#city = df['城市'].value_counts(normalize=True)
label = city.keys()
#print(label)
# city_list = []
# count = 0
# n = 1
# distance = []
# for i in city:
#
# city_list.append(i)
# print('列表长度', len(city_list))
# count += 1
# if count > 7:
# n += 0.1
# distance.append(n)
# else:
# distance.append(0)
def show1():
# colors = ['r', 'g', 'y', 'b','p'] # 自定义颜色列表
plt.pie(city,labels=label,shadow=True,autopct='%2.1f%%',radius=2,textprops={'fontsize':8})
#plt.pie(city_list, labels=label, labeldistance=1.2, autopct='%2.1f%%', pctdistance=0.6, shadow=True, explode=distance,textprops={'fontsize':10})#explode每块表离开中心的位置
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1)) # 外边距 上边 右边
plt.savefig('python地理位置分布图.jpg')
plt.show()
城市分布饼图
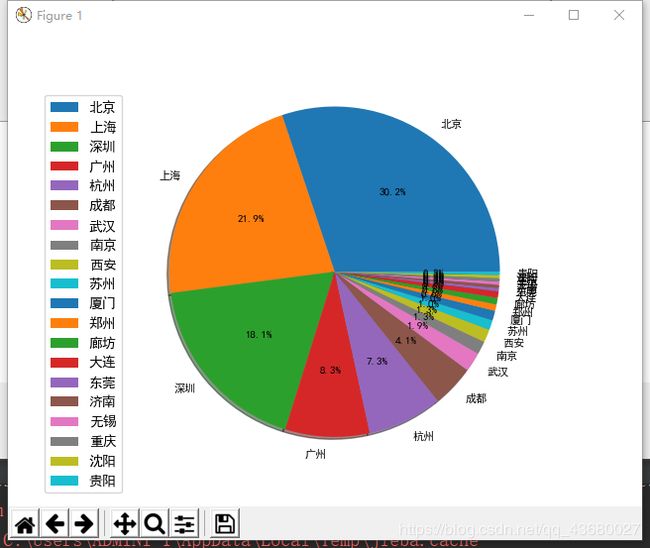
通过饼图分析,可以看见北上深杭广这5个城市占据了超过70%以上的职位数,如果再加上杭州,那就占据了85%的职位数,其中北京就占据了30.2%的职位,成为了当之无愧的职位数量首席。其中的杭州虽然不是北上广深这些老牌的一线城市,但是杭州所占的职位数也达到了7.3%,可以看出在杭州的阿里巴巴等互联网企业的带动力。北上广深杭这5个城市就提供了超过85%的职位数,有着超过80%的工作机会,剩下的城市中的职位数量较少。
(2)使用词云图展示公司福利
分析拉勾网上全国范围内有关于Python工程师招聘信息里的有关于公司福利的描述,总结词频,并使用词云图展示。
SJQX_LGW()
# 绘制福利待遇的词云
text = ''
for line in df['公司福利']:
if len(eval(line)) == 0:
continue
else:
for word in eval(line):
# print(word)
text += word
cut_word = ','.join(jieba.cut(text))#以,作为分隔符,将所有的元素合并成一个新的字符串
word_background = imread('timg.jpg') #读取图片
cloud = WordCloud(
font_path=r'C:\Windows\Fonts\simfang.ttf', # 设置字体
mask=word_background, #设置背景图片
max_words=500, # 设置最大现实的字数
max_font_size=100,# 设置字体最大值
width=500, #设置此云图生成的宽度
height=800, #设置词云图生成的高度
background_color='white', # 设置背景颜色
random_state=30 #设置有多少种随机生成状态,即有多少种配色方案
)
word_cloud = cloud.generate(cut_word) #生成此云图
word_cloud.to_file('福利待遇词云.png') # 保存图片
def show2():
plt.imshow(word_cloud) #显示词云图
plt.axis('off') # 否显示x轴、y轴下标
plt.show()
公司福利词云图
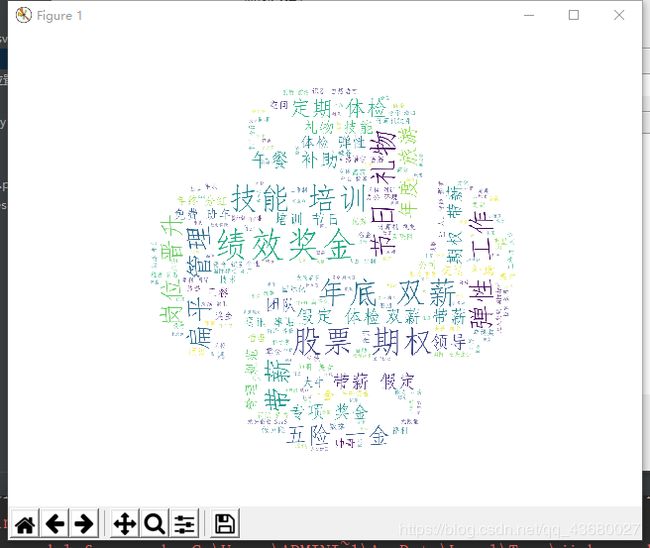
通过词云图,可以看出公司的福利集中在:绩效奖金、技能培训、年底双薪、节日礼物、股票期权、扁平管理、弹性工作、五险一金等。
从中可以看出,Python工程师的薪酬方面还是比较可观的,不仅有基本的五险一金,还有绩效奖金、股票期权、年底双薪,节日礼物这种人性化的酬劳也有,总体还是可以的。
公司在留住Python工程师方面,则有技能培训、弹性工作、扁平管理等词汇,前一段关于996的新闻层出不穷,可以看出,现在公司的福利偏向了人性管理,但是入职以后是不是这样,还是难说。
(3)搜索
在输入框内输入你想要搜索的城市,自动检索该城市的有关于Python工程师的职位信息并展示。
CZ()
from tkinter import messagebox
import pandas as pd
import csv
def find(city):
df = pd.read_csv("Date.csv")
list1 = []
# print(df[df["城市"].str.contains(city)])
for i in str(df[df["城市"].str.contains(city)]).split():
list1.append(i)
# print(list1)
if city in list1:
# 读写csv文件
filter1 = df["城市"].isin([city])
return df[filter1]
else:
return messagebox.showinfo("提示", "没有你查询的城市的信息")
#列中包含city
# return df[df["城市"].str.contains(city)]
# return result
#
#
# city = "上海"
# print(find(city))
查询的城市数据较多,可下滑查看更多信息

查询的城市数据少,不用下拉就可展示完整

查询的城市没有相应的信息
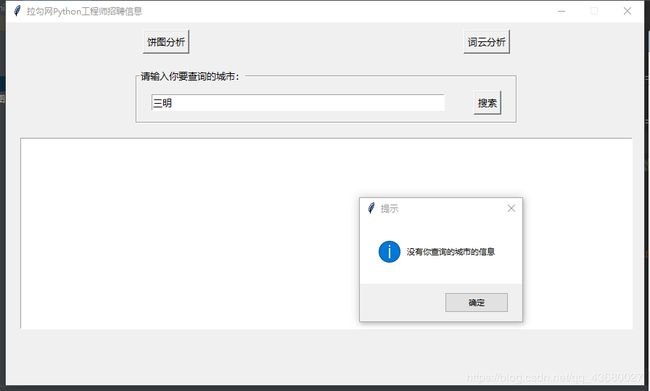
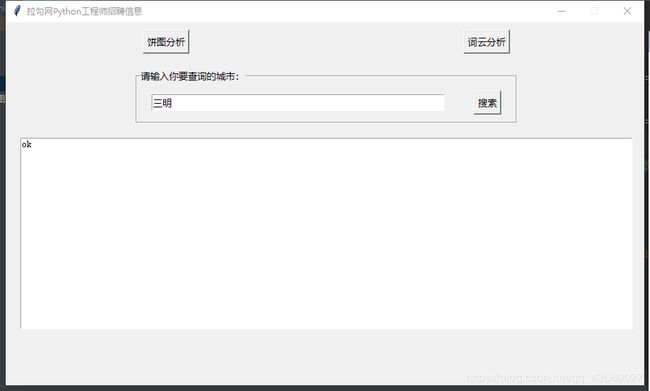
通过前面的饼状图分析,用户如果对某个城市比较满意,可以选择单独查询该城市的信息。
(4)GUI页面
编写一个tkinter模块去展示项目,可视化窗口更能够更好的好与用户进行交互。
main()
import tkinter
from CZ import find
from SJQX_LGW import show1,show2
def search():
a = find(enrty.get())
text.delete(0.0, tkinter.END)
text.insert("insert", a)
root = tkinter.Tk()
root.title("拉勾网Python工程师招聘信息")
root.geometry("880x500+200+100")
root.resizable(0, 0)
button1 = tkinter.Button(root, text="饼图分析", font=("微软雅黑",10), command=show1)
button1.grid(row=0, column=0, padx=20, pady=10)
button2 = tkinter.Button(root, text="词云分析", font=("微软雅黑",10), command=show2)
button2.grid(row=0, column=1, padx=20, pady=10)
lableframe = tkinter.LabelFrame(root, text="请输入你要查询的城市:", font=("微软雅黑",10))
lableframe.grid(row=1, column=0, columnspan=2, padx=20, pady=10)
enrty = tkinter.Entry(lableframe, font=("微软雅黑",10), width=50)
enrty.grid(row=0, column=0, padx=20, pady=10)
button3 = tkinter.Button(lableframe, text="搜索", font=("微软雅黑",10), command=search)
button3.grid(row=0, column=1, padx=20, pady=10)
text = tkinter.Text(root, width=120, height=20)
text.grid(row=2, column=0, columnspan=2, padx=20, pady=10)
root.mainloop()
项目主页面
五、项目总结
1、项目特点
①有动态的功能,可以动态查询指定城市的相关内容。
②采用GUI页面,能够很好地和用户交互。
③针对性强,三个分模块的联系紧密。
2、项目不足之处
①在爬取信息方面,可以采用更复杂的IP池,还可以采用多线程爬取。
②在存储信息方面,可以采用sql存储。
③在信息处理方面,可以进行缺失值填充、增加列等,增加数据的可读性。
④在绘图方面,可以采用高级的seaborn或PyEcharts来展示。
⑤项目太小,很多方面的内容没办法完全展示,项目展示的内容太简单,只有城市、福利、公司名字,分析的内容过少。
⑥页面展示功能太简陋,美观方面来说做的不太好。
六、项目借鉴
https://www.cnblogs.com/sui776265233/p/11146969.html#_label3.
https://zhuanlan.zhihu.com/p/90703429.
https://blog.csdn.net/keneyr/article/details/79196205.
https://www.cnblogs.com/jyroy/p/9446486.html.
https://zhuanlan.zhihu.com/p/32983898.