爬虫入门笔记1
常用python IDE 工具:
- 文本工具类IDE:IDLE、Notepad++、Sublime Text、Vim&Emacs、Atom、Komodo Edit
- 集成工具类IDE:Pycharm、Wing、PyDev&Eclipse、Visual Studio、Anaconda&Spyder、Canopy
requests库的七个主要方法:
- requests.request(请求方式,url,**kwargs) //构造一个请求,支撑以下方法的基础方法
- requests.get() //获取HtML页面的主要方法,对应HTTP的get请求
- requests.head() //获取HTML页面的头部信息的方法,对应HTTP的HEAD
- requests.post() //向HTML页面提交POST请求的方法,对应Http的POST
- requests.put() //向HTML页面提交PUT请求的方法,对应HTTP的PUT
- requests.patch() //向HTML页面提交局部修改请求,对应HTTP的PATCH
- requests.delete() //向HTML页面体检删除请求,对应HTTP的DELETE
response对象的属性:
status_code:HTTP请求返回的状态,200表示链接成功,404表示链接失败
text:HTTP响应内容的字符串形式,即 url对应的页面内容
encoding:从HTTP header中猜测的响应内容编码方式
apparent_encoding:从内容中分析出的响应编码方式(备选编码方式)
content:HTTP响应内容的二进制形式(图片还原等)
raise_for_status:如果状态码不是200,抛出HTTPError异常(判断网络连接是否成功)
headers:头部信息
*encoding和apparent_encoding的区别*:encoding是从header获取编码方式,如果header中不存在charset,则默认其为ISO-8859-1,而apparent_encoding 是从相应的内容中分析其的编码方式,比encoding更为准确,r.text默认使用encoding的编码方式,如果显示不出来汉字,我们可以用r.encoding=r.apparent_encoding,使其更准确的编码
requests库的异常:
requests.ConnetionError:网络连接错误异常,如DNS查询失败、拒绝链接等
requests.HTTPError:HTTP错误异常
requests.URLRquired:URL缺失异常
requests.TooManyRedirects:超过最大重定向次数,产生重定向异常
requests.ConnecTimeout:链接远程服务器超时异常
requests.Timeout:请求URL超时
HTTP请求方法:
get(查)、
post(增,当携带的参数是字典或键值对的时候,默认放到form扁表单里,携带的是字符串时,放到data中)、
put(改和post差不多,但覆盖原有数据)、
delete(删)、head(头部)、patch(局部更新)、options(访问咨询)
put和patch的区别当只修改多个参数中的一个时,patch只需要修改修改的参数信息,而put则需要携带所有信息,不然未携带信息将会被删除,只剩put携带的信息
requests.request(请求方式,url,**kwargs):
**kwargs中的控制参数:
- params:字典或字符串数据,作为参数添加到url中
- data:字典、字节序或文件对象,向服务器提交资源时使用,作为request内容
- json:json格式的数据,作为request内容提交
- headers:字典,http定制头
- cookie:字典或CookieJar,request中的cookie
- auth:元组,支持http认证功能
- files:字典,传输文件
- timeout:设定超时时间,秒
- proxies:字典,指定代理服务器,可以增加认证登录(隐藏原用户ip地址的信息)
- allow_redirects:bool类型 默认为True,重定向开关
- stream:bool类型 默认为True ,获取内容立即下载开关
- verify:bool类型 默认为True,认证SSL证书开关
- cert:本地SSL证书路径
requests入门框架:
try:
r=requests.request('get','http://www.baidu.com',timeout=30)
r.raise_for_status()//是否连接成功
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
网络爬虫尺寸:
网页:requests库
网站:Scrapy 库
全网:定制开发
网络爬虫限制:
- 来源审查:判断User-Agent进行限制 检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问(当想要爬取数据返回错误的状态码时,可以修改User-Agent:Mozilla/5.0(模拟为普通网站))
- 发布公告:Robots协议 告知所有爬虫网站的爬取策略,要求爬虫遵守
Robots协议:
网络爬虫排除标准(Robots Exclusion Srandard)
作用:网站告知爬虫那些网页可以抓取,那些不行
形式:网站根目录下的robots.txt文件(User-Agent:。。。 Disallow:。。。)
常见搜索引擎关键词提交接口:
百度:http://baidu.com/s?wd=keyword
360: http://www.so.com/s?q=keyword
eg: r=requests.get('http://www.baidu.com/s',params={'wd':'python'})
r.request.url //查看请求地址 ==》http://www.baidu.com/s?wd="python'
网络图片或文件爬取:
import requests
url=''"
root="D//image//"
path=root+url.aplit('/')[-1] //倒序分割
try:
if not os.path.exists(root): //判断目录是否存在
os.mkdir(root)
if not os.path.exists(path): //判断文件是否存在
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content) //存入二进制
f.close()
print('保存文件成功')
else:
print(保存文件失败)
except:
print('获取失败')
IP地址归属地查询:
ip地址查询网站:http://m.ip138.com
r=requests.get('r=requests.get('http://www.ip138.com/ips138.asp?ip=182.18.0.132',headers={'User-Agent':"Mozilla/5.0"})')
Beautiful Soup库:
可以对html、xml格式进行解析,并且提取其中的相关信息
eg:from bs4 import BeautifulSoup
soup=BeautifulSoup(r.text,"html.parser") //把字符串解析成html格式
BeautifulSoup库的解析器:
|解析器 |使用方法 |条件
|bs4的HTML解析器 |BeautifulSoup(mk,‘html.parser’) |安装bs4
|lxml的HTML解析器 |BeautifulSoup(mk,“lxml”) |pip install lxml
|lxml的XMl解析器 |BeautifulSoup(mk,“xml”) |pip install lxml
|html5lib的解析器 |BeautifulSoup(mk,‘html5lib’) |pip install html5lib
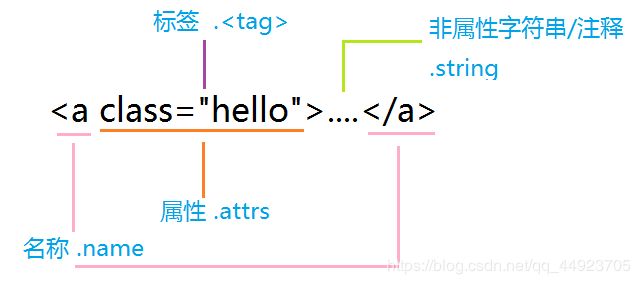
BeautifulSoup类的基本元素:
Tag:基本的信息组成单元,分别用<>标明开头或结尾 ..
Name:便签的名字,
Attributes:标签的属性,字典形式组织,格式:.attrs
NavigableString:标签内非属性字符串,<>…标签中的字符串,格式:.string
Comment:标签内字符串的注释部分,一种特殊的Comment类型
标签树:
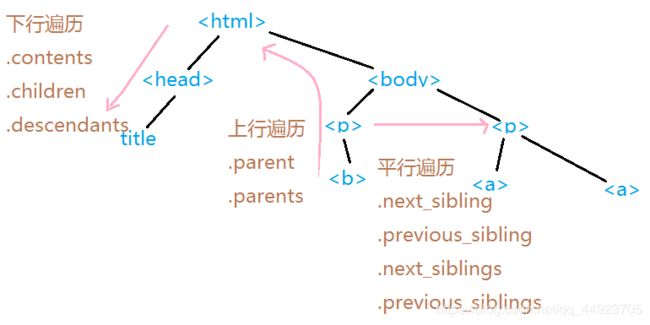
- 下行遍历:
.contents 子节点的列表,将所有儿子节点存入列表
.children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
.descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 - 上行遍历:
.parent 节点的父亲标签
.parents 子节点先辈标签的迭代类型,用于循环遍历先辈节点 - 平行遍历:
.next_sibling 返回按照HTML文本的顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点标签
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings 迭代类型,返回按照HTML文本顺序的前序所有平行节点标签
信息标记形式:
XML INternet上的信息交互与传递 类似html
JSON 移动应用云端 和节点的信息通信,无注释 ,["a":''b"] 键值对形式,双引号,有两种格式:列表格式【】和字典格式 {}
YAML:各类系统的配置文件,有注释易读,无类型,缩进显示`
key:value
key:#Comment
-value1
-value2
key:
subkey:subvalue
信息提取的一般方法:
- 完整解析信息的标记形式,再提取关键信息
XML JSON YAML
需要标记解释器 eg:bs4库的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐,速度慢 - 无视标记形式,直接搜索关键信息
搜索
对信息的文本查找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容相关 - 融合方法(融合1和2):
XML JSON YAML 搜索
.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查询的结果
name:对标签名称的检索字符串
attrs:对标签属性值的检索字符串,可标注属性检索
recursive:是否对子孙全部检索,默认True
string:<> … 中的字符串区域的检索字符串
soup(.....)等价于soup.find_all(...)