深入理解AbstractQueuedSynchronizer(一)
AbstractQueuedSynchronizer简介
AbstractQueuedSynchronizer提供了一个FIFO队列,可以看做是一个可以用来实现锁以及其他需要同步功能的框架。这里简称该类为AQS。AQS的使用依靠继承来完成,子类通过继承自AQS并实现所需的方法来管理同步状态。例如ReentrantLock,CountDownLatch等。
本篇文章基于JDK1.8来介绍,该类有许多实现类:
其中,我们最常用的大概就是ReentrantLock和CountDownLatch了。ReentrantLock提供了对代码块的并发访问控制,也就是锁,说是锁,但其实并没有用到关键字synchronized,这么神奇?其实其内部就是基于同步器来实现的,本文结合ReentrantLock的使用来分析同步器独占锁的原理。
AQS的两种功能
从使用上来说,AQS的功能可以分为两种:独占和共享。对于这两种功能,有一个很常用的类:ReentrantReadWriteLock,其就是通过两个内部类来分别实现了这两种功能,提供了读锁和写锁的功能。但子类实现时,只能实现其中的一种功能,即要么是独占功能,要么是共享功能。
对于独占功能,例如如下代码:
ReentrantLock lock = new ReentrantLock();
...
public void function(){
lock.lock();
try {
// do something...
} finally {
lock.unlock();
}
}
这个很好理解,通过ReentrantLock来保证在lock.lock()之后的代码在同一时刻只能有一个线程来执行,其余的线程将会被阻塞,直到该线程执行了lock.unlock()。这就是一个独占锁的功能。
对于共享功能,例如如下代码:
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
...
public void function(){
lock.readLock().lock();
try {
// do something...
} finally {
lock.readLock().unlock();
}
}
代码中的lock是ReentrantReadWriteLock类的实例,而lock.readLock()为获取其中的读锁,即共享锁,使用方式并无差别,但和独占锁是有区别的:
- 读锁与读锁可以共享
- 读锁与写锁不可以共享(排他)
- 写锁与写锁不可以共享(排他)
AQS独占锁的内部实现
AQS的主要数据结构
由于使用AQS可以实现锁的功能,那么下面就要分析一下究竟是如何实现的。
AQS内部维护着一个FIFO的队列,该队列就是用来实现线程的并发访问控制。队列中的元素是一个Node类型的节点,Node的主要属性如下:
static final class Node {
int waitStatus;
Node prev;
Node next;
Node nextWaiter;
Thread thread;
}- waitStatus:表示节点的状态,其中包含的状态有:
- CANCELLED:值为1,表示当前节点被取消;
- SIGNAL:值为-1,表示当前节点的的后继节点将要或者已经被阻塞,在当前节点释放的时候需要unpark后继节点;
- CONDITION:值为-2,表示当前节点在等待condition,即在condition队列中;
- PROPAGATE:值为-3,表示releaseShared需要被传播给后续节点(仅在共享模式下使用);
- 0:无状态,表示当前节点在队列中等待获取锁。
- prev:前继节点;
- next:后继节点;
- nextWaiter:存储condition队列中的后继节点;
- thread:当前线程。
其中,队列里还有一个head节点和一个tail节点,分别表示头结点和尾节点,其中头结点不存储Thread,仅保存next结点的引用。
AQS中有一个state变量,该变量对不同的子类实现具有不同的意义,对ReentrantLock来说,它表示加锁的状态:
- 无锁时state=0,有锁时state>0;
- 第一次加锁时,将state设置为1;
- 由于ReentrantLock是可重入锁,所以持有锁的线程可以多次加锁,经过判断加锁线程就是当前持有锁的线程时(即
exclusiveOwnerThread==Thread.currentThread()),即可加锁,每次加锁都会将state的值+1,state等于几,就代表当前持有锁的线程加了几次锁; - 解锁时每解一次锁就会将state减1,state减到0后,锁就被释放掉,这时其它线程可以加锁;
- 当持有锁的线程释放锁以后,如果是等待队列获取到了加锁权限,则会在等待队列头部取出第一个线程去获取锁,获取锁的线程会被移出队列;
state变量定义如下:
/**
* The synchronization state.
*/
private volatile int state;ReentrantLock类的结构
下面通过ReentrantLock的实现进一步分析重入锁的实现。
首先看一下lock方法:
public void lock() {
sync.lock();
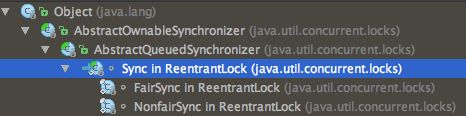
}该方法调用了sync实例的lock方法,这里要说明一下ReentrantLock中的几个内部类:
- Sync
- FairSync
- NonfairSync
对于ReentrantLock,有两种获取锁的模式:公平锁和非公平锁。所以对应有两个内部类,都继承自Sync。而Sync继承自AQS:
本文主要通过公平锁来介绍,看一下FairSync的定义:
/**
* Sync object for fair locks
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
// 获取state
int c = getState();
// state=0表示当前队列中没有线程被加锁
if (c == 0) {
/*
* 首先判断是否有前继结点,如果没有则当前队列中还没有其他线程;
* 设置状态为acquires,即lock方法中写死的1(这里为什么不直接setState?因为可能同时有多个线程同时在执行到此处,所以用CAS来执行);
* 设置当前线程独占锁。
*/
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
/*
* 如果state不为0,表示已经有线程独占锁了,这时还需要判断独占锁的线程是否是当前的线程,原因是由于ReentrantLock为可重入锁;
* 如果独占锁的线程是当前线程,则将状态加1,并setState;
* 这里为什么不用compareAndSetState?因为独占锁的线程已经是当前线程,不需要通过CAS来设置。
*/
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}AQS获取独占锁的实现
acquire方法
acquire是AQS中的方法,代码如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}该方法主要工作如下:
- 尝试获取独占锁;
- 获取成功则返回,否则执行步骤3;
- addWaiter方法将当前线程封装成Node对象,并添加到队列尾部;
- 自旋获取锁,并判断中断标志位。如果中断标志位为
true,执行步骤5,否则返回; - 设置线程中断。
tryAcquire方法
tryAcquire方法在FairSync中已经说明,它重写了AQS中的方法,在AQS中它的定义如下:
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}既然该方法需要子类来实现,为什么不使用abstract来修饰呢?上文中提到过,AQS有两种功能:独占和共享,而且子类只能实现其一种功能,所以,如果使用abstract来修饰,那么每个子类都需要同时实现两种功能的方法,这对子类来说不太友好,所以没有使用abstract来修饰。
该方法是在ReentrantLock中的FairSync和NonfairSync的两个内部类来实现的,这里以FairSysc-公平锁来说明:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}addWaiter方法
看下addWaiter方法的定义:
private Node addWaiter(Node mode) {
// 根据当前线程创建一个Node对象
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
// 判断tail是否为空,如果为空表示队列是空的,直接enq
if (pred != null) {
node.prev = pred;
// 这里尝试CAS来设置队尾,如果成功则将当前节点设置为tail,否则enq
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}该方法就是根据当前线程创建一个Node,然后添加到队列尾部。
enq方法
private Node enq(final Node node) {
// 重复直到成功
for (;;) {
Node t = tail;
// 如果tail为null,则必须创建一个Node节点并进行初始化
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
// 尝试CAS来设置队尾
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}acquireQueued方法
该方法的功能是循环的尝试获取锁,直到成功为止,最后返回中断标志位。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
// 中断标志位
boolean interrupted = false;
for (;;) {
// 获取前继节点
final Node p = node.predecessor();
// 如果前继节点是head,则尝试获取
if (p == head && tryAcquire(arg)) {
// 设置head为当前节点(head中不包含thread)
setHead(node);
// 清除之前的head
p.next = null; // help GC
failed = false;
return interrupted;
}
// 如果p不是head或者获取锁失败,判断是否需要进行park
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}这里有几个问题很重要:
- 什么条件下需要park?
- 为什么要判断中断状态?
- 死循环不会引起CPU使用率飙升?
下面分别来分析一下。
什么条件下需要park?
看下shouldParkAfterFailedAcquire方法的代码:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}- 如果前一个节点的状态是SIGNAL,则需要park;
- 如果
ws > 0,表示已被取消,删除状态是已取消的节点; - 其他情况,设置前继节点的状态为SIGNAL。
可见,只有在前继节点的状态是SIGNAL时,需要park。第二种情况稍后会详细介绍。
为什么要判断中断状态?
首先要知道,acquireQueued方法中获取锁的方式是死循环,判断是否中断是在parkAndCheckInterrupt方法中实现的,看下该方法的代码:
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}非常简单,阻塞当前线程,然后返回线程的中断状态并复位中断状态。
注意interrupted()方法的作用,该方法是获取线程的中断状态,并复位,也就是说,如果当前线程是中断状态,则第一次调用该方法获取的是
true,第二次则是false。而isInterrupted()方法则只是返回线程的中断状态,不执行复位操作。
如果acquireQueued执行完毕,返回中断状态,回到acquire方法中,根据返回的中断状态判断是否需要执行Thread.currentThread().interrupt()。
为什么要多做这一步呢?先判断中断状态,然后复位,如果之前线程是中断状态,再进行中断?
这里就要介绍一下park方法了。park方法是Unsafe类中的方法,与之对应的是unpark方法。简单来说,当前线程如果执行了park方法,也就是阻塞了当前线程,反之,unpark就是唤醒一个线程。
具体的说明请参考http://blog.csdn.net/hengyunabc/article/details/28126139
park与wait的作用类似,但是对中断状态的处理并不相同。如果当前线程不是中断的状态,park与wait的效果是一样的;如果一个线程是中断的状态,这时执行wait方法会报java.lang.IllegalMonitorStateException,而执行park时并不会报异常,而是直接返回。
所以,知道了这一点,就可以知道为什么要进行中断状态的复位了:
- 如果当前线程是非中断状态,则在执行park时被阻塞,这是返回中断状态是
false; - 如果当前线程是中断状态,则park方法不起作用,会立即返回,然后parkAndCheckInterrupt方法会获取中断的状态,也就是
true,并复位; - 再次执行循环的时候,由于在前一步已经把该线程的中断状态进行了复位,则再次调用park方法时会阻塞。
所以,这里判断线程中断的状态实际上是为了不让循环一直执行,要让当前线程进入阻塞的状态。想象一下,如果不这样判断,前一个线程在获取锁之后执行了很耗时的操作,那么岂不是要一直执行该死循环?这样就造成了CPU使用率飙升,这是很严重的后果。
死循环不会引起CPU使用率飙升?
上面已经说明。
cancelAcquire方法
在acquireQueued方法的finally语句块中,如果在循环的过程中出现了异常,则执行cancelAcquire方法,用于将该节点标记为取消状态。该方法代码如下:
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
if (node == null)
return;
// 设置该节点不再关联任何线程
node.thread = null;
// Skip cancelled predecessors
// 通过前继节点跳过取消状态的node
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// predNext is the apparent node to unsplice. CASes below will
// fail if not, in which case, we lost race vs another cancel
// or signal, so no further action is necessary.
// 获取过滤后的前继节点的后继节点
Node predNext = pred.next;
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
// 设置状态为取消状态
node.waitStatus = Node.CANCELLED;
/*
* If we are the tail, remove ourselves.
* 1.如果当前节点是tail:
* 尝试更新tail节点,设置tail为pred;
* 更新失败则返回,成功则设置tail的后继节点为null
*/
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
/*
* 2.如果当前节点不是head的后继节点:
* 判断当前节点的前继节点的状态是否是SIGNAL,如果不是则尝试设置前继节点的状态为SIGNAL;
* 上面两个条件如果有一个返回true,则再判断前继节点的thread是否不为空;
* 若满足以上条件,则尝试设置当前节点的前继节点的后继节点为当前节点的后继节点,也就是相当于将当前节点从队列中删除
*/
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 3.如果是head的后继节点或者状态判断或设置失败,则唤醒当前节点的后继节点
unparkSuccessor(node);
}
node.next = node; // help GC
}
}该方法中执行的过程有些复杂,首先是要获取当前节点的前继节点,如果前继节点的状态不是取消状态(即pred.waitStatus > 0),则向前遍历队列,直到遇到第一个waitStatus <= 0的节点,并把当前节点的前继节点设置为该节点,然后设置当前节点的状态为取消状态。
接下来的工作可以分为3种情况:
- 当前节点是tail;
- 当前节点不是head的后继节点(即队列的第一个节点,不包括head),也不是tail;
- 当前节点是head的后继节点。
我们依次来分析一下:
当前节点是tail
这种情况很简单,因为tail是队列的最后一个节点,如果该节点需要取消,则直接把该节点的前继节点的next指向null,也就是把当前节点移除队列。出队的过程如下:
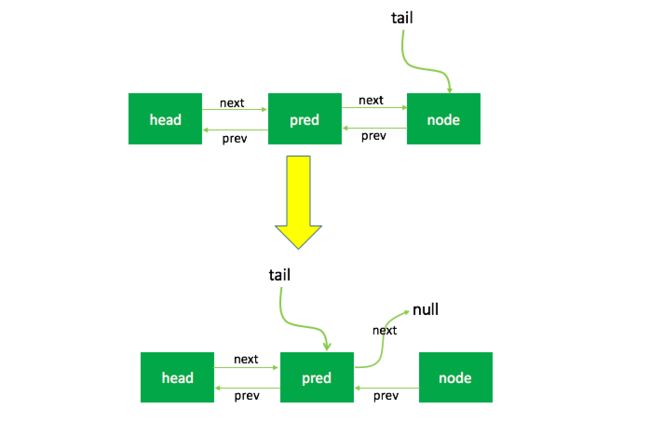
注意:经验证,这里并没有设置node的prev为null。
当前节点不是head的后继节点,也不是tail

这里将node的前继节点的next指向了node的后继节点,真正执行的代码就是如下一行:
compareAndSetNext(pred, predNext, next);
当前节点是head的后继节点
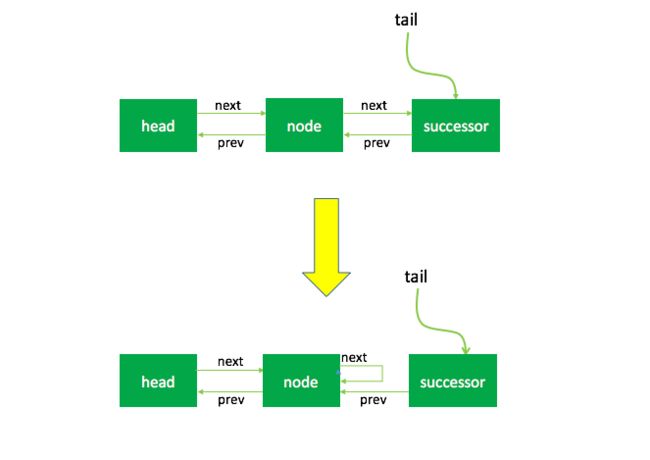
这里直接unpark后继节点的线程,然后将next指向了自己。
这里可能会有疑问,既然要删除节点,为什么都没有对prev进行操作,而仅仅是修改了next?
要明确的一点是,这里修改指针的操作都是CAS操作,在AQS中所有以compareAndSet开头的方法都是尝试更新,并不保证成功,图中所示的都是执行成功的情况。
那么在执行cancelAcquire方法时,当前节点的前继节点有可能已经执行完并移除队列了(参见setHead方法),所以在这里只能用CAS来尝试更新,而就算是尝试更新,也只能更新next,不能更新prev,因为prev是不确定的,否则有可能会导致整个队列的不完整,例如把prev指向一个已经移除队列的node。
什么时候修改prev呢?其实prev是由其他线程来修改的。回去看下shouldParkAfterFailedAcquire方法,该方法有这样一段代码:
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;该段代码的作用就是通过prev遍历到第一个不是取消状态的node,并修改prev。
这里为什么可以更新prev?因为shouldParkAfterFailedAcquire方法是在获取锁失败的情况下才能执行,因此进入该方法时,说明已经有线程获得锁了,并且在执行该方法时,当前节点之前的节点不会变化(因为只有当下一个节点获得锁的时候才会设置head),所以这里可以更新prev,而且不必用CAS来更新。
AQS释放独占锁的实现
释放通过unlock方法来实现:
public void unlock() {
sync.release(1);
}该方法调用了release方法,release是在AQS中定义的,看下release代码:
public final boolean release(int arg) {
// 尝试释放锁
if (tryRelease(arg)) {
// 释放成功后unpark后继节点的线程
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}这里首先尝试着去释放锁,成功了之后要去唤醒后继节点的线程,这样其他的线程才有机会去执行。
tryRelease代码如下:
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}是不是和tryAcquire方法类似?该方法也需要被重写,在Sync类中的代码如下:
protected final boolean tryRelease(int releases) {
// 这里是将锁的数量减1
int c = getState() - releases;
// 如果释放的线程和获取锁的线程不是同一个,抛出非法监视器状态异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
// 由于重入的关系,不是每次释放锁c都等于0,
// 直到最后一次释放锁时,才会把当前线程释放
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
// 记录锁的数量
setState(c);
return free;
}当前线程被释放之后,需要唤醒下一个节点的线程,通过unparkSuccessor方法来实现:
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}主要功能就是要唤醒下一个线程,这里s == null || s.waitStatus > 0判断后继节点是否为空或者是否是取消状态,然后从队列尾部向前遍历找到最前面的一个waitStatus小于0的节点,至于为什么从尾部开始向前遍历,回想一下cancelAcquire方法的处理过程,cancelAcquire只是设置了next的变化,没有设置prev的变化,在最后有这样一行代码:node.next = node,如果这时执行了unparkSuccessor方法,并且向后遍历的话,就成了死循环了,所以这时只有prev是稳定的。
到这里,通过ReentrantLock的lock和unlock来分析AQS独占锁的实现已经基本完成了,但ReentrantLock还有一个非公平锁NonfairSync。
其实NonfairSync和FairSync主要就是在获取锁的方式上不同,公平锁是按顺序去获取,而非公平锁是抢占式的获取,lock的时候先去尝试修改state变量,如果抢占成功,则获取到锁:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}非公平锁的tryAcquire方法调用了nonfairTryAcquire方法:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}该方法比公平锁的tryAcquire方法在第二个if判断中少了一个是否存在前继节点判断,FairSync中的tryAcquire代码中的这个if语句块如下:
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}总结
本文从ReentrantLock出发,比较完整的分析了AQS内部独占锁的实现,总体来说实现的思路很清晰,就是使用了标志位+队列的方式来处理锁的状态,包括锁的获取,锁的竞争以及锁的释放。在AQS中,state可以表示锁的数量,也可以表示其他状态,state的含义由子类去定义,自己只是提供了对state的维护。AQS通过state来实现线程对资源的访问控制,而state具体的含义要在子类中定义。
AQS在队列的维护上的实现比较复杂,尤其是节点取消时队列的维护,这里并不是通过一个线程来完成的。同时,AQS中大量的使用CAS来实现更新,这种更新能够保证状态和队列的完整性。
博客链接:http://www.ideabuffer.cn/2017/03/15/深入理解AbstractQueuedSynchronizer(一)/