天池-OppO-OGeek比赛总结
赛题资源
题目链接
数据链接
我的代码
这份代码是复赛的代码,写的比较规范些,也添加了一些注释。因为实在阿里云的平台上运行的,所有有些地方会报错,不能直接运行。最主要的问题应该是输入数据的路径不对,改成对应的路径即可。
赛题描述及分析
在搜索业务下有一个场景叫实时搜索(Instance Search),就是在用户不断输入过程中,实时返回查询结果。赛题的数据如下:
| 字段 | 说明 | 数据示例 |
| prefix | 用户输入(query前缀) | 刘德 |
| query_prediction | 根据当前前缀,预测的用户完整需求查询词,最多10条;预测的查询词可能是前缀本身,数字为统计概率 | {“刘德华”: “0.5”, “刘德华的歌”: “0.3”, …} |
| title | 文章标题 | 刘德华 |
| tag | 文章内容标签 | 百科 |
| label | 是否点击 | 0或1 |
比如用户当前输入为刘德华,系统后台会根据自己获得到的数据来得到一个query,query中的每一项的具体含义题目中也没有具体说明,选手们的猜测大概是这样一个意思,当输入“刘德”时,用户有0.5的概率是想输入“刘德华”,0.3的概率是想输入“刘德华的歌”,等等。而title、tag则是系统推荐给用户的一个“标题”,tag则是这个标题对于的标签,比如百科、应用、音乐、网站等等。label则是我们需要预测的值,判断用户在这个情况下是否会点击这个标签。
分析数据的时候发现,title未必在query_predicti中,甚至prefix不是title的前缀,看起来好像不太合理,但是仔细一想,这可能是潜在的一个重要特征?
本次竞赛的评价标准采用F1 score 指标,正样本为1。
特征工程
特征工程主要还是脑洞大开,充分挖掘自己的脑细胞,想出各种特征,不要怀疑是否有用。我的脑洞特征有这么几个:
1、转化率特征。对prefix,title,tag特征计算单个特征的浏览量、点击量和点击率,同理到两两组合,三个一起组合的情况。拿上面“刘德”的例子就是,对于单个特征比如prefix,得到“刘德”的浏览量为20,点击量为5,那么点击率为0.25,同理可能计算得到prefix为“oppo”的浏览量、点击量、点击率分别为10,1,0.1。对于两个组合也是一样的道理,比如prefix为"刘德",title为“刘德华”的情况浏览量、点击量、点击率分别为10,5,0.2,。值得注意的是,为了防止出现浏览量非常少的情况,可以用点击量/(浏览量+10)的方法来平滑一下。
这种特征相当于是对训练集的记忆,容易产生过拟合。
2、其他一些比较简单,显而易见的特征有:prefix是否在title中,prefix和title字符串的长度(用户只输入一个字符与输入5,6个字符推荐出来的结果可能会影响点击),query候选词的数量,当前的title是否在query候选词中以及对应的概率,如果不在的话返回0。
3、和莱温斯坦距离,即编辑距离相关的特征。prefix和title的编辑距离,如果编辑距离越小甚至为0,可能点击的概率较大,为了消除字符串本身长度带来的影响,可以在生成一个编剧距离/maxlen(prefix,title)的特征。同理还可以推广到query和title中,加入query中很多候选词或者某个候选词和title的编辑距离很小,被点击的概率可能很大。但是query有很多候选词的,有些query甚至没有候选词。我做了这样一些特征,计算title和每一个query中候选词的编辑距离,然后得到这些编辑距离的最小值、平均值以及加权值,这里的加权值是和候选词对应的概率做加权。
4、最长公共子串相关的特征(这个特征和编辑距离有点相似)。计算得到prefix和title的之间的最长公共子串的长度,为了消除字符串长度的影响,可以再像编辑距离特征一样,除于最大字符串的长度。对于query和title,则对title和query中的每一个候选词计算最长公共子串的长度的占比,然后得到这个比率的最大值、平均值和加权值。
5、和词向量相关的特征。词向量可以从网上其他地方下载得到,也可以使用本次比赛提供的数据训练得到,主要对query中的候选词作为语料源,因为这里的字符串比较长,另外从题目本身训练得到的词向量相对来说也比较准确。词向量的训练可以直接运行w2v.py代码。由于prefix、title、query_prediction里面都是一些短语,首先需要对它进行分词操作,得到所有分词的词向量,然后对所有的词向量求平均值作为这个短语的向量。这样可以计算得到query和title之间词向量的相似度,同时可以对query中每一个候选词和title的词向量的相似度,并求的这些相似度的最大值、平均值和加权值。
6、预测用户真正想输入的orefix,比如用户输入‘刘德’,我们有很大的概率可以判断用户想输入的其实是‘刘德华’。预测用户真正想输入的词汇可以借助于query中的词汇,比如query中出现大量的“刘德华”,我们可以判定用户真正想输入的词汇就是“刘德华”。可以对query中所有的候选词,统计出出现次数过半的最长字符串作为当前的prefix。
7、对生成的特征做一个均值填充,对所有的特征取log做为新的特征。
模型
在实验中,尝试过LGB、XGB、RF、GBDT+LR等模型,以及模型融合的结果,发现最好的还是LGB5折的效果最佳,当然也有可能是模型参数调试的不好导致融合效果不如单模型。由于对prefix、title、tag这3列数据group后的特征作用不大,且容易引起过拟合,因此训练的时候去掉了,下面是LGB训练后特征的重要度
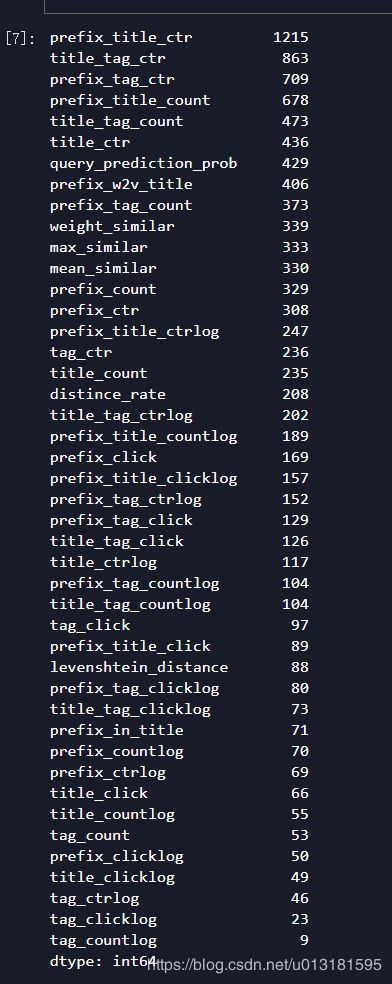
发现,最重要还是点击率、点击量等特征,而编辑距离特征、词向量特征作用有限。
总结反思
特征方面大部分人的都差不多,上面这些特征也是大家都能想到的,到后面实在想不出什么好的特征了。而模型方面真的是脑洞有限。依然停留在各种树模型LGB、XGB的阶段,无法想出比较耳目一新,非常管用的模型,只能参数乱试一通。最终成绩初赛86/2888,复赛成绩57/2888,F1值为0.7244。要冲进前20名真的是好难啊,如果有想交流的欢饮联系
决赛学习
决赛答辩还没有开始,到时候学习一下前排的大佬究竟使用的是什么特征,什么模型。