Python爬虫系列之----Scrapy(八)爬取豆瓣读书某个tag下的所有书籍并保存到Mysql数据库中去
一、创建项目
scrapy startproject books
二、编写Item
在items.py中编写我们需要的数据模型:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BooksItem(scrapy.Item):
book_name = scrapy.Field() #图书名
book_star = scrapy.Field() #图书评分
book_pl = scrapy.Field() #图书评论数
book_author = scrapy.Field() #图书作者
book_publish = scrapy.Field() #出版社
book_date = scrapy.Field() #出版日期
book_price = scrapy.Field() #图书价格三、编写Spider
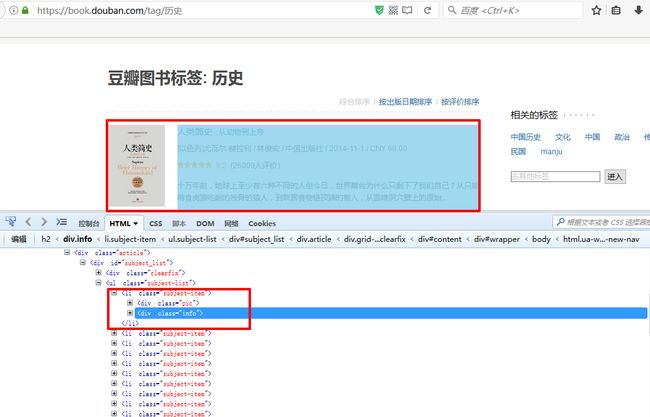
这里以历史为例,在火狐浏览器下打开Firebug查看元素,可以看见我们要提取的那些数据是在:ul[subject-list]-->li[subject-item]中:
然后创建spider文件,cd到spider目录下,执行命令:
scrapy genspider -t basic bookspider douban.com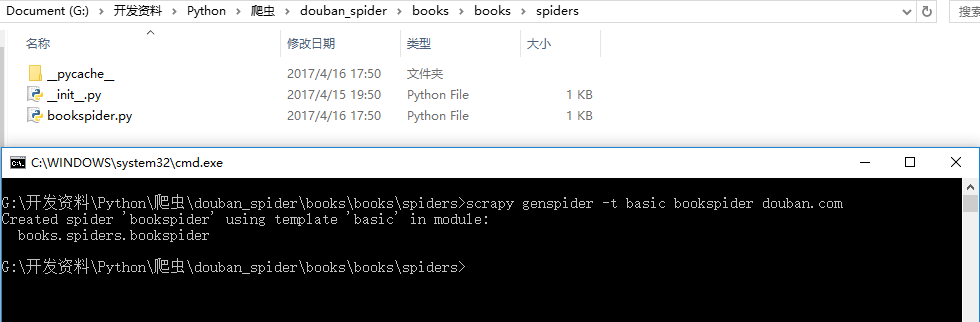
所对应的xpath语法:
先获取这个列表下的li:
sel = Selector(response)
book_list = sel.css('#subject_list > ul > li')1.图书名称:
book.xpath('div[@class="info"]/h2/a/text()').extract()[0].strip()
2.图书评分:
book.xpath("div[@class='info']/div[2]/span[@class='rating_nums']/text()").extract()[0].strip()
3.图书评论数:
book.xpath("div[@class='info']/div[2]/span[@class='pl']/text()").extract()[0].strip()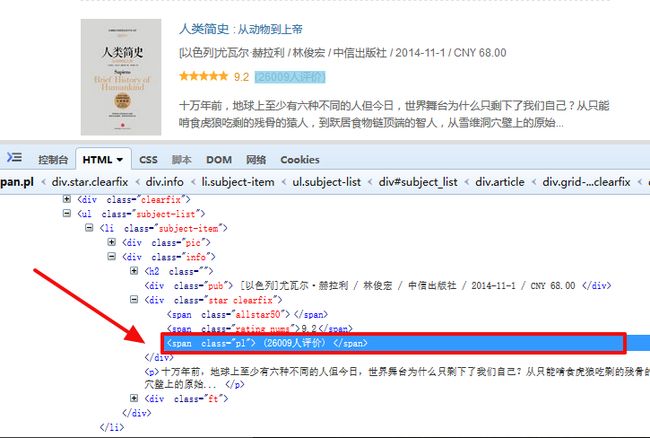
4.图书的作者,出版社,出版日期,价格:
由于他把这一些数据全部放在一起了,而且通过/进行区分,那我们可以通过split(‘/’)进行分割得到这几个数据
pub = book.xpath('div[@class="info"]/div[@class="pub"]/text()').extract()[0].strip().split('/')
item['book_price'] = pub.pop()
item['book_date'] = pub.pop()
item['book_publish'] = pub.pop()
item['book_author'] = '/'.join(pub)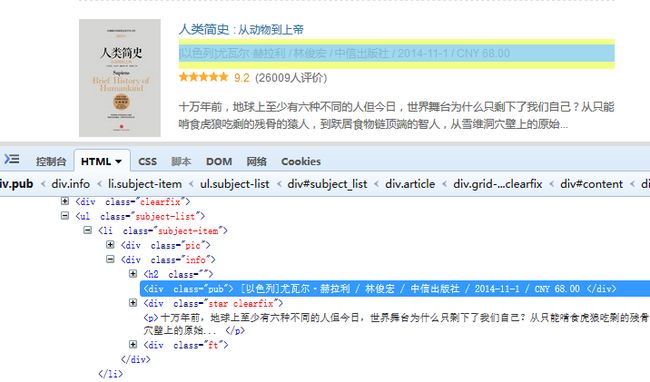
完整的代码如下:
import scrapy
from scrapy.selector import Selector
from books.items import BooksItem
class BookspiderSpider(scrapy.Spider):
name = "bookspider"
allowed_domains = ["book.douban.com"]
start_urls = ['https://book.douban.com/tag/%E5%8E%86%E5%8F%B2']
def parse(self, response):
sel = Selector(response)
book_list = sel.css('#subject_list > ul > li')
for book in book_list:
item = BooksItem()
try:
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
item['book_name'] = book.xpath('div[@class="info"]/h2/a/text()').extract()[0].strip()
item['book_star'] = book.xpath("div[@class='info']/div[2]/span[@class='rating_nums']/text()").extract()[0].strip()
item['book_pl'] = book.xpath("div[@class='info']/div[2]/span[@class='pl']/text()").extract()[0].strip()
pub = book.xpath('div[@class="info"]/div[@class="pub"]/text()').extract()[0].strip().split('/')
item['book_price'] = pub.pop()
item['book_date'] = pub.pop()
item['book_publish'] = pub.pop()
item['book_author'] = '/'.join(pub)
yield item
except:
pass然后测试一下:
scrapy crawl bookspider -o items.json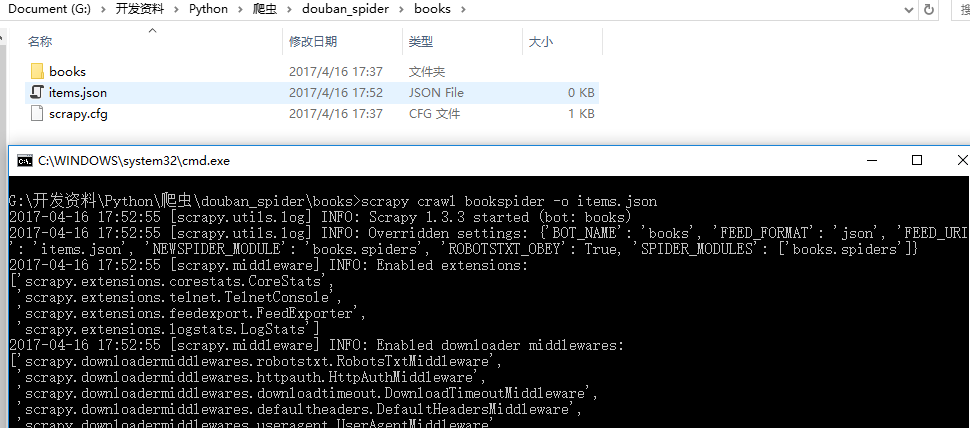
回生成一个items.json文件,查看json文件,发现items.json内并没有数据,后头看控制台中的DEBUG信息
2017-04-16 17:52:55 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6025
2017-04-16 17:52:55 [scrapy.core.engine] DEBUG: Crawled (403) (referer: None)
2017-04-16 17:52:56 [scrapy.core.engine] DEBUG: Crawled (403) 提示403,这是因为服务器判断出爬虫程序,拒绝我们访问,修改下就可以了,在settings中设定USER_AGENT的值,伪装成浏览器访问页面。
USER_AGENT = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"
再试一次,又报错:
2017-04-16 17:57:00 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6025
2017-04-16 17:57:01 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to from
2017-04-16 17:57:01 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to from
2017-04-16 17:57:01 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2017-04-16 17:57:01 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to from
2017-04-16 17:57:01 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2017-04-16 17:57:01 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to 301错误。。看到其中提示robots.txt。然后把settings中的ROBOTSTXT_OBEY = False设置为"False",运行还是提示301。。最后发现网站写错了。。
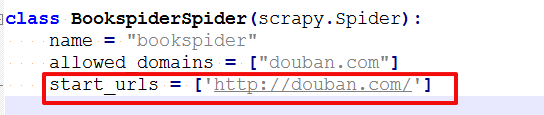
把它改成:

再运行就发现items.json有值了

但仔细只有第一页的数据,如果我们想要爬取所有的数据,就需要爬完当前页后自动获得下一页的url,以此类推爬完所有数据。
获取下一页:
sel.xpath('//div[@id="subject_list"]/div[@class="paginator"]/span[@class="next"]/a/@href').extract()[0].strip()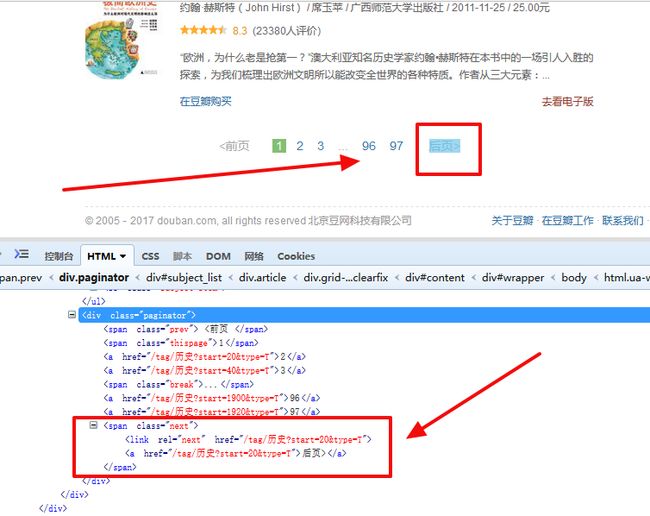
修改spider成如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.selector import Selector
from books.items import BooksItem
class BookspiderSpider(scrapy.Spider):
name = "bookspider"
allowed_domains = ["book.douban.com"]
start_urls = ['https://book.douban.com/tag/%E5%8E%86%E5%8F%B2']
def parse(self, response):
sel = Selector(response)
book_list = sel.css('#subject_list > ul > li')
for book in book_list:
item = BooksItem()
try:
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
item['book_name'] = book.xpath('div[@class="info"]/h2/a/text()').extract()[0].strip()
item['book_star'] = book.xpath("div[@class='info']/div[2]/span[@class='rating_nums']/text()").extract()[0].strip()
item['book_pl'] = book.xpath("div[@class='info']/div[2]/span[@class='pl']/text()").extract()[0].strip()
pub = book.xpath('div[@class="info"]/div[@class="pub"]/text()').extract()[0].strip().split('/')
item['book_price'] = pub.pop()
item['book_date'] = pub.pop()
item['book_publish'] = pub.pop()
item['book_author'] = '/'.join(pub)
yield item
except:
pass
#
nextPage = sel.xpath('//div[@id="subject_list"]/div[@class="paginator"]/span[@class="next"]/a/@href').extract()[0].strip()
if nextPage:
next_url = 'https://book.douban.com'+nextPage
yield scrapy.http.Request(next_url,callback=self.parse)四、突破反爬虫
有时候我们在使用的过程中,会出现一些意外的现象,就是爬虫爬取得快,或者其他一些原因导致,网站拒绝访问,或拉黑IP等,所以我们要突破反爬虫:
可以做在settings设置爬虫的间隔时间,并关掉COOKIES
DOWNLOAD_DELAY = 2
COOKIES_ENABLED = False或者,可以设置不同的浏览器UA或者IP地址来回避网站的屏蔽
下面使用User-Agent来演示:
在middlewares.py,编写一个随机替换User-Agent的中间件,每个request都会经过middleware,其中process_request,返回None,Scrapy将继续到其他的middleware进行处理。
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
import random
class BooksSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class RandomUserAgent(object):
"""根据预定义的列表随机更换用户代理"""
def __init__(self,agents):
self.agents = agents
@classmethod
def from_crawler(cls,crawler):
return cls(crawler.settings.getlist('USER_AGENTS'))
def process_request(self,request,spider):
request.headers.setdefault('User-Agent',random.choice(self.agents)) 在settings中配置下:
DOWNLOADER_MIDDLEWARES = {
'books.middlewares.RandomUserAgent': 1,
}
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
加入之后在运行爬虫看下效果,他就能自动的一页一页的往下获取数据。
五、保存到Mysql数据库
我们想把获取的数据持久化到数据库中去,这里采用mysql数据库,数据存储这一块写在pipelines类中,在操作数据库之前先要安装数据库驱动模块:
pip install pymysql安装好之后修改pipelines文件:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql as db
class BooksPipeline(object):
def __init__(self):
self.con=db.connect(user="root",passwd="123",host="localhost",db="python",charset="utf8")
self.cur=self.con.cursor()
self.cur.execute('drop table douban_books')
self.cur.execute("create table douban_books(id int auto_increment primary key,book_name varchar(200),book_star varchar(244),book_pl varchar(244),book_author varchar(200),book_publish varchar(200),book_date varchar(200),book_price varchar(200))")
def process_item(self, item, spider):
self.cur.execute("insert into douban_books(id,book_name,book_star,book_pl,book_author,book_publish,book_date,book_price) values(NULL,%s,%s,%s,%s,%s,%s,%s)",(item['book_name'],item['book_star'],item['book_pl'],item['book_author'],item['book_publish'],item['book_date'],item['book_price']))
self.con.commit()
return item
修改settings文件:
ITEM_PIPELINES = {
'books.pipelines.BooksPipeline': 300,
}然后运行爬虫:
scrapy crawl bookspider马上数据库里就有数据了
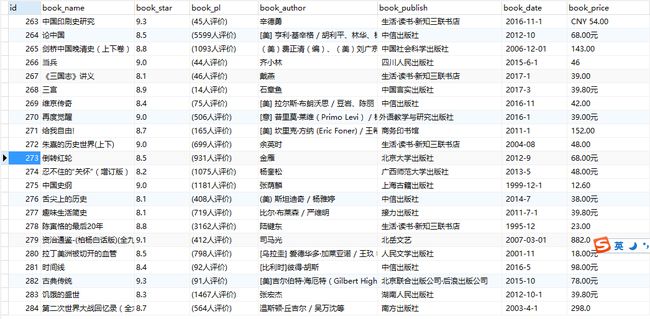
示例代码: http://download.csdn.net/detail/u011781521/9815993 此爬虫虽然爬取了图书名,作者,评分,评论数,出版社,单价,但是并没有爬取书籍的图书与图书的简介。。下一步要做的就是这一块。。