Cache与内存二三事
本文搜集了几个与内存和缓存相关的技巧,对于代码调优比较有帮助。即使你在工作中不需要写出极致性能的代码,也应该读一下这篇文章。因为看似对软件工程师透明的内存以及CPU Cache,其实并不“透明”,代码的细微差别可能明显的影响缓存以及内存的性能。
1.会导致缺页中断的内存分配
下文代码采用两种方式分配pBuffer,请比对两种不同方式的耗时。
#include "stdafx.h"
#include
#include
#include
using namespace std::chrono;
const int buff_size = 32 * 1024 * 1024;
int main()
{
int * pBuffer = new int[buff_size]; //第一种分配方式
//int * pBuffer = new int[buff_size] {}; //第二种分配方式
auto start = std::chrono::system_clock::now();
for (int i = 0; i < buff_size; ++i) {
pBuffer[i] *= 3;
}
auto end = std::chrono::system_clock::now();
std::chrono::duration elapsed_seconds = end - start;
std::cout << "elapsed time: " << elapsed_seconds.count() * 1000 << "ms\n";
delete[] pBuffer;
} 在我的电脑上,第一种分配方式的运行时间大约为90ms,第二种分配方式的运行时间大约为26ms。两种分配方式唯一的区别在于后者在分配内存的时候添加了 {}。
当我们从堆里分配一个数组的时候,如果没有做任何初始化,那么操作系统只会返回一个虚拟地址映射,并不会真正地分配一块物理内存。当这个数组被访问的时候,一个缺页中断会被触发,内核才会真正分配一块物理内存。第一种分配方式在分配内存的时候,没有做初始化,所以访问内存的时候会导致大量缺页中断;第二种分配方式添加了{}强制初始化,因此在分配数组的时候内核就已经分配了物理内存。
在本例中,第一种方式(触发缺页中断)与第二种方式(初始化时分配物理内存)的时间差为64ms,这个时间差基本就是操作系统处理缺页中断并完成物理内存分配所需的时间。第一种分配方式中缺页中断耗费的时间甚至超过了业务逻辑本需要的时间,比较明显地影响了程序的性能。
说句题外话,我们分配了32X1024X1024字节的内存,而内存页的size一般为4096字节,所以一共触发了32X1024X1024/4096次缺页中断,对么?错误。虽然内存页的size一般为4096字节,但是操作系统以及硬件并不是以4096字节为单位映射内存,而是以一个略大的单位--一般是4096的2的n次幂倍(比如1MB)分配物理内存,具体细节因操作系统以及物理硬件而异。
2. 如何测量cpu cache的容量
下面这段代码可以在linux上测量缓存的容量。基本思路是,
step1:以某个步长逐一访问一块内存的存储单元,然后统计访问时间。
step2:增加步长,重复step1。
step3:最后比较相邻两次的访问时间,找到差别最大的一次,这个步长就是cache容量。
这个方法的原理是,当缓存命中的时候即使步长不相等,访问内存的时间是差不多的;当缓存没有命中的时候,因为需要重新导入内存到缓存,会导致内存访问时间大大增加。所以,若要充分利用缓存,我们最好以地址连续的方式访问内存,尽量避免缓存的内容抖动。
以下代码来自这个链接,但是我在原代码的基础上略做了简化 https://github.com/SudarsunKannan/memlatency
#include
#include
#include
#include
#include
#include
#include
#include
#define ITER 1
#define MB (1024*1024)
#define MAX_N 16*MB
#define STEPS_N 16*MB
#define KB 1024
#define CACHE_LN_SZ 64
#define START_SIZE 1*MB
#define STOP_SIZE 64*MB
#define MIN_LLC 256*KB
#define MAX_STRIDE 1024
#define INT_MIN (-2147483647 - 1)
using namespace std;
unsigned int memrefs;
volatile void* global;
void LLCCacheSizeTest()
{
double retval,prev;
struct timespec tps, tpe;
int max =INT_MIN,index = 0, maxidx = 0, iter = 0, i=0;
int diff =0, stride = 0, j = MIN_LLC;
double change_per[10];
char *array = (char *)malloc(sizeof(char) *CACHE_LN_SZ * STEPS_N);
while( j < STOP_SIZE) {
stride = j-1;
clock_gettime(CLOCK_REALTIME, &tps);
for (iter = 0; iter < ITER; iter++)
for (unsigned int i = 0; i < STEPS_N; i++) {
array[(i*CACHE_LN_SZ) & stride] *= 100;
}
clock_gettime(CLOCK_REALTIME, &tpe);
retval = ((tpe.tv_sec-tps.tv_sec)*1000000000 + tpe.tv_nsec-tps.tv_nsec)/1000;
if(index > 0){
diff = retval - prev;
if(max < diff) {
max= diff;
maxidx =j;
}
}
cout << "LLCCacheSizeTest "<< retval <<" stride "<prev->next = j->next;
j->next->prev = j->prev;
return j;
}
struct node* insert_node( struct node *i, struct node *j) {
if(!j) return NULL;
i->next->prev = j;
j->next = i->next;
j->prev = i;
i->next = j;
return i;
}
int main(int argc, char *argv[]){
LLCCacheSizeTest();
return 0;
}
下面是测试结果:
uslinux01:/home/gbuilder/jge> ./lat
LLCCacheSizeTest 102465 stride 262144 diffs: 0
LLCCacheSizeTest 71912 stride 1048576 diffs: -30553
LLCCacheSizeTest 60810 stride 2097152 diffs: -11102
LLCCacheSizeTest 60840 stride 3145728 diffs: 30
LLCCacheSizeTest 60841 stride 4194304 diffs: 1
LLCCacheSizeTest 60886 stride 5242880 diffs: 45
LLCCacheSizeTest 60978 stride 6291456 diffs: 92
LLCCacheSizeTest 60857 stride 7340032 diffs: -121
LLCCacheSizeTest 60555 stride 8388608 diffs: -302
LLCCacheSizeTest 60821 stride 9437184 diffs: 266
LLCCacheSizeTest 60825 stride 10485760 diffs: 4
LLCCacheSizeTest 60824 stride 11534336 diffs: -1
LLCCacheSizeTest 60696 stride 12582912 diffs: -128
LLCCacheSizeTest 60858 stride 13631488 diffs: 162
LLCCacheSizeTest 60696 stride 14680064 diffs: -162
LLCCacheSizeTest 60696 stride 15728640 diffs: 0
LLCCacheSizeTest 60727 stride 16777216 diffs: 31
LLCCacheSizeTest 60906 stride 17825792 diffs: 179
LLCCacheSizeTest 60819 stride 18874368 diffs: -87
LLCCacheSizeTest 60869 stride 19922944 diffs: 50
LLCCacheSizeTest 60768 stride 20971520 diffs: -101
LLCCacheSizeTest 61037 stride 22020096 diffs: 269
LLCCacheSizeTest 60756 stride 23068672 diffs: -281
LLCCacheSizeTest 60810 stride 24117248 diffs: 54
LLCCacheSizeTest 60574 stride 25165824 diffs: -236
LLCCacheSizeTest 60874 stride 26214400 diffs: 300
LLCCacheSizeTest 60880 stride 27262976 diffs: 6
LLCCacheSizeTest 60799 stride 28311552 diffs: -81
LLCCacheSizeTest 60756 stride 29360128 diffs: -43
LLCCacheSizeTest 60837 stride 30408704 diffs: 81
LLCCacheSizeTest 60794 stride 31457280 diffs: -43
LLCCacheSizeTest 60884 stride 32505856 diffs: 90
LLCCacheSizeTest 85404 stride 33554432 diffs: 24520
LLCCacheSizeTest 60930 stride 34603008 diffs: -24474
LLCCacheSizeTest 60862 stride 35651584 diffs: -68
LLCCacheSizeTest 60877 stride 36700160 diffs: 15
LLCCacheSizeTest 60832 stride 37748736 diffs: -45
LLCCacheSizeTest 60917 stride 38797312 diffs: 85
LLCCacheSizeTest 60830 stride 39845888 diffs: -87
LLCCacheSizeTest 60860 stride 40894464 diffs: 30
LLCCacheSizeTest 60588 stride 41943040 diffs: -272
LLCCacheSizeTest 60952 stride 42991616 diffs: 364
LLCCacheSizeTest 60833 stride 44040192 diffs: -119
LLCCacheSizeTest 60888 stride 45088768 diffs: 55
LLCCacheSizeTest 60759 stride 46137344 diffs: -129
LLCCacheSizeTest 60902 stride 47185920 diffs: 143
LLCCacheSizeTest 60817 stride 48234496 diffs: -85
LLCCacheSizeTest 60904 stride 49283072 diffs: 87
LLCCacheSizeTest 66884 stride 50331648 diffs: 5980
LLCCacheSizeTest 61001 stride 51380224 diffs: -5883
LLCCacheSizeTest 60925 stride 52428800 diffs: -76
LLCCacheSizeTest 60963 stride 53477376 diffs: 38
LLCCacheSizeTest 60925 stride 54525952 diffs: -38
LLCCacheSizeTest 61015 stride 55574528 diffs: 90
LLCCacheSizeTest 60996 stride 56623104 diffs: -19
LLCCacheSizeTest 61065 stride 57671680 diffs: 69
LLCCacheSizeTest 69275 stride 58720256 diffs: 8210
LLCCacheSizeTest 61172 stride 59768832 diffs: -8103
LLCCacheSizeTest 61129 stride 60817408 diffs: -43
LLCCacheSizeTest 61293 stride 61865984 diffs: 164
LLCCacheSizeTest 70822 stride 62914560 diffs: 9529
LLCCacheSizeTest 61608 stride 63963136 diffs: -9214
LLCCacheSizeTest 72650 stride 65011712 diffs: 11042
LLCCacheSizeTest 74397 stride 66060288 diffs: 1747
Effective LLC Cache Size 32 MB以下为我的linux cpu配置:
uslinux01:/home/gbuilder/jge> lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Thread(s) per core: 2
Core(s) per socket: 14
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2695 v3 @ 2.30GHz
Stepping: 2
CPU MHz: 1201.660
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4601.56
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 35840K从以上测试结果中,可以看出步长为33 554 432的时候,前后两次的访问时间差最大,因此可以确定缓存容量为32M。但是我的linux配置显示L3 cache为35840K,这是怎么回事呢?话说笔者也对此颇为费解。据笔者了解,硬件厂商统计物理缓存容量的单位可能并不是1024字节,而是1000字节。另外,L3 cache为35840K也颇为古怪,为什么Cache的容量不是2的n次幂呢?但是即使如此也不能完全解释这个问题。那也许是仅仅通过应用程序层面无法100%准确的测量缓存的容量。总之,如果读者能找到更合理的解释请让笔者知道,谢谢。
3.Cache line:
现代CPU访问某个内存地址之后会把该内存地址周边的相邻地址的内容以cache line为单位导入缓存,cache line的一般容量是64字节,也就是16个整型。以下代码可以用来验证cache line的容量。基本思路以及原理同cache容量的测试,此处不赘述。
#include "stdafx.h"
#include
#include
#include
using namespace std::chrono;
const int buff_size = 32 * 1024 * 1024;
void test_cache_hit(int * buffer, int size, int step)
{
for (int i = 0; i < size;) {
buffer[i] *= 3;
i += step;
}
}
int main()
{
int * buffer = new int[buff_size]{};
for (int i = 0; i < 16; ++i) {
int step = (int)pow(2, i);
auto start = std::chrono::system_clock::now();
test_cache_hit(buffer, buff_size, step);
auto end = std::chrono::system_clock::now();
std::chrono::duration elapsed_seconds = end - start;
std::cout << "step: " << step << ", elapsed time: " << elapsed_seconds.count() * 1000 << "ms\n";
}
delete[] buffer;
} 下面是代码的运行结果:
step: 1, elapsed time: 66.3925ms
step: 2, elapsed time: 34.1113ms
step: 4, elapsed time: 26.5611ms
step: 8, elapsed time: 27.8086ms
step: 16, elapsed time: 27.8812ms
step: 32, elapsed time: 19.7227ms
step: 64, elapsed time: 11.3431ms
step: 128, elapsed time: 4.7402ms
step: 256, elapsed time: 2.4116ms
step: 512, elapsed time: 2.0155ms
step: 1024, elapsed time: 1.7971ms
step: 2048, elapsed time: 1.1497ms
step: 4096, elapsed time: 0.5761ms
step: 8192, elapsed time: 0.2719ms
step: 16384, elapsed time: 0.1615ms
step: 32768, elapsed time: 0.1099ms
Press any key to continue . . .步长为2、4、8、16的时候耗时都差不多,这是因为cache line的容量是64字节,因此这几个步长对内存的访问量虽然大大不同,但是耗时都接近。值得注意的是,步长1和2的耗时差别相当大。我觉得cache line在这两个步长依然起作用的,只是两者的“计算消耗”耗时差别比较大,例如循环计数加法运算等等,所以1和2之间的差别可以理解为运算量的差别。
4. 多核cpu cache的false sharing问题
当我们运行多线程程序的时候,一般每个线程都会占用一个核。而对于多核cpu,每个核都有一个cache。当多个线程访问几个相邻的内存地址的时候,如果这些地址可以被映射为同一个cache line的话,那么这段size为64字节(也就是cache line的size)的内存会被导入各个cpu核的cache中。因此,各个核的cache line需要同步,这可能导致程序的运行时间大大增加。这个问题称为 false sharing。
下图展示了这种情况。
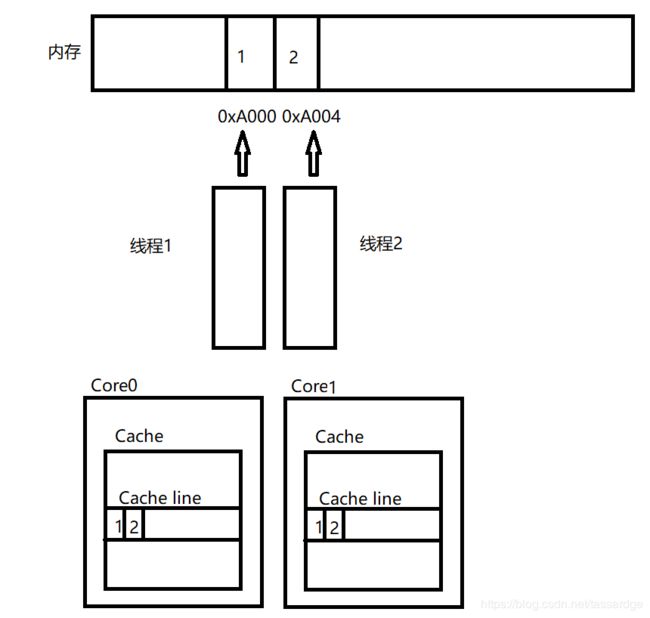
两个线程1和2分别运行在core0和core1上面,它们分别访问内存地址0xA000(保存了值为1的整数)以及0xA004(保存了值为2的整数)。因为这两个地址可以被映射为同一个cache line,所以core0和core1的cache都导入了一条包含0xA000以及0xA004的cache line。当线程1写0xA000的时候,即使线程2并没有访问0xA000,它的cache line也要做同步。而这有潜在的性能问题。
下面的代码来自这个链接: https://vorbrodt.blog/2019/02/02/cache-lines/
#include "stdafx.h"
#include
#include
#include
#include
using namespace std;
using namespace chrono;
const int CACHE_LINE_SIZE = 64;//sizeof(int);
const int SIZE = 2; //第一种方式
//const int SIZE = CACHE_LINE_SIZE / sizeof(int) + 1; //第二种方式
const int COUNT = 100'000'000;
int main(int argc, char** argv)
{
srand((unsigned int)time(NULL));
int* p = new int[SIZE];
auto proc = [](int* data) {
for (int i = 0; i < COUNT; ++i)
*data = *data + rand();
};
auto start_time = high_resolution_clock::now();
std::thread t1(proc, &p[0]);
std::thread t2(proc, &p[SIZE - 1]);
t1.join();
t2.join();
auto end_time = high_resolution_clock::now();
cout << "Duration: " << duration_cast(end_time - start_time).count() / 1000.f << " ms" << endl;
getchar();
return 1;
}
在以上的代码中,我们可以试着用两种不同的size分配内存并测量运行时间,我们发现第一种方式和第二种方式有明显的性能差别。在我的电脑上,第一种方式耗时7030ms,第二种方式耗时3369ms。
第一种方式中,两个线程同时访问两个相邻的内存地址,并且这两个地址会被映射为同一个cache line,所以这两个线程会把同一段cache line的内存导入各自的cache。当一个线程修改一个内存地址的内容的时候,另一个线程不得不同步cache line,而从测试结果来看同步操作的成本相当高。
解决这个问题的方法就是避免两个线程访问的内存地址落入同一个cache line;第二种方式增加了两个内存地址间的偏移,从而避免了false sharing的问题。
5. 一些有用的链接
intel关于false sharing的链接 https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads
Igor有一篇关于cache的好文,列举了cache相关的各种技巧,并且采用C#范例代码 http://igoro.com/archive/gallery-of-processor-cache-effects/
wiki上的cpu cache条目包含了部分关于cache line的内容 https://en.wikipedia.org/wiki/CPU_cache
下面的git里,包含一份可以测量cache line以及cache容量的工业级代码。但是基本思路还是和上文的范例一样 https://github.com/SudarsunKannan/memlatency